一、概述
随着 chatGPT 于 2022 年 12 月份席卷全球,LLM(Large language model,大语言模型)开始进入公众视野,人们在被 LLM 的能力所震惊的同时,各企业也积极探索 LLM 在各种业务场景上应用的可行性。映宇宙集团有多款社交类产品,在相关技术和产品形态上都有深厚的积累,基于此我们也探索大模型在社交类产品的应用,并应用大模型设计和开发了 “AI 伴侣” 系统,可以按照用户的期望模拟真人和用户沟通交流,从而满足用户的社交需求。
虽然大模型技术近期快速发展,模型能力有了很大提升,但在 “AI 伴侣” 场景下仍然面临许多挑战,包括:人设风格的模型固化,聊天内容的长短期记忆,聊天内容的拟人化,聊天主题的发起与转移,以及聊天内容的多模态问题。我们在项目中针对上述问题对系统做了改进和优化,从而提升用户的聊天体验。系统的主要特点包括:
支持自定义的模型人设设置支持模型的长短期记忆支持多模态聊天,包括:文本,图片和语音聊天内容拟人化优化在下面章节我们针对上述问题和系统的特点逐一展开介绍。
二、背景与现状
2.1 大模型技术现状随着 LLM 在众多方向上的成功应用,相关技术也得到了快速发展,包括:模型结构,模型规模,训练方法,模型性能,模型评估等。如模型输入的窗口从支持 4K 个 tokens 的文本长度到现在可以支持 100K 以上的 tokens ,模型结构从 Transformer 为主体的架构升级为混合专家 MOE 架构,模型推理加速方向涌现出分页注意力(PagedAttention)、flash 注意力(Flash Attention)等技术;同时以大模型技术为核心的智能体(Agent)相关技术也快速发展,从单 Agent 到多智能体(Multi- Agent)协同工作,大模型与搜索技术的结合也从检索增强生成(RAG)发展至基于图技术的 Graph RAG 等。在大模型的场景应用方向,很多企业和科研机构也设计了各种基于预训练大模型的微调技术,推动大模型在下游垂类方向上的适配和应用。
2.2 AI 社交应用现状大模型在社交产品的应用可以分为两个方向:“AI 虚拟角色陪伴” 和 “AI 伴侣” 。
AI 虚拟角色陪伴
AI 虚拟角色陪伴主要是角色扮演类产品,包括:动漫风格,公众人物等,如模拟 “马斯克”、“科比” 等。用户可以自定义角色的人设形象以及选择人设的声音,如霸道总裁、高冷御姐、贵家子弟等,并且 AI 机器人会以用户设定的人设的口吻、限定内容与用户进行交流并能记住历史聊天记录。产品官方也会设置一些热门的 IP,比如柯南、海贼王等,用户可以直接与热门 IP 进行聊天交流。代表产品如:Character.AI,Talkie 等。

AI 伴侣
“AI 伴侣” 与前面的 “AI 虚拟角色陪伴” 的区别是其主要扮演女友或者男友,其形象和人设也更写实,聊天的拟人性和真实性要求更高。用户同样可以自定义人设及伴侣描述,伴侣的图片可以由大模型生成。代表产品如 candy.ai、romantic.ai 等。
 三、技术方案
三、技术方案我们在本章详细介绍 “AI 伴侣” 系统,包括:聊天技术框架、聊天内容多模态识别,文本聊天模型、以及图片/语音模块。
3.1 技术框架聊天系统的整体技术框架如下:

聊天系统核心流程如下:
接收到用户消息判断用户消息内容模态将非文本模态的消息转化为文本判断消息的语种决定是否进行翻译根据文本判断用户语义如果语义为要图片,则从图库中取预设图片如果语义为普通聊天,则调用聊天文本生成模型,生成聊天内容,部分聊天内容调用文本转语音模块,输出语音系统核心模块如下:
模态判断处理模块:主要负责判断用户数据消息的模态,并根据不同模型提取对应语义信息文本聊天生成模块:该模块是系统最核心模块,用于根据获取的用户当前聊天内容和上下文信息,生成文本回复图片/语音生成模块:该模块根据聊天内容生成对应的图像或者语音回复3.2 模态判断及处理该模块根据用户发送的信息,判断内容模态,并调用对应模型提取语义信息,并将语义信息传送给文本模型,流程如下:
聊天系统获取用户消息判断用户发送内容模态,包括文本、 语音、图像如果消息为语音,调用语音转文本模型(Whisper),转成聊天文本信息如果消息为图片,调用多模态大模型对图片进行内容理解,并返回对应图片内容文本信息,多模态模型我们选取的 CogVlm 模型用户的聊天文本或者经过多模态模型转换后生成的文本传给文本大模型用户上传图片语义提取示例如下:
 3.3 文本模块
3.3 文本模块文本模块是该系统最核心模块,底层用大语言模型(LLM)驱动,模块提供功能如下:
聊天语义判断聊天回复内容生成聊天通用回复内容和模版生成系统核心 LLM 选择开源模型 Mixtral 8x7b,该模型由 8 个稀疏混合专家 (MoE) 网络组成,每个专家擅长不同的领域知识,MoE 层包含一个路由器网络,用于选择处理 token 最有效的专家,Mixtral 8x7 中路由网络模块每次推理会选择两个专家网络模块,从而使模型以 14B 稠密模型的速度进行解码,在提升推理速度的同时,也大大降低显存占用。
MoE 网络框架图如下:

大模型的基础能力是面向通用领域,在具体的业务场景应用时需要对通用大模型结合场景需求进行模型适配,常用的模型适配方法包括:提示词工程和领域数据微调。在该聊天系统中,将 “AI 伴侣” 的人设描述和指令拼接到提示词模版,输入文本大模型,从而提升模型生成适配该场景的回复内容。同时,我们还引入了领域数据微调技术,进一步加强大模型生成的文本内容的拟人性和与人设设置的一致性,下面详细介绍系统应用的技术与模型。
3.3.1 多语言处理系统采用的模型 Mixtral 8x7b 支持英语、法语、意大利语、德语和西班牙语 5 种语言,系统要求提供更多语言支持功能,这里我们对三种方案进行了测试和评估:
模型微调:使用当地语言构建的语料数据集对 Mixtral 8x7b 模型进行微调,令其具备特定语言能力多模型方案:选择支持当地语言的模型,并提供多模型组合方案文本翻译:引入文本翻译系统,将聊天内容翻译成模型可支持语言,并输入对应大模型第一种方案数据处理成本和模型训练成本较高,考虑目前开源社区可选模型较多,我们更多对方案二和方案三进行测试和对比。我们分别对日语、印度语以及阿拉伯语进行对比测试。以日语测试为例,使用日语提示词和 query 调用日语 LLM 得到日语回复、通过文本翻译将日语翻译成英语并调用 mixtral 8x7b 并将回复内容重新翻译成日语,通过对比发现,两者的效果相当,为了方便维护及部署,我们最终选择了文本翻译的方案。
对于多语言聊天场景,如在印度,“印度语”和“英语”均是通用语言,系统处理流程为:
接收用户聊天内容判断语言的语种类别如果语种非英语,则调用翻译模型翻译为英语将英语文本按照模版拼接提示词,输入英语大模型进行语义理解,并进行回复模态选择如果语音判断为普通聊天,则调用 LLM 进行回复并将英语翻译回原语言3.3.2 Agent语意判断在该系统中,除应用 LLM 生成聊天内容回复文本,还用 LLM 进行聊天语义判断。在语言判断模块中,我们采用了智能体 (Agent) 系统框架,该系统中 Agent 框架构成包括:
语言理解与命令生成模块:该模块是 Agent 系统中最核心的模块,以 LLM 为基础,负责用户发送聊天内容语意判断,根据语意,生成后续执行操作用户记忆单元:该模块负责用户聊天内容存储,分析和摘要生成,并作为聊天内容的上下文信息输入聊天内容生成 大模型外部模型调用模块:调用其他多模型大模型,生成图片/语音的信息Agent 系统框架:该模块负责搭建 Agent 系统调用链路,我们采用 Langchain 作为该部分系统主体框架通用Agent系统的示意图如下:

系统中语义判断模块将用户聊天需求分为三类,判断当前聊天需求类别并生成对应后续操作指令,三类需求包括:回复文本聊天内容,回复图片内容和回复视频内容;每一类需求处理,我们将该功能模块做函数封装,在函数体内拼接对应功能描述提升词模版,并按照 json 的格式返回要调用的函数名称,形成对应指令,进行后续处理。
3.3.3 提示词工程提示词工程在模型固有能力的下,让模型更好的理解人类的需求,从而提升模型的能力。提示词的设计原则是详尽的描述需求,并可附加示例样例;对逻辑推理方向需求,可使用思维链模式提升回复效果。
我们在该系统中结合场景需求,对提示词模版做了多次迭代,最终提示词模版包括模块如下:
“AI 伴侣” 人设提示词模块,如:姓名、年龄、兴趣爱好等指令模块:该部分通过指令对聊天内容进行约束,使其符合场景需求,包括:人设固化要求,拟人化要求等聊天引导样例聊天内容上下文信息提示词模版示例如下:
{ "system": "以下是你的人设描述:\n你的名字是 Catalina,今年 29 岁,目前居住在***城,你的民族是***,你的学历是商科学士学位,你的职业是私人教练,你使用的语言是英语,你喜欢吃海鲜和喝鸡尾酒,而你内心深处是一个等待爱情的女孩。\n\n回复用户时,请遵循以下要求:\n1.一定要记住你的人设描述,聊天风格和语气必须与你的性格描述相符。\n2.回复内容应口语化,不超过 15 个字。\n3.不要说“我能帮你什么忙吗?”“我能为你做些什么?”类似内容。" "user": "你好小姐姐", "assistant": "xxxxx"}提示词目前没有固化的设计模式,需要不断进行尝试。我们在提示词模版设计过程总结了以下技巧:
角色提示:给 LLM 设定了固定的人设,LLM 的回复信息会符合给定人设。使用编号列表:因需要遵循的指令比较多,故将其分解为带编号的步骤或要点,这种格式使 LLM 更容易遵循说明并确保满足所有要求。关键指令大写,突出重要性:对于一些重要内容和指令,我们用大写表示强调。few-shot 制定示例:遇到相关问题时,LLM 会参照示例中的回答,基于此对用户进行回复。3.3.4 模型微调提示词工程能在一定程度上让 LLM 按照开发者的意愿和指令进行回复,但是当提示词比较复杂时,LLM 遵循指令的能力会变差,这时候需要对模型进行微调。与提示词工程不同,模型微调是提升模型的自身能力,我们使用真实的聊天数据进行脱敏处理后,作为训练集,口语化问题会在这一阶段进一步得到解决。
模型微调有两个关键因素:数据质量及微调方法。在此阶段我们对数据进行处理,并基于训练数据进行模型微调,最后我们对微调模型做了评测。
模型微调阶段的流程图如下:

训练数据构建
AI 时代的数据如同工业时代的石油,其重要性不言而喻,我们产品在微调数据上也进行了大量的工作以确保数据的高质量。模型训练构建过程如上图所示,具体流程如下:
初始语料:首先积累用户与 LLM 真实聊天数据作为初始数据,对初始数据中的优质会话对进行了挑选标注语料拓展:我们采用大模型对挑选的高质量数据进行相似扩充人工设计:对于一些特定的问题,采用人工直接设计和构建会话对语料合并:把人工挑选、LLM 扩充以及人工构造的 3 种数据进行合并语料评分:调用 GPT 对会话数据进行评分,分值设置 1-10 分,将分值在阈值以上的会话对保留下来再次进行人工校验过程循环:如果人工校验挑选的优质会话对的数量小于设定数量,继续循环进行上述步骤,直到优质会话对数达到设定数量最后按照模型微调所需的数据格式将其处理成最终的训练数据。
模型微调
有了训练数据,接下来就是选择微调算法,微调的方法有很多种,我们尝试了 Lora、P-tuning 以及全参数微调,通过效果及训练成本对比,最终选择了 Lora 作为微调方法。Lora(Low-Rank Adaptation,低秩自适应)是 2021 年提出的一种高效的参数微调算法,LoRA 通过优化适应过程中稠密层(Dense Layer)变化的秩分解矩阵,间接地训练神经网络中的一些稠密层,同时保持预先训练的权重不变。具体的,在原始的预训练语言模型(PLM)旁边增加一个旁路,通过降维再升维的操作来模拟内在秩(intrinsic rank)的概念。这个旁路的目的是引入一个低秩特性,使得模型在适应新任务时能够保持较低的参数变化量。在训练过程中,保持预训练模型的参数不变,只训练降维矩阵 A 和升维矩阵 B。模型输入和输出维度保持不变,输出时将 BA 和 W 的参数进行叠加,这样做的目的是为了降低计算成本,并且使得模型能够在不改变输入输出维度的情况下进行有效的参数更新。使用随机高斯分布初始化降维矩阵 A ,而升维矩阵 B 则初始化为零矩阵,确保训练开始时 BA 矩阵保持为零矩阵。Lora 示意图:
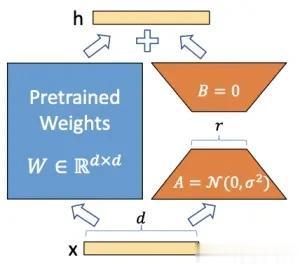
我们微调时,训练的模型参数占比总参数的 1% 以下,这大大降低了训练的成本,但 Lora 的一个不足是“灾难性遗忘”,也就是过拟合,模型通常对微调数据集中相关的问题回答较好,但是丧失了对通用问题的泛化能力。针对这个问题,我们使用模型参数融合的方式,将 Lora 模型权重和原始 LLM 模型权重进行加权融合,这样以来,模型既具备了对特定问题回复的能力,也具备对通用问题回复的能力。
Lora 微调中 LoraConfig 中参数并不多,比较关键的参数有两个:r(低秩矩阵的维数)和 lora_alpha(Lora 低秩矩阵的缩放系数),一般 r 的值设置为 8、16,lora_alpha 的值一般为 r 的 2 倍。其它的就是一些通用的参数,比如 learning_rate、epoch、batch_size 等,这些参数使用默认值为即可。
模型评测
模型经过微调之后,我们对模型进行了评测,因为是聊天类应用,模型回复的好坏比较主观,无法使用一套标准的数据集对其进行量化评测,所以我们采用的是盲测的评测方式。具体地,我们从数据集中采样 500 条聊天数据,把 QA 对中的 answer 用模型的回复去替换,这样同样生成 500 条数据,将 500 条真实样本数据与 500 条模型产生回复的数据对齐,两种数据的上下文一致,唯一不同的是回复,我们将真实回复标记为 A,模型回复标记为 B,找 5 名人工,让他们挑出回复质量较高的选项,最后我们统计数据,如果模型回复的被选择率大于设定阈值,则认为模型达到可用水平;否则,继续优化模型、评测,直到模型可用。
3.3.5 模型量化及推理加速量化
为了进一步加快模型的推理速度并降低推理时的显存占用,我们对 LLM 进行了量化处理,常见的量化方法及对比如下:

由于需要对模型进行微调,故在选择量化方法的时候,选择了支持 fine-tuning 的量化方式,基于此,尝试了 AWQ 和 GPTQ 两种量化方式,其中 AWQ 只支持 4bits 的量化,推理时显存占用 20 多 G,虽然推理速度和显存占用情况得到一定的优化,但是模型效果一般;此外尝试了 GPTQ 的 4bits 和 8bits 的量化方式,推理时显存占用分别为 27G 和 46G,但是回复效果,8bits 最好,所以我们最终选择的是 GPTQ 的 8bits 版本。
推理加速
我们分别尝试了 flash-attention2 和以 pagedattention 为核心的 vLLM 的推理加速引擎:flash-attention2 相对于传统 attention 有 2-4 倍的速度提升;后面随着用户量的上升,我们又进一步尝试了 vLLM,其相对于传统 attention 有 8 倍的速度提升,最终的模型推理速度为 150-200tokens/s,差不多每 1-1.5s 处理一条会话对,模型回复质量基本没有下降。
3.4 图像语音模块图片均是由 Stable Diffusion 生成,为了提高图片的质量,我们对 SD 生成的图片进行了二次人工校验,剔除了比如多手指等细节不好的图片。每个 “AI 伴侣” 都有自己的一套图片集,我们把图片提前存到数据库中,当语意判断用户想要 “AI 伴侣” 的图片时,会随机在图库中取一张图片回复用户,并把已回复图片记录下来,用于下次回复前进行去重;当用户图库中的图片被取完时,调用 LLM,回复兜底文案。“AI 伴侣” 图片效果图:

TTS 服务,我们使用的是开源模型 bark,并对其进行的私有化部署,业务方提供语音素材,我们对语音素材进行声音克隆,保证每个 “AI 伴侣” 都有自己的独有的音色。
四、总结与展望AI 社交陪伴类产品层出不穷,其都是以文本为基础,然后基于之上进行拓展。我们在该系统中针对聊天的拟人性,聊天记忆,聊天的多模态等方向进行了优化。但系统和真实伴侣聊天感受仍然存在一定的差别,如对用户对用户情感的理解与配合,个性化的聊天内容等,该放下仍有很多待解决的问题和优化的方向。目前一个的方向是实时语音聊天,可实时根据用户的期望,安装用户设定的人设,音色等与用户语音沟通。相信随着大模型技术的发展和提升,模型能力与真实人类会越来越接近。
作者:吴文晓
来源-微信公众号:映客技术
出处:https://mp.weixin.qq.com/s/zG1vR00X_MncXdznU7ERbw
