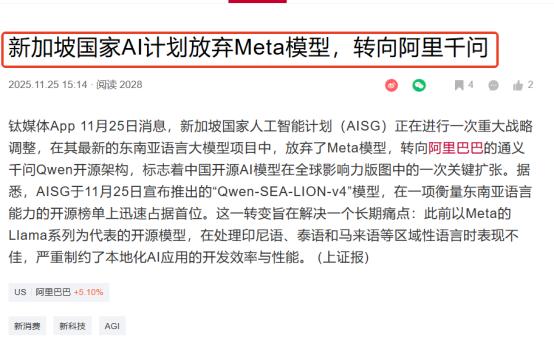
不知不觉中,风向标已经彻底改变!包括美国、德国、英国、新加坡等在内的国家顶尖企业都在向中国看齐,这一次中国站在了技术输出端! 想想从年初开始,中国大模型带给硅谷的震撼一直没有停止过,甚至一度引起了硅谷巨头们的恐慌。而最近新加坡又传来消息,新加坡国家级AI计划,在其最新的东南亚语言大模型项目中,放弃Meta,转而选择了来自中国的阿里千问模型。 就连AI领域的权威吴恩达都公开说,中国在生成式AI上正在赶超美国,2022年ChatGPT刚出来时美国还遥遥领先,可这两年差距肉眼可见地缩小,在视频生成这些领域,中国已经跑到了前面。 这话一点不假,OpenAI的Sora刚让大家惊艳没多久,中国的可灵大模型就实现了产品落地的反超;GPT-4o的实时语音功能体验平平,豆包的语音大模型一上线就凭极致的拟人度圈粉无数,还直接全量免费开放。这些不是嘴上说说的优势,是硅谷巨头们不得不承认的硬实力。 这种震撼不是空穴来风,最近新加坡的一个大动作,把中国大模型的全球分量彻底摆到了台面上。作为东南亚的科技枢纽,新加坡去年砸了5200万美元搞国家级AI计划,核心项目就是开发针对东南亚语言的“海狮”大模型。 一开始他们选的是Meta的Llama系列,毕竟那是硅谷的主流开源模型,可用着用着就发现全是坑。 东南亚6亿人口,光语言就有上百种,还流行英语掺方言的“语码转换”,可Llama模型里东南亚语言的内容占比居然只有0.5%,训练出来的早期版本甚至把委内瑞拉当成东盟成员国,简直是“东南亚文盲”。 吃够了西方模型的亏,新加坡国家AI计划最终把目光转向中国,阿里的通义千问成了他们的新选择。这可不是随便换个供应商,而是技术路线的彻底转向。 阿里千问光是预训练就用了36万亿个token,覆盖119种语言,对印尼语、泰语这些小语种的语法逻辑摸得门儿清。针对东南亚语言没空格的特点,还专门用了字节对编码分词器,翻译准确率和推理速度直接翻倍。 更关键的是,优化后的模型在普通消费级笔记本上就能跑,这对算力紧张的东南亚中小企业来说,简直是雪中送炭。换上中国“心脏”的海狮v4模型一上线,就直接冲上了东南亚语言模型榜单的榜首。 新加坡的选择不是孤例,现在全球顶尖企业都在往中国AI生态里扎。美国的AMD专门在中国设了ROCm实验室,帮本土大模型突破算力瓶颈,他们的迷你AI工作站能在本地跑千亿级大模型,早就成了医疗行业的香饽饽。 高通更不用说,第五代骁龙平台刚发布一个多月,12款搭载该平台的中国手机就集体亮相,连智能汽车的数字底盘都靠中国车企落地。 那些以前垄断技术的美国企业,现在都在主动对接中国的应用场景,因为他们清楚,离了中国市场,再牛的技术也落不了地。 欧洲企业也没掉队,德国的工业巨头早就开始用中国大模型优化生产线,英国的金融机构靠着百度文心一言的多模态检索能力处理数据,连法国施耐德都把最新的液冷技术拿到中国,专门适配咱们的AI数据中心。 这些企业以前都是技术输出方,现在却成了中国大模型的“用户”,这种角色转换的背后,是中国AI从技术到场景的全链条突破。 阿里千问全球下载量突破6亿次,百度文心一言的RAG能力领跑全球,这些数字不是吹出来的,是靠“工业级能力,民用级门槛”的实在优势拼出来的。 以前咱们买国外的软件得看脸色,现在国外企业来求合作,咱们的大模型能直接解决他们的痛点。这种转变,本质上是中国AI企业把技术做深做透了——既懂多语言的文化差异,又懂中小企业的实际需求,还能靠工程创新打破对高端GPU的依赖。 现在再没人敢说中国AI是“跟跑者”了,从硅谷巨头的恐慌到新加坡的转向,从美国芯片厂商的主动合作到欧洲企业的技术对接,全球科技圈的风向标已经彻底变了。 这一次中国站在技术输出端,靠的不是运气,是实打实的研发投入和场景积累。那些曾经垄断技术的国家现在发现,要搞AI创新,绕不开中国的模型、中国的场景、中国的生态。 如果说以前全球科技格局是“西方定规则”,那现在中国正在用实力改写剧本,而这仅仅是个开始。