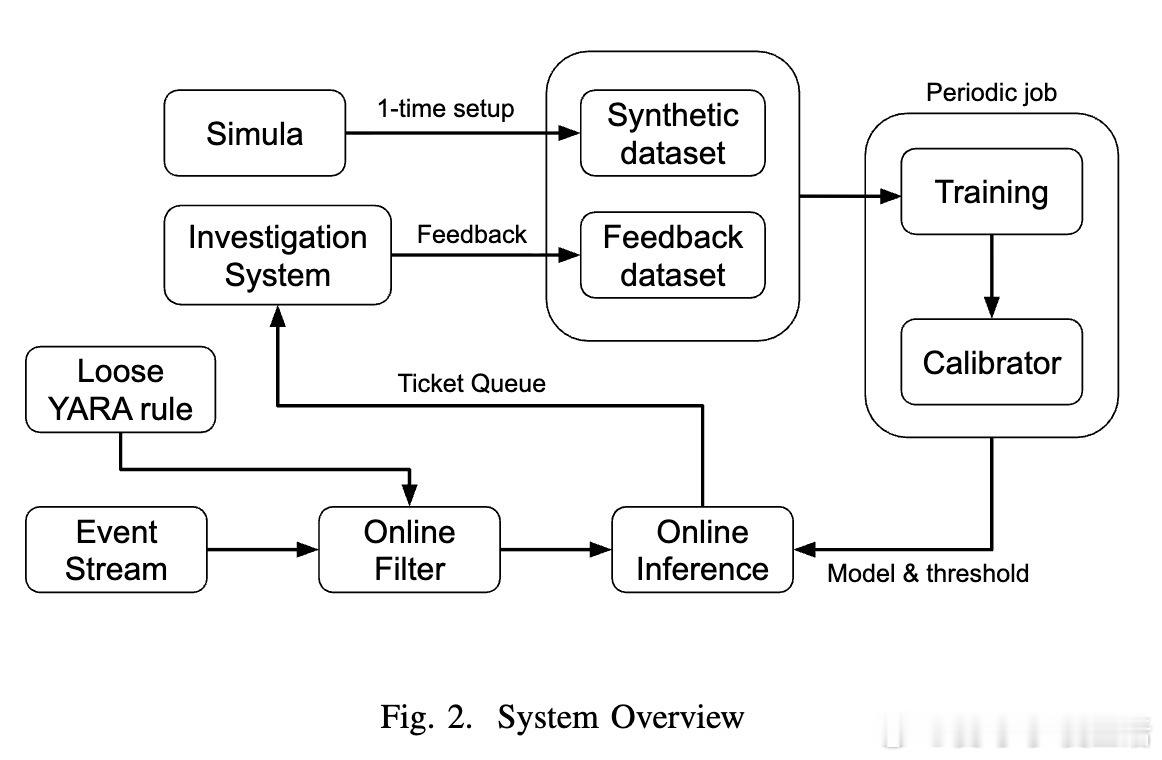
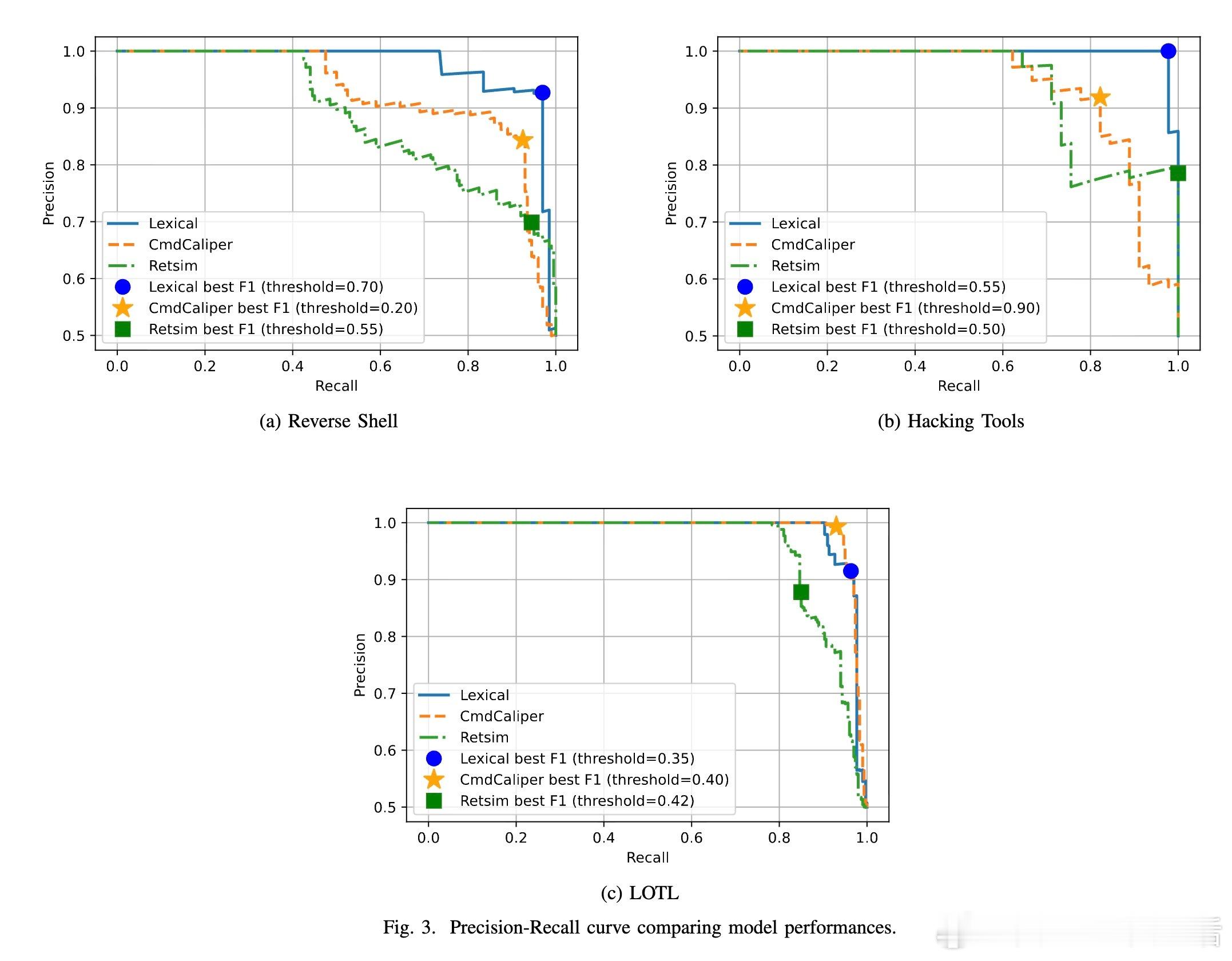
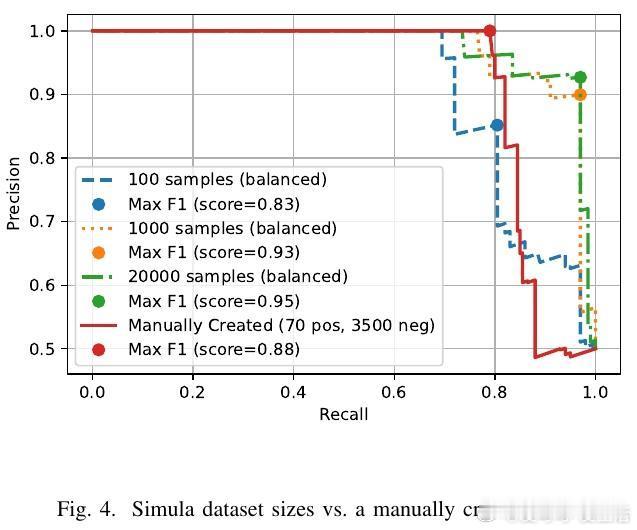
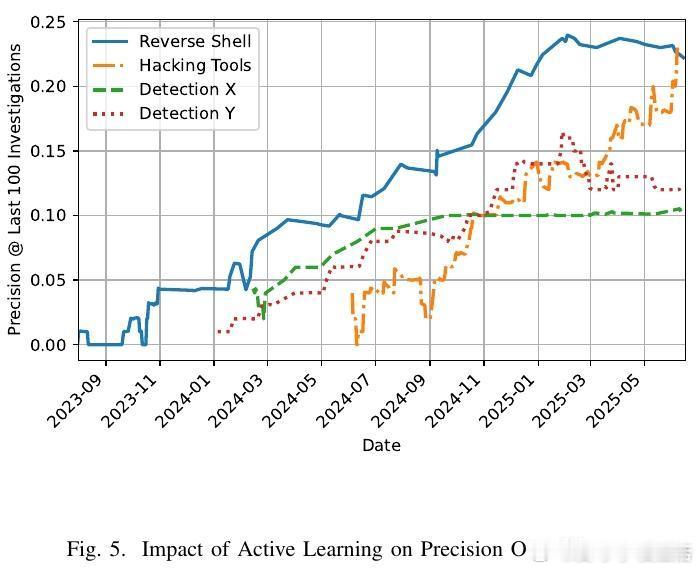
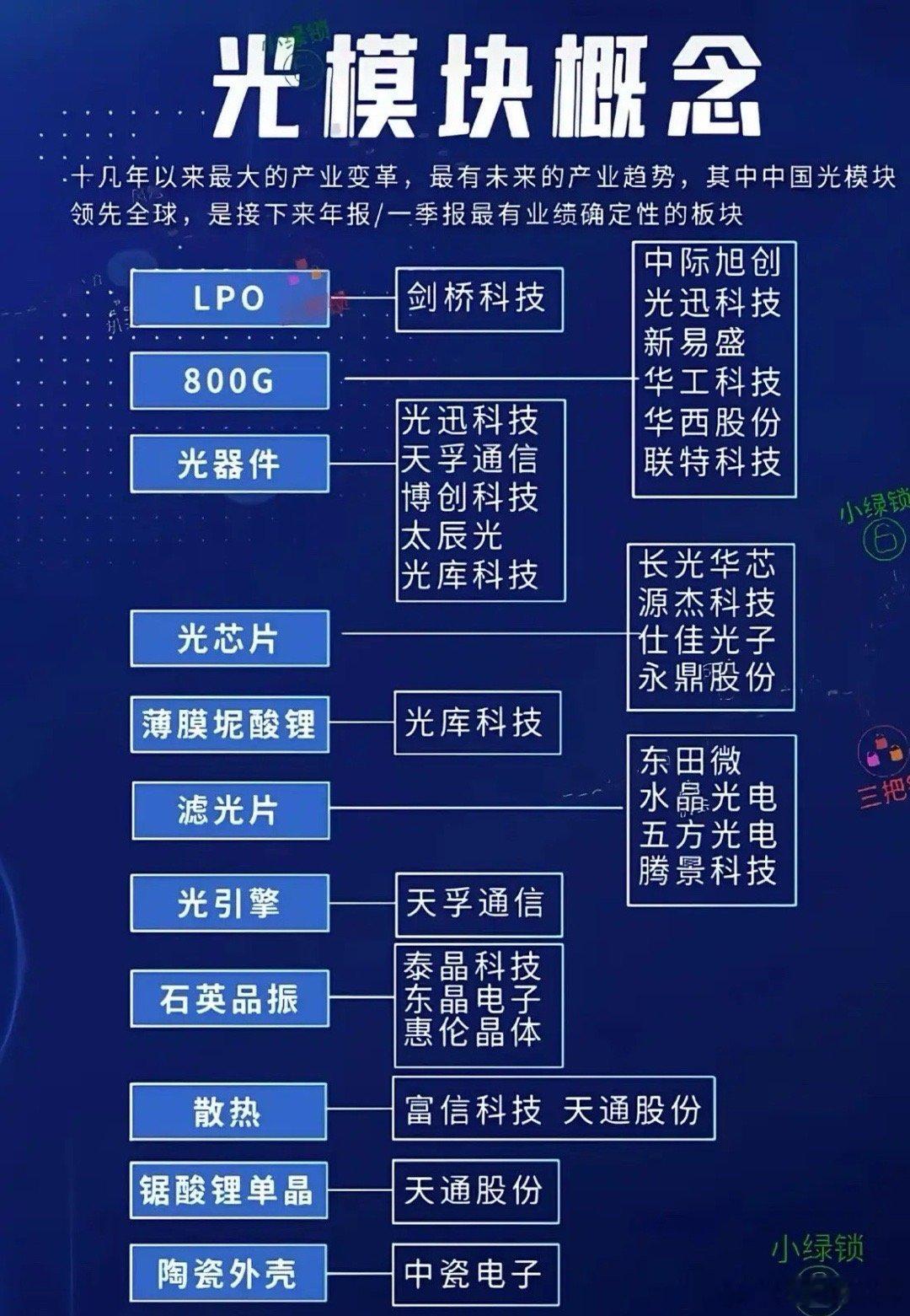
[AI]《Democratizing ML for Enterprise Security: A Self-Sustained Attack Detection Framework》S Momeni, G Zhang, B Huber, H Harkous... [Google LLC] (2025) 在企业安全领域,尽管机器学习(ML)技术不断进步,传统基于规则的检测依然占据主导地位,原因在于ML方案资源消耗大且对专业技能要求高。本文提出了一个创新的二阶段混合框架,旨在“民主化”ML威胁检测,使安全分析师无需深厚数据科学背景即可利用ML提升检测效率。第一阶段采用宽松的YARA规则进行粗过滤,确保高召回率,最大限度降低漏报,但会产生大量误报;第二阶段利用ML分类器对第一阶段的结果进行精细筛选,从而显著减少误报负担。为解决标注数据稀缺问题,系统引入Simula——一个无须种子数据的合成数据生成框架。Simula通过构建涵盖全面攻击策略的知识分类体系,结合生成器与评审器的循环优化,实现高质量、多样化的合成样本自动创建,帮助安全专家快速生成训练集,无需依赖真实样本或复杂手工标注。此外,系统设计了持续反馈机制:人类分析师对报警工单的调查结果被实时回馈给ML模型,支持基于时间衰减的加权策略和样本平衡,确保模型能适应网络环境的动态变化,有效应对分布漂移,避免规则失效。模型架构灵活,支持从轻量级的n-gram词法模型到复杂的嵌入式语言模型。令人惊讶的是,简单的词法模型在终端命令行分类任务上表现优异,效率远超复杂模型。在Google的生产环境中,该系统已成功部署,日处理日志事件高达2500亿条,经系统过滤和ML推断后,每天仅产生少数需人工复核的告警票据(例如反向Shell检测平均每天约0.48条),极大减轻了分析师的工作负担。长期在线测试显示,凭借主动学习,模型精准率随时间稳步提升,体现了系统的自我维持和自动优化能力。该框架不仅提升了安全监控的自动化和智能化水平,更为企业安全分析师提供了一个“教练”角色,让他们能够直接参与模型训练过程,弥合了传统ML应用中的技能瓶颈和数据壁垒。通过综合利用规则的高效筛选和ML的智能判别,加上创新的合成数据生成和主动学习反馈,本文方案为企业级安全威胁检测开辟了一条可持续、低维护、易推广的新路径。详细论文链接:arxiv.org/abs/2512.08802