主要内容:20240602
当下有两个非常重要的技术,加速运算和人工智能,都是刚才演示在Omniverse 中运行的。这两个技术会重新打造整个电脑产业。
电脑产业已经 60 岁了,我们现在所享受的其实是我出生 1964 年之后的那一年才开始的。2007 年的 iPhone 它让移动的运算电脑放到我们的口袋里头,之后一切都连接在一起了,大家都通过移动的云端可以把所有的装置连接在一起。其实过去这 60 年电脑这个产业里大概就两三个重大的科技转变,现在我们即将要见证下一个重大的改变
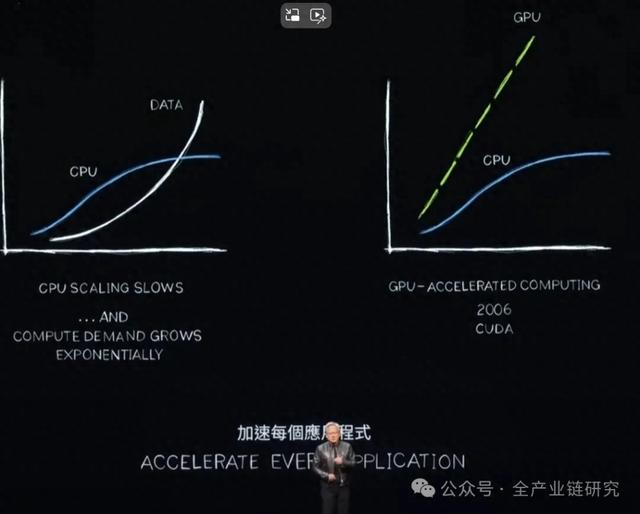
有两个重要的事情在改变,第一个就是处理器的效能扩充的速度大幅降低,但是我们所要做的运算却成长非常的快,所需要处理的数据不断地增加,所使用的电力也非常的多,而这个运算的成本也增加。过去 20 年我们都在开发加速运算cuda,现在CPU 性能提升放缓的时候,我预测所有的应用程序只要它需要大量处理,就必须要被加速。我们看一个应用程序,有100T就是说它有 100 个时间单位,可能是 100 秒、 100 个小时,在很多情况之下,你要去开发一个人工智能的程序可能要 100 天,那这个 1T 呢?这个程序可能是需要所谓的序列处理,而这个 CPU 它当然就很重要,它包括了控制逻辑等,它就是一个一个指示下去,但是有很多的这个运算,比如说动画,图像处理,物理模拟、合并优化或者深度学习的线性代数它都可以透过平行处理来加速,所以我们就发明了一个架构来让GPU做这种平行运算,可能以前是要花 100 个单位才能够完成的时间,现在可能只需要一个单位,而且好处非常非常的多,如果加速 100 倍,但是它所需要的能耗可能不多,你增加所需要的电力可能只有三倍,而成本可能只增加了50%。
我们在电脑产业常能看到这样的一个进步,例如说 GPU 可能是 500 块 ,加在这个 1, 000 块的个人电脑上,然后它的效能大幅的增加,数据中心也是一样,可能花 10 亿美元打造的,加入投资5亿元的GPU,现在还都变成了一个 AI 工厂。我们省下来的钱非常多,每一美元它的效能增加了 60 倍,而电力只多花了 3 倍,速度快了 100 倍,成本才增加了 1.5 倍。这就是为什么大家可能跟我说过,你买越多就省越多。这个算式当然不是非常的精准

要加速运算其实没那么容易,为什么可以省这么多钱但是大家却没有这么做呢?因为它是一个非常困难的技术,并没有所谓的一套软件,你可以来拿来编译,然后突然之间这个应用程序它就可以快 100 倍。我们必须要重写这个程序,这是最难的地方,要重新想办法去表达原来在 CPU 上面的运算,然后我们才能够把它从 CPU 卸载,然后把它放在 GPU 上面来平行的计算。过去这 20 年来我们很努力的想要改变这个问题,积累了很多宝贵的函数库:

CUDNN是我们深度学习的函数库,我们还有另外一个还是会叫做Arial Ran,它是一个 cuda 加速的 5G 的一个无线电,让我们可以去加速通讯的网络。这个是软件定义的网络,所以我们要能够把这个加速,就让我们可以把所有的电信的变成是我们一个演算的平台,像是这个云端的演算平台一样。
cuLITHO 它是一个计算光刻平台,它可以让我们去做芯片制造里头最复杂的地方,那台积电它们就使用cuLITHO,可以省很多钱。但是台积电主要的目的是要去加速它们的堆叠,更做窄的芯片。
Parabricks 一个基因测序的函数库, cuOpt它是可以做合并优化的函数库。cuQuantum是一个量子计算的模拟器,cudf 是一个非常厉害的数据处理函数库,现在很多公司可能使用 Spark 或者是pandas,还有一个新的叫Polars,还有很多其他的处理函数库
这些专门的函数库是我们公司的宝藏,我们有350个函数库, 我们才能开拓这么多新的市场。
上个礼拜 Google 已经宣布了他们把cudf放在他们的云端系统,让他们 Pandas 云端速度更快。Panda s可以说是现在大家最喜欢用的数据处理函数库,现在在你只要点一个键,就可以在Google 云的Colab平台 里面来使用Pandas,而且是透过 cudf来进行加速处理,我们来看一下它有什么样的效果:
现在产业的发展来到一个转折点,它有一个良性的循环,这是很难得的。CPU处理器到现在已经有 60 年时间,基本上没有太大的改变。加速运算等于是一种新的平台,要打造新的平台生态非常的困难,假如没有开发人员使用你的平台,就不会有任何用户,如果没有用户的话,开发人员就不会有兴趣
我们已经累计了 20 年,开发了各种领域的函数库,现在在世界各地有 500 万名的开发人员,可以服务各个不同的产业,包括金融业,健康护理、电脑产业、交通艺术产业所有主要的科学领域都在用我们的这产品,我们的架构可以让云端系统的开发人员来使用,譬如说台湾有很多系统厂商也都对我们的产品很有兴趣。
这也意味着我们现在有很好的机会,让我们能够不断地扩充我们的研发规模,让应用程序开发速度更快。每一次加速,我们就能够开发更多应用程序,运算成本就会降低,之前给大家看到的一个良性循环,速度提高的 100 倍,就可以让我们节省97%、 98% 的成本。假如这个速度是 200 倍、一千倍的话,开发的成本会降更低。
cuda已经有了这样的一个良性循环,使用的人非常的多,成本下降幅度非常的可观,就会有更多开发人员提出新的想法,这样子就可以驱动更多市场需求,因此现在已经展开了新的电脑时代。

我们现在可以打造地球的数位孪生,预测我们的地球未来会有什么样的变化,了解气候变迁对于我们生活环境的影响,
想象一个我们能够预测未来的世界。数位孪生是一种反映真实世界的虚拟模型,让我们能够从今天的行为来预测对未来世界的影响。介绍一下 Nvidia earth 2 ,一个利用 AI 物理模拟和电脑图形技术来预测全球气候的数位孪生。
Corrdiff是 Nvidia 的生成式 AI 模型,它在 WRF 数值模拟的基础上训练而成,能够以 12 倍更高的解析度生成飞器模式从 25 公里提高到 2 公里。这代表了区域天气预测的一个巨大飞跃。Corrdiff比传统的物理模拟方法 1, 000 倍,且能效比高 3, 000 倍,台湾的气象局使用这些模型来更精确地台风登陆点。并考虑到城市基础设施的影响,它能模拟建筑物周围的气流。
在不久的将来,我们可以随时掌气候变化,而且它不需要消耗太多的电力。
刚才的内容是jetson AI,也就是我的数位孪生帮我做旁白的。


AI 的研究人员他们在 2012 年发现cuda是非常好用的,这是 Nvidia 第一次接触到人工智能,我们知道这个科技可以不断地扩充,这是几十年前的算法,因为我们现在有了这么多的数据,这么大的网络,有更好的运算能力,突然之间深度学习变为可能。假如我们要把这样的架构进一步的扩充,有更多的数据,更大的网络,有更好的运算能力,它的前途是不可限量的,所以我们要不断突破,在 2012 年之后,我们有了NVLink,, Tensor core 等进展
我们把所有这些东西整合在新电脑里面,过去大家没有办法想象,也不会有人买。我们在 GTC 发布,那时旧金山的小公司OpenAI 看上了我们的原型产品,我们就把全世界第一台 DGX 超级电脑亲手在 2016 年交给了OpenAI,我们不断地扩充它的规模,我们把它的规模越做越大。
到了 2017 年,我们有了 Transformer ,可以用大量数据来做训练,进行自然语言的处理,这也是一个很大的突破。2022 年 11 月,OpenAI发布的ChatGPt短短 5 天时间有一百万人在使用,因为使用起来非常简便,而且效果非常的好,能把电脑当成人一样跟他们进行互动。

ChatGPT 还没有跟大家见面之前,所谓的人工智能都是要如何理解自然语言电脑视觉语音的识别,ChatGPT 是我们第一次看到有生成式的人工智能系统出现,它可以产生我们所谓的token,它可能是文字、影像,表格、歌曲、演讲,token有可能是任何的事情,刚才的earth 2产生的是天气的token,我们也可以教 AI 模型物理学,譬如说可以用token来表示汽车方向盘的控制,机械手的控制。
现在已经进入了生成式 AI 时代。我们现在有一种新形态的工厂,所产生的是一种新的有价值的大宗商品。在 1980 年代末期 Tesla 发明了交流发电机,他产生的是电子,我们现在产生的是token,电子也好,token也好,它都有很高的市场价值,因为每个产业都需要,而且他可以扩展的。因此你们有注意到,现在每天都有一些新的生成式的 AI 模型被打造出来,因为每个产业都需要。

从加速运算到AI,到生成式AI,现在是新的产业革命。但是其实这个对于我们自己的产业影响也很大,因为 60 年来刚才有提到运算方式都在改变,从 CPU 通用目的的运算到加速的 GPU 运算,以前电脑需要指示命令,现在它可以去处理大语言模型,过去模型是存取式的,举例来说你要打电话,那可能你听到它有这个预录的内容,它根据一个推荐系统来推荐给你。但是未来你的电脑它会生成很多东西,但是它只会存取你所需要的东西,因为生成式的数据它要存取资讯的时候所需要的能源比较少,它也会更符合你的需求。所以你如果要什么样子的资讯,你只需要问电脑就行,那未来你的电脑就不再只是我们所使用的工具了,它甚至能够生成新的技能,它会帮你做一些工作,所以未来这个产业它不再只是去设计程序,当然在 90 年代这个是非常了不起,别忘记当时的微软,他们的软件可以说是改变了整个电脑产业,因为如果没有有这些套装软件的话,我们电脑能拿来做什么呢?
现在我们有新的工厂、新的电脑,那也会有新的软件,我们就把它叫做NIM(nvidia inference microservice), 它是在这个工厂里头运行的,这个NIM它是一个预训练的模型,它是一个AI,这个 a i 本身就非常的复杂杂。你去使用ChatGPT,它底下有非常多软件,你下一个指令背后其实有非常多的软件在跑,上亿的参数在跑,它需要做各式各样的平行运算,在不同的 GPU 帧分配作业负载,如果我们今天要经营工厂的话,收入跟有多少人可以使用你的服务有非常正向的关系。
我们现在的数据中心它的传输量非常非常的大,所以传输率就很重要了。因为现在它变成是一座工厂,它的运行就会跟财务表现有很正关系。以前也很重要,但是大家不会去测量,现在每一个参数都必须要测量起始时间、使用时间、利用率、空闲时间等等。我们知道对大部分的公司来说这都是非常复杂的事情,所以我们就去把AI 装进了一个盒子里头,这些容器有非常多很棒的软件。有cuda、cuDNN、TensorRT、Triton推理服务,除此之外,也有各式各样的管理服务,还有 HOOKS 配置,让大家监督自己的AI,它有通用的标准的API,只要你的电脑上有cuda,每一朵云上都有,数亿台电脑上面都有,大家把它下载之后可以和chatgpt一样对话。我们测试的NIMS每一个都是预训练的模型,它们都是可以安装的,在各种云上面,NIMS这个微服务真的是很棒的一个发明,大家也知道我们现在可以创造各式各样的大型的模型,预先训练模型质量不同的版本,不管它是视觉或者是图片版本为主,或者是说针对不同产业,我们还有是所谓的这个数位人,可以请大家上 AI.nvidia.com 去看一下,我们才贴了 hugging face 这个 llama3 NIMS,它是是免费的,大家可以在云上面来运行,也可以下载容器放在自己的数据中心里使用。
刚才提到各个不同的领域,我们使用的方式就是把这些微服务,把它连到大型的应用程序,其中最重要的一个应用就是所谓的客服专员。客服专员在各种产业中都很重要,比如护理师、药师他们也可以认为是客服,在保险业零售业餐饮业金融业都需要客服人员。这一些大家看到的容器,其实它都是能够推理的,它能够知道你要它做什么,它知道工作是什么,任务是什么,把它拆解之后做规划, 有一些NIMS它甚至可以进行搜寻,可以使用工具,举例有一些他认为服务,他可能要做 SQL 的这个查询,所以这些不同的nims可能是各自的专家,现在这些应用程序它基本上就好像是组成一个团队一样,组成了一个 AI 团队。大部分人都不会写程序,但是大家都知道看到一个问题怎么样把它拆解?我相信未来所有的公司,它们都会有很多的这个NIMS,大家可以按照自己的需求叫出所需要的专家,打造专家团队,你甚至都不需要怎么样子把它们连接在一起,只需要把这个任务交给一个这个代理,让 NIM去搞清楚到底这个任务它的各个环节是什么,要交给谁去处理,他可以拆解这些工作交给各个成员,各个成员完成了他们的工作之后把他汇整起来,然后把最后的解决方案提供给你,就像是一个人类的团队一样。这是未来应用的样子。

我们也可以跟这些大型的 AI 服务互动,可以用文字或者是语音的这个提示来互动,有很多的应用程序我们可能想用比较像是人的方式来互动,Nvidia 已经在数字人技术上面研究了很久了,当然我们也必须要跨越这个巨大的鸿沟,就是现实感,这些数字人他要能够有温暖的感觉,有同理心。
生成式 AI 和计算机图形学的新突破让数字人类能够以类似人类的方式看见、理解和与我们互动。数字人的基础是建立在LLM模型上的AI模型。这些 AI 连接到另一个生成式 AI,以动态地动画化一个逼真的 3D 面部网格。

NVIDIA ACE是一套数字人技术,被包装为易于部署的微服务nims,开发者可以将ACE NIMS整合到他们现有的框架、引擎和数字人体验中。nemetron slm和 llm nims用于理解我们的需求并协调其他引擎,riva 语音nim用于语音交互,面部和手势nims用来产生动作,omniverse RTX和 dlss用于皮肤和头发渲染。ACE在nvidia GDN上云端运行,也可以在个人电脑上面运行。
我们知道为了要能够创造一个新的运算平台,我们先必须要把这个基础打好,那么之后就会有应用,如果没有这个基础的平台,后面就没有应用。所以我们所有的 RTX GPU 它都有tensor core Processing,我们现在也出了 200 多款AI PC,那未来大家的个人电脑就会是一个AI,会提供大家各式各样的协助。个人电脑它当然也会去跑 AI 加强的应用,图片编辑、写作的时候,各式各样的工具它都会能够因为 AI 而强化,也会有数字人在里头,换句话说 AI 会用不同的方式体现在大家的个人电脑里头,

未来会怎么样的发展呢?我前面有提数据中心的扩充,每一次我们要扩充的时候,我们就发现有一个新的改变,我们从 DGX 变成大型的 AI 超级电脑的时候,我们让 Transformer 可以训练大量的数据集,在一开始的时候数据是由人类监督的,换句话说我们需要有人类给它进行这个贴标签, Transformer 就让我们得以进行非监督式的学习。现在 transformer 他要看很多很多的数据从中去学习,他可以找到其中的一些相关的模式,未来 AI 它必须要符合物理定律才行。未来如果我们的 3D 绘图要符合物理,那我们的 AI 它必须要了解物理的定律,当然也可以从这个去看这个影片来学习,另一个方式是模拟,还有一个方式就是电脑彼此之间互相学习,这个就有点像是Alphago,它跟自己对答一样,大家未来会看到这一类的 AI 不断的出现。如果数据是合成生成的,然后使用强化学习,那么数据生成的速度就会增加,所需要的运算能力当然也就必须要增加。AI 之后会更了解物理定律,它一切的生成都会基于物理定律,未来的模型只会越来越厉害,需要更大的GPU。
Blackwell 是为了这样的新时代而发明的,其中光是这个晶片的大小就是一个很大的成就,它每秒是 10TB 的连接,然后我们把这两个GPU放在一个电脑的节点上。用Grace CPU 在一起,Grace CPU 可以做很多事情,在训练的时候可以做这个快速的检查点,然后重新启动。推理的时候它可以用来存储的这个情境的记忆,这是我们第二代的 Transformer 的引擎,让我们可以去动态地去适应更低的精度,根据我们所需要的精度、需要的范围来调整。这是第二代具有安全 AI 的 GPU,保护 AI 免受盗窃或篡改。我们第五代的nvlink让我们可以把多个GPU去连接,
我们有非常非常多的伙伴,不管是OEM、电脑制造商、CSP、GPU,甚至是电信公司,各式各样的企业,都站在我们的背后。他们对于 Blackwell 的支持程度我真的感激,我们也不停下自己的脚步,在我们希望可以持续地强化效能,持续地降低训练和推理的成本、持续地扩充 AI 的能力,让所有的公司都能够拥有AI

们现在推出Blackwell 的平台基本理念就是说我们要建立整个数据中心,把它汇总在一起,然后分拆给大家。每一个平台大家都会看到你有CPU、有GPU、nvlink,还有交换器等等,我们打造一整个平台,把整个平台整合成一个 AI 工厂的超级电脑,然后我们再把它分散让全世界都可以使用。因为在座你们都有能力去创造非常有趣、非常有创意的配置,可以用不同的风格、不同的数据,不同的顾客,在不同的地方,不同的边缘应用,所以我们尽量让他有弹性,让大家可以用最有创意的方式来进行构建。
我们的节奏是一年一次,所以不管台积电的制程技术,不管封装的技术可以把它推到什么样子的极限,或者光学的技术可以推到什么程度?反正他们推到什么程度,我们就会让我们所有的软件都可以在这整个架构上运行。软件惯性是很重要的,所以最重要的是可以向后兼容的话是最好的
blackwell现在已经推出了,明年是 blackwell ultra。我们之前有H100、H200,那因此大家未来会看到新的下一代 blackwell一定要去推到极限,还有下一代的 Spectrum 交换机。我们下一个平台叫做Rubin,我不会花太多时间讲,因为我知大家一定会拍照,然后会去想办法去看它里头的这个细节,这个 Rubin 的平台一年之后我们会有Ruben ultra,现在给大家看的芯片都是已经在开发中的了,都是一年推出一次的节奏。

我接下来要讲我们未来的发展,我想新一波的 AI 就是所谓的符合物理定律的AI,它可以在我们的生活协助我们,因此 AI 必须要了解这个世界,让他们可以知道怎么样子去感知这个世界。当然这个 AI 也有非常好的认知能力,让他们了解我们,让 AI 能够了解我们到底在为什么样的问题,帮我们做什么样子的事情,
未来机器人会是越来越普遍的一个概念,包括人形机器人还有未来工厂会有很多的机器人,会制造各式各样的机器,然后可以去制造机器人。机器人的时代已经到来。有一天,一切可以移动的东西都是自主的,世界各地的研究机构都在研究物理AI驱动的机器人,物理AI是可以让理解指令的模型,可以自主完成复杂任务。多模态大语言模型是突破性的,使机器人能够学习、感知和理解周围的世界以及计划行动,通过人类示范,机器人可以学习所需的技能。一个推动机器人发展的关键技术是强化学习,正如LLM需要RLHF进行强化学习以学习特定技能一样,生成性的物理AI也可以通过在模拟世界中从物理反馈中进行强化学习来学习技能。
Omniverse 是一个虚拟世界模拟开发平台,结合了实时物理渲染、物理模拟和生成式AI技术。在Omniverse 中,机器人学习如何成为机器人。它们学习如何自主精确地操控物体,比如抓取和处理物体,或自主导航环境,找到最佳路径,同时避免障碍和危险。在 Omniverse 中学习最大限度地减少模拟与现实的差距,并最大限度地转移所学行为。

我们未来服务市场的方式有很多种,第一个是针对不同的机器人系统来打造平台,一个是工厂和仓库的机器人,一个是能够操作物体的机器人,第三个是移动的机器人,第四个则是人形机器人,每一个不同的机器人平台会有加速库,还有预训练的模型,把它整合在 omniverse 里头, omniverse里机器人学习怎么成为机器人。当然整个生态会非常的复杂,因为它需要很多的公司,很多工具、很多的技术才能够让我们打造一个现代的仓库,未来机器人会越来越能够自主。那么在这些不同的生态机器人会有SDK,也会有API,把他连接到各式各样的软件,还有连接到边缘 AI 的产业,有一些公司他们则是去设计PLC,然后会有整合商把它整合在一起
接下来谈一谈工厂,未来工厂会是完全不一样的生态,鸿海在打造世界上最先进的工厂,包括了边缘运算、机器人,还有设计工厂的软件,各式各样的工作流程,还有 LC 电脑,还有机器人的编程,这些全部都会把它整合在一起,这些 SDK 都会跟这些生态体系、生态性连结在一起,那这个全部都在台湾发生,鸿海正在打造他们工厂的数位孪生模型,台达也在打造自己数位工厂的数位孪生模型,伟创也在打造他们的数位孪生模型

有两种机器人,它市场是非常大的,一种是自动驾驶车,我们有完整系列的产品,明年 梅赛德斯奔驰会使用我们的系统, 2026 年还有另外一家汽车公司也会使用我们的系统,不论我们开发的是哪一个层级的产品,我们都会做到最好。

而接下来最大的机器人的市场是跟制造业有关,在制造业的工厂当中有很多的机器人,大部分是人形机器人,其实近年来这个方面已经有很大的进步,因为有了基础模型,有更好的感知能力。其实人形机器人是最使用起来最简便的一种机器人,我们可以有大量数据来训练这些机器人,因为他们的外形是跟我们一样的,后这样的人形机器人他们会有非常好的感知跟操作。我想接下来我们要欢迎一些机器人进场了。

机器人的时代已来了,未来是属于人工智能的时代,台湾过去生产有键盘的电脑,是以后的电脑它会走,会晃来晃去的,这些其实都是电脑。其实他们里头用到的科技跟我们现在台湾所生产这些电脑产品就使用的科技非常的类似,我们非常期待未来属于人工智能时代,属于机器人的时代。
