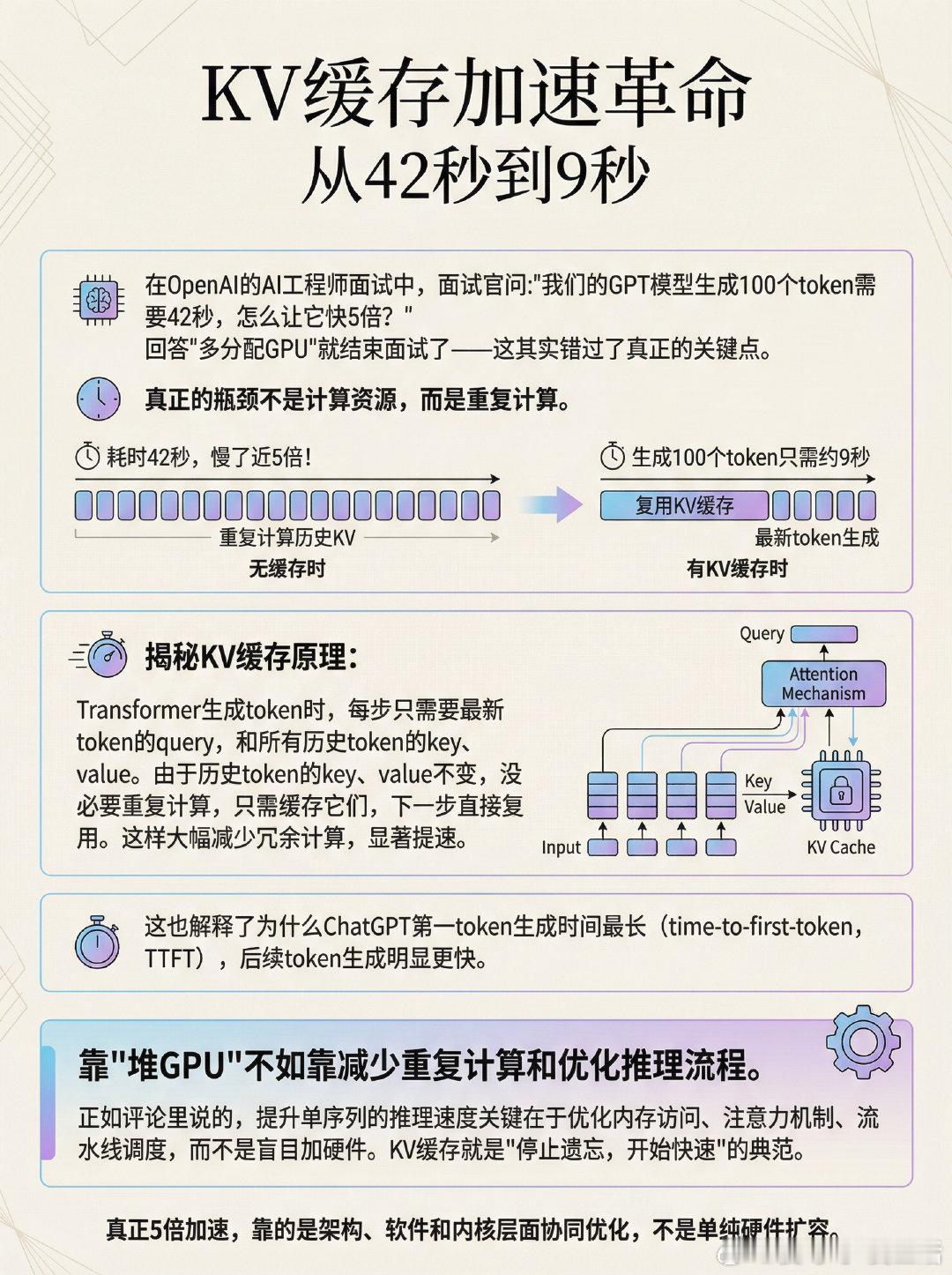
在OpenAI的AI工程师面试中,面试官问:“我们的GPT模型生成100个token需要42秒,怎么让它快5倍?” 回答“多分配GPU”就结束面试了——这其实错过了真正的关键点。真正的瓶颈不是计算资源,而是重复计算。如果没有启用KV缓存,模型每生成一个token都会重新计算所有历史token的key和value,导致效率极低。 - 有KV缓存时,生成100个token只需约9秒 - 无缓存时,耗时42秒,慢了近5倍!揭秘KV缓存原理: Transformer生成token时,每步只需要最新token的query,和所有历史token的key、value。由于历史token的key、value不变,没必要重复计算,只需缓存它们,下一步直接复用。这样大幅减少冗余计算,显著提速。这也解释了为什么ChatGPT第一token生成时间最长(time-to-first-token,TTFT),后续token生成明显更快。靠“堆GPU”不如靠**减少重复计算和优化推理流程**。x.com/_avichawla/status/1998644203908378844正如评论里说的,提升单序列的推理速度关键在于优化内存访问、注意力机制、流水线调度,而不是盲目加硬件。KV缓存就是“停止遗忘,开始快速”的典范。真正5倍加速,靠的是架构、软件和内核层面协同优化,不是单纯硬件扩容。