星空君最近正在深度使用国产AI绘画大模型,比如快手的可图、腾讯的混元,同时使用了清华团队开发的ChatGLM3开源大模型、字节团队开发的加速插件、小红书团队开发的一致性插件等国产AI工具。

当然了,星空君搞AI绘画以瑟瑟为主,融到资的群友已经开始做一键生成插画集的开发了。

在AI大模型领域,中国进展非常快,并不存在欧美遥遥领先中国的情况。
除了大模型的研发和应用,中国企业又开始硬刚美国AI的核心竞争力:算力芯片。
华为昇腾已经形成量产能力,并在各大厂实现了万卡部署;摩尔线程也完成了万卡部署。
除此之外,国产CPU之光--海光--也尝试在算力领域分一杯羹。
据报道,海光信息DCU的第一代产品海光“深算一号”生产工艺同为7nm制程,内存频率和显存位宽与A100基本相当,显存容量、显存带宽和显存频率相当于A100的50%左右,差距比较大的是多卡协同的交互速率,只有A100的30%。总体来讲,海光“深算一号”的性能应该能达到英伟达A100的40%以上水平。
从措辞来看,星空君觉得40%有些水分,但能实现20%也可以啊!
毕竟算力芯片不需要装到手机上,无非是算力中心多耗点电。
一、海光,Yes!
在所有的芯片技术中,最复杂的莫过于x86。Intel率先开启了x86时代,但后来和AMD、Cyrix的各种技术纠缠、专利官司,导致形成了清官难断的x86永久三方授权的现状。
海光的x86技术来自于AMD公司的授权(另外一家国产x86芯片厂商兆芯的技术则来自Cyrix的尸体)。
AMD于2016年与中国天津海光先进技术投资有限公司(THATIC)签订技术许可协议,授权其x86和SoC IP用于芯片开发,AMD获得了价值2.93亿美元的现金注入(含特许权使用费)。
2019年5月,AMD首席执行官Lisa Su在Computex 2019向Tom's Hardware证实,该公司并未向其中国的合资企业授权进一步的芯片设计。这意味着AMD在中国的芯片生产合资企业将仅限于在第一代Ryzen和EPYC的Zen架构,但不会推进基于AMD新推出的Zen 2微架构的设计。
初看起来,AMD有点背信弃义的味道。
然而实际上,2.93亿美元获取第一代Ryzen和EPYC的Zen架构的授权以及相关的技术支持,对于海光来说,这个价格,简直是白捡的。
这有两个非常巧合的因素,一是Lisa Su是华裔,对中国企业比较友好,促成了这一桩交易;二是2016年的AMD离破产只有一步之遥,可以说是用命根子换钱。

这样的机会可遇不可求,如今再加十倍的价格,AMD怕是也不会卖的。
为了能让海光从无到有做出来,AMD几乎是手把手教,甚至不惜故意让海光挖走很多工程师,甚至是整个团队的送给海光。
2022年八月,海光信息登上科创板。
公司的第一大股东,是中科曙光。作为荣登清单的中科曙光,受益于云计算的高速发展,x86架构的服务器(高性能计算机)是其核心业务。
那么,为了自主可控,曙光一定是海光最大的客户之一了?
海光把第一大客户打了码,销售占比近三分之二,还是关联方。
好吧,星空君就不猜了。
浪潮是海光的第二大客户,还是始料未及的,最为Intel的最大客户之一,浪潮也要未雨绸缪确保核心配件自主可控了吗?
公司第三大客户是华硕电脑,话说作为一家台湾公司,按理说没有自主可控的迫切需求,为什么会采购海光的芯片呢?
二、业绩亮眼
先简要回顾一下公司2023年的业绩:
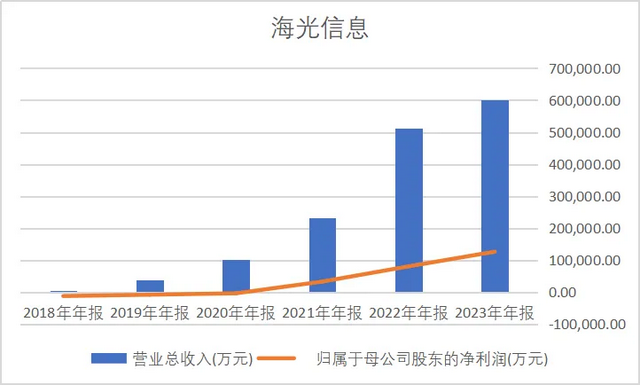
数据来源:同花顺iFind
不难发现,公司近年来的发展是跳跃式的。这和信创的快速推进有关。
2024年继续维持高成长性发展。
公司发布上半年业绩预告,预计2024年半年度实现营业收入35.8-39.2亿元,同比增长37.08%到50.09%;
预计实现归母净利润7.88-8.86亿元,同比增长16.32%到30.78%;预计实现扣非归母净利润7.26-8.21亿元,同比增长17.29%到32.63%。
其中,二季度单季度预计实现营业收入19.88-23.28亿元,同比增长37.06%到60.50%;二季度单季度预计实现归母净利润4.99-5.97亿元,同比增长14.02%到36.39%。
据公司回复,在两大产品线方面,公司进展顺利。
1、CPU方面:公司CPU系列产品兼容x86指令集以及国际上主流操作系统和应用软件,软硬件生态丰富,性能优异,安全可靠,已经广泛应用于电信、金融、互联网、教育、交通等重要行业或领域。
2、DCU方面:在AIGC持续快速发展的时代背景下,海光DCU能够支持全精度模型训练,实现LLaMa、GPTBloom、ChatGLM、悟道、紫东太初等为代表的大模型的全面应用,与国内包括文心一言等大模型全面适配,达到国内领先水平。
三、AI是机遇也是风险
AI时代已经来临,对算力的需求几乎是无上限的。华为昇腾吃不下这个市场,依然会有摩尔线程、海光、寒武纪以及其他国产芯片厂商的发展空间。
然而,从星空君使用的AI工具来说,绝大多数生态都是基于cuda的,这才是黄皮衣的大杀器。

而Cuda又和NVIDIA深度绑定,连AMD都很难与之抗衡,Intel更是早早缴械。
目前国产生态尚不完善,很难全面追赶NVIDIA。
华为在搞达芬奇架构,摩尔线程可以实现cuda的低代码迁移,海光搞类cuda,各自为战。
也许不久的将来,在市场的驱动下,生态会逐渐统一,在这个过程中,海光相对弱势的生态很可能会受到挤压,从而影响产品的销量。
