Jigsaw: Large Language Models meet Program Synthesis
Naman Jain 1, Skanda Vaidyanath 1, Arun Iyer 1, Nagarajan Natarajan 1, Suresh Parthasarathy 1, Sriram Rajamani 1, Rahul Sharma 1
1Microsoft Research, Bangalore, India
引用
Jain N, Vaidyanath S, Iyer A, et al. Jigsaw: Large language models meet program synthesis[C]//Proceedings of the 44th International Conference on Software Engineering. 2022: 1219-1231.
论文:https://dl.acm.org/doi/abs/10.1145/3510003.3510203
摘要
本文提出了一种方法,用基于程序分析和合成技术的后处理步骤来增强这些大型语言模型,这些步骤理解程序的语法和语义。此外,我们表明,这样的技术可以利用用户反馈,并随着使用而改进。我们介绍了构建和评估这样一个工具Jigsaw的经验,它的目标是使用多模态输入来合成使用Python Pandas API的代码。我们的经验表明,随着这些大型语言模型为从意图合成代码而进化,Jigsaw在提高系统的准确性方面发挥着重要作用。
1 引言
预训练的大型语言模型(PTLM),例如GPT-3,被广泛应用于自然语言处理(NLP),作为解决多种NLP任务的通用平台。最新研究指出,通过将文档文本与大规模的代码训练集相关联,PTLM能够利用自然语言提示生成代码。这一发现为程序合成提供了新的途径。然而,PTLM并不理解代码的语法或语义,而是将代码视为文本。因此,由此类模型生成的代码可能缺乏正确性和质量保证。因此,任何使用PTLM生成代码的系统都需要配备程序分析和程序合成模块以增强其准确性。
本文介绍了一个名为Jigsaw的多模态程序合成系统,专门用于使用大型复杂API合成代码。Jigsaw是多模态的,因为它可以接受自然语言字符串表达的意图和一组测试用例作为输入,并生成代码片段作为输出。Jigsaw的架构包括预处理模块和后处理模块。预处理模块将自然语言意图转换为自定义查询,并将其发送给PTLM。后处理模块执行语法和语义检查,对PTLM生成的代码执行转换以确保通过提供的测试用例和其他质量检查。这些转换专门用于纠正PTLM的常见错误,例如引用错误、参数错误和语义错误。
Jigsaw通过将用户反馈纳入预处理和后处理模块,并从用户参与中学习来提高整体质量。实验表明,Jigsaw能够从过去的使用中学习,提高未来性能。
当前版本的Jigsaw设计和评估用于合成Python Pandas API的代码。但是,Jigsaw的设计原理是通用的,可以扩展到其他库和编程语言。我们还创建了一个用户界面,扩展为Jigsaw,可通过Jupyter notebook调用。用户可以使用该界面向系统提供输入,检查结果,并将所需的输出复制回主笔记本窗口。
我们在两个数据集上评估了Jigsaw的整体准确性以及预处理和后处理模块的准确性。这两个数据集是PandasEval1和PandasEval2。我们利用第一个数据集的用户反馈来改进Jigsaw的预处理和后处理模块,并发现用户在第二个数据集中即将解决约10%的多任务,这是由于第一个数据集的学习改进。
我们使用两种最先进的PTLM实例化了Jigsaw:GPT-3和Codex,并在第五节中进行了全面评估。结果显示,与基线和最先进的代码合成框架相比,Jigsaw在两个数据集上都有整体性能改进,并且随着时间的推移,从用户反馈中学习带来了收益。综上所述,本文做出了以下贡献:
我们提出了一种架构,通过使用基于程序分析和合成的技术以及多模态规范来增强黑盒PTLM,从而执行代码合成。我们在一个名为Jigsaw的工具中实现了该架构。我们开发了一个Jupyter notebook扩展,允许用户与系统进行无缝交互。我们描述了PTLM产生的常见错误类别,即引用错误、参数错误和语义错误。受这些错误的启发,我们在Jigsaw中设计了程序分析和合成技术来修复PTLM产生的代码片段中的这些错误。我们还设计了从用户反馈中学习并随着使用改进的技术。我们创建了两个具有多模态规格的Pandas数据集(在补充材料中提供,并将发布供社区使用)。使用两个最先进的PTLM,我们表明Jigsaw与两个数据集上的基线相比产生了更高的准确性。2 技术介绍
Jigsaw的架构如图1所示。在本节中,我们将详细描述每个模块。

图1:Jigsaw的架构
2.1 预训练语言模型
我们以GPT-3为例来描述预训练语言模型(PTLM)。GPT-3代表“生成预训练变压器3”,是OpenAI开发的第三个版本的大型变压器模型。它包含1750亿个参数,并在一个庞大的语料库上进行训练,该语料库由公开可用的数据集组成,如CommonCrawl、WebText数据集、两个基于互联网的图书语料库和英语维基百科。GPT-3是一种通用模型,可用于执行各种自然语言处理任务,而不需要对模型进行特定任务的微调。用户可以使用几个例子描述任务,然后GPT-3能够生成特定任务的答案。这些例子通常以(问题,答案)的形式提供,其中问题描述了用户希望GPT-3解决的任务。
例如,如果问题是英语句子,答案是法语翻译,则GPT-3可以用作英法语言翻译器。
其他近期的PTLM包括Codex,它是OpenAI专门针对代码训练的语言模型,以及谷歌的大型语言模型;这些模型将自然语言翻译成程序。Jigsaw使用PTLM生成Pandas代码,通过自然语言描述和测试用例给出意图。具体地说,Jigsaw的会话形式是(意图描述,代码),其中意图描述是英语描述的意图,而代码是我们希望PTLM生成的代码片段。我们目前没有将输入输出示例传递给PTLM。相反,我们使用这些测试用例来检查和过滤在后处理期间由PTLM产生的候选代码,或者转换由PTLM产生的代码,使其通过测试用例。
2.2 预处理
我们以GPT-3为例描述预训练语言模型(PTLMs)。GPT-3代表“生成式预训练Transformer 3”,是由OpenAI开发的大型Transformer模型的第三个版本。GPT-3是一个神经模型,具有1750亿个参数,训练于一个非常大的语料库,包括CommonCrawl、WebRText数据集、两个基于互联网的书籍语料库以及英文维基百科等公开可用的数据集。GPT-3是一个通用模型,可以定制用于执行各种自然语言处理任务。这样的定制不涉及针对特定任务对机器学习模型进行微调。相反,使用GPT-3的用户可以使用几个例子来描述任务(通常需要4-5个例子),然后GPT-3就能够为特定任务生成答案。与GPT-3的会话形式如下:(问题1, 答案1), (问题2, 答案2), ... , (问题n, 答案n), 问题x,其中n是一个小的数字(通常是4或5),(问题i, 答案i)是描述我们希望GPT-3执行的任务的问答对,问题x是我们寻求答案的问题。
例如,如果(问题i, 答案i)这样描述,其中问题是英文陈述,答案是相应的法文翻译,那么GPT-3就成为了一个英法语言翻译器。
其他最近的PTLM包括Codex,这是OpenAI最近专门针对代码训练的语言模型,以及Google的大型语言模型;这些模型将自然语言翻译成程序。Jigsaw使用PTLM生成Pandas代码,提供自然语言意图描述和测试案例。具体而言,与GPT-3的Jigsaw会话形式如下:(描述1, 代码1), (描述2, 代码2), ... , (描述n, 代码n),其中描述是意图的英文描述,代码是我们希望PTLM生成的代码片段。我们目前不会将输入输出示例传递给PTLM。相反,我们使用这些测试案例在后处理过程中检查和过滤PTLM生成的候选代码,或者转换PTLM生成的代码以使其通过测试案例。
2.3 后处理
PTLM产生的代码片段的准确性和质量取决于多个因素,包括用于编码问题的自然语言句子、提供的上下文库、上下文选择以及温度参数。Jigsaw的后处理步骤旨在过滤和转换PTLM产生的输出,以生成正确的答案。我们将正确性定义为生成的代码应该通过用户指定的I/O示例。在许多情况下,代码无法解析或出现异常而失败,这被视为测试失败。如果PTLM产生的候选解决方案满足测试用例,那么我们只需向用户显示这些代码片段。根据我们的经验,对于大约30%-60%的情况,PTLM会生成正确的输出。对于其余情况,Jigsaw使用PTLM生成的候选解决方案作为起点,并使用简单的程序分析和合成技术对候选代码片段执行转换,以生成正确的解决方案。
正确性检查: 针对每个指定的I/O示例,我们运行候选代码片段的输入,并检查生成的输出是否与指定的输出一致。此外,我们可以使用静态分析来检查安全漏洞和其他错误。
变量名转换: 在某些情况下,PTLMs生成了准确的代码片段,但变量名称不正确。为了解决这个问题,我们利用来自多模态输入的信息,以及变量名称的范围,通过系统地搜索潜在的变量,并尝试变量名称的可能排列组合,以便通过测试用例。
参数转换:在某些情况下,PTLMs 生成了具有正确方法名称和方法序列的代码片段(在需要以嵌套方式或依次调用多个方法的情况下),但参数不正确。例如,对于查询“在‘location’中替换‘United States’为‘US’,并在‘zip’中替换‘3434’为‘4343’”,Codex 生成了:

这个片段调用了正确的 replace 方法,但错过了问题中的细节,即只有当这些值出现在列 'location' 和 'zip' 中时,才应该用 'US' 和 '4343' 替换 'United States' 和 '3434'。对于这个查询,Jigsaw 合成的正确代码如下所示:

AST-to-AST 转换:在某些情况下,我们发现 PTLM 生成的代码几乎正确,但有一个小错误。我们还发现,PLTM 反复犯这样的错误,并且可以通过适当的 AST-to-AST 转换进行修复,这些转换是从用户与 Jigsaw 的交互中学到的。作为具体示例,我们发现 GPT-3 经常会错过按位非运算符,并生成以下代码:

而不是使用按位非运算符的以下正确代码:

作为另一个例子,我们发现 GPT-3 错过了括号的使用,导致生成的代码引发异常。具体来说,生成的代码是:

而不是由 Jigsaw 合成的以下代码,其中括号使用正确:

这些错误无法通过变量名称转换或参数转换来修复。Jigsaw 通过学习 AST-to-AST 转换的重写规则来纠正这些错误。这些转换是从 BluePencil 中使用的语法的产生规则的应用。然而,从单个示例中学习这些规则的适当泛化级别是不可能的。为了实现这一点,我们收集用户交互数据,用户编辑 Jigsaw 生成的答案以产生正确的代码。我们对数据点进行聚类,以便将相似的数据点分组在一起,并学习一个能够处理聚类中所有数据点的单个 AST-to-AST 转换。结合上述聚类和扰动启发式方法,我们能够以适当的泛化级别学习转换。虽然 Jigsaw 目前仅适用于 Python 代码,但后处理步骤是在 AST 级别进行的,并且也可以跨编程语言使用。
2.4 从用户反馈中学习
Jigsaw的用户界面(集成到Jupyter笔记本中)被设计成让用户在Jigsaw错误的情况下提交正确的代码。通过吸收用户反馈,可以改进Jigsaw。具体来说,我们设计了更新上下文库的预处理模块和AST-to-AST转换的后处理步骤的技术,随着更多用户与Jigsaw互动,这些技术也会不断更新。

更新上下文库:我们根据算法1更新上下文库,该过程与用户查询相关。首先,我们检查Jigsaw是否已经为给定的查询找到了正确的解决方案。如果没有,我们检查Jigsaw生成的任何解决方案是否与某些正确代码“接近”(通过编辑距离和阈值确定)。如果满足这些条件之一,我们将新的查询添加到上下文库中,并确保不会重复类似的查询。随着使用量的增加,我们扩展上下文库,以覆盖不同风格的用户查询,并帮助选择相关的上下文。
更新转换:针对每个与正确代码片段配对的查询,我们选择由PTLM建议的所有不正确的代码,这些代码与正确代码之间的编辑距离很小。我们使用AST-to-AST转换学习子模块对选定的代码片段执行聚类(带扰动),并更新转换集。虽然上述预处理和后处理步骤是在Python Pandas API的背景下设计的,但我们相信,上下文选择、正确性检查和转换等思想是通用的,并且可以设计通用的预处理和后处理步骤,可以跨语言和API进行工作。对于每个API,可以从该API的用户生成的使用数据中学习特定的转换规则。
3 实验评估
3.1 离线评估
在表1中,我们展示了Jigsaw在PandasEval1和PandasEval2数据集上使用GPT-3和Codex作为黑盒PTLM的性能。表的第二列指示了PTLM的上下文选择策略。我们考虑了两种上下文选择策略:无上下文(不提供定制上下文,使用默认上下文:“import pandas as pd”)和变压器(基于变压器相似性的上下文选择)。每个策略都使用了4个上下文提示。表中的每个单元格都包含了平均值和标准偏差,以评估准确性。
表1:在PandasEval1和PandasEval2数据集上,Jigsaw管道的不同阶段后的性能(平均准确度±标准偏差)。Jigsaw的后处理步骤明显改善了PTLMs的性能,无论上下文选择策略如何。预处理明显受益,比较行1与2,以及行3与4。

对于Jigsaw,我们关注了两个方面的性能:变量名称转换和语义修复。前者指的是仅使用后处理模块的系统性能,后者指的是运行变量名称转换后再进行语义修复的系统性能。比较PTLM和语义修复列的结果表明,Jigsaw无论采用何种上下文选择策略,在准确性方面都比黑盒PTLM提高了15%-40%。这突显了基于程序分析的大型语言模型增强的效用。另外,我们发现为语言模型提供有用的上下文能显著提高准确性。TRANSFORMER上下文的PTLM相较于无上下文的PTLM可以提高约5%,并且对于Codex,后处理后的性能提高了高达15%。对于GPT-3,在PandasEval2数据集上使用TRANSFORMER上下文明显优于无上下文,在PandasEval1上则没有统计学显著差异。最后,我们观察到Jigsaw的后处理模块的有效性。变量名称转换模块可以显著提高Codex和GPT-3的性能。语义修复后处理模块也可以提高系统性能,尤其是针对Codex提高了约5%,对于GPT-3提高了6%-11%。这再次强调了使用程序分析技术来增强语言模型的重要性。具体到语义修复,我们发现仅使用参数转换模块可以提高系统性能,适用于GPT-3和Codex,分别提高了5%-9%和3%-5%。同样地,仅使用AST到AST转换模块可以使GPT-3提高3.5%,Codex提高1.3%的性能。
3.2 时间评估
在本节中,我们评估了Jigsaw在学习和改进用户反馈方面的能力。我们在PandasEval2数据集上进行了此评估。请记得黑客马拉松是在两个不同的会话中组织的;因此,我们使用了第一个会话中的任务提交和反馈,对应于PandasEval2_S1数据集,以便(a)更新我们的上下文库,(b)学习AST到AST的转换,并且(c)在PandasEval2_S2数据集上评估Jigsaw,该数据集包含PandasEval2_S1中任务的变体。
更新预处理模块:我们遵循算法1(其中“CODE”= 25,“BANK”= 0.15),并从第一个会话的用户中过滤出写得不好的查询。请注意,对于在两个会话中相同的3个任务,我们不会对上下文库进行任何更新。我们用CS1表示我们在第一个会话中使用的种子上下文库(包含243个问题-答案对),用CS2表示根据算法1更新的更新后的上下文库(包含371个(243个种子+ 128个新)问题-答案对)。
更新后处理模块:我们从第一个会话数据中学习AST到AST的转换,以及种子数据。我们使用TS1来表示在第一个会话期间种植的转换,并使用TS2来表示从第一个会话数据中学习的新/更新的转换。
表2:Jigsaw在PandasEval2数据集上通过学习上下文库和来自用户反馈的转换(CS1-TS1和CS2-TS2)的性能(平均准确度±标准偏差)。通过比较第3列和第4列,学习有助于显着提高准确性。

我们在表2中将Jigsaw在PandasEval2_S1上(使用CS1和TS1)与PandasEval2_S2上(使用基线CS1和TS1,以及更新后的上下文库CS2和转换TS2)的表现进行比较。表中的每个单元格都是相应数据集上的平均准确度和标准偏差。有两点观察结果。
(1)学习有助于改进Jigsaw。显然,使用默认的CS1-TS1设置(第3列)在PandasEval2_S2数据集上的Jigsaw性能明显低于使用更新的CS2-TS2设置(第4列)对于两种PTLM都是如此。由于更新的模块,使用GPT-3的系统的准确性提高了30%以上;即使对于已经在所有数据集上表现良好的Codex,我们仍然通过更新提高了约15%。
(2)第二个会话总体上更具挑战性。我们还观察到,使用默认的CS1-TS1设置(第3列)在PandasEval2_S2上的性能明显低于在相同设置下(第2列)的PandasEval2_S1上。这是因为总体而言,第二个会话更具挑战性;部分原因是因为在困难任务的查询百分比更高,以及跨两个会话的任务之间的语义差异。但是当我们使用更新的上下文和转换库时,我们发现在PandasEval2_S2上的性能显着提高,如上所述(1)。这说明了Jigsaw有能力从用户反馈中改进,无论使用的是哪种PTLM。最后,我们还查看了任务完成度指标,以评估从反馈中学习的性能增益如何转化为黑客马拉松期间用户体验。在第一个会话中,用户平均只能解决71%的任务;然而,在第二个会话中,用户平均能解决82%的任务,从而使Jigsaw系统的体验随着更新变得更加高效。
3.3 与AutoPandas的比较
AutoPandas(AP)是一个能够生成包含两个或三个Pandas函数的程序的Pandas程序合成引擎。它使用生成器来枚举Pandas API,并借助图神经网络(GNNs)对输入输出(I/O)数据帧进行搜索引导,并返回最有可能的函数序列和参数。
相比之下,我们利用多模式规范(自然语言查询和I/O示例)。根据示例进行编程已知存在模糊的不完全规范化。根据我们的经验,对于提供多种实现相似功能的大型API,这个问题会变得更加严重。如果我们只考虑给定任务的I/O示例,我们可以找到许多仅删除或选择数据帧中某些行的平凡解决方案。
我们在我们的PandasEval1和PandasEval2数据集上评估AP。AP不支持系列操作、列分配和字典或列表生成器,其中许多在Pandas工作流中是必需的。因此,在PandasEval1数据集的68个任务和PandasEval2数据集的21个任务中,分别仅覆盖了7个和20个任务。因此,我们仅在这27个任务上将使用Codex PTLM实例化的Jigsaw与AP进行比较,并使用3分钟的超时时间。
表3:Jigsaw和AP在受AP支持的我们数据集的子集以及它们的数据集上解决的任务数量。

在表3的第一行中,我们看到,即使在仅由AP可解的受限子集中,Jigsaw的性能明显优于AutoPandas。这是因为如果仅使用I/O示例,则27个任务中的16个是不完全规范的,而且AP在其中许多任务上返回过拟合解决方案;这凸显了多模式的必要性。
我们还在AP数据集[9]上运行Jigsaw,该数据集中所有任务都受AutoPandas支持,并且I/O示例足够。此数据集已从StackOverflow帖子中获取。由于Jigsaw使用文本作为主要输入,我们在这些帖子中添加了自然语言描述以查询Codex。结果在表3的第二行中;虽然单独的Codex不及AP,但Jigsaw(与Codex一起)的表现优于AP。
3.4 消融研究
在前面的子节中,我们在离线和时间评估中固定了上下文提示的数量为4,并将TRANSFORMER作为预处理模块中的上下文选择器。在这个消融研究中,我们询问Jigsaw的性能是否对这些选择敏感,并提供相同选择的理由。
表4:消融研究:Jigsaw在两种上下文选择策略下的性能。
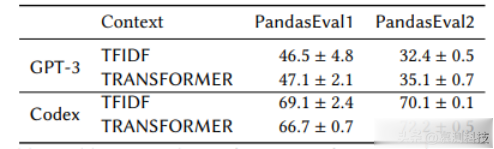
表5:消融研究:Jigsaw在不同数量的上下文提示下的性能。
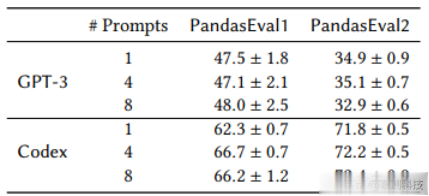
表4比较了Jigsaw在两种不同的上下文选择策略(即TFIDF和TRANSFORMER)下的性能。我们发现transformer上下文选择器略优,但更重要的是,Jigsaw的性能对选择策略不敏感。表5比较了Jigsaw在不同数量的上下文提示示例下的性能,即1、4和8。我们的实验表明,虽然4个提示与8个提示的性能之间没有显著差异,但两者都优于仅使用1个提示。再次强调,Jigsaw对这些选择相对稳健。
最后,注意到这些选择的所有变化,无论是提示数量还是选择策略,都优于NO-CONTEXT设置(见表1);这进一步强调了预处理模块的实用性。
3.5 超越Pandas
为了测试Jigsaw的通用性,我们进行了一项初步评估,使用了来自TF-coder和在线论坛(如StackOverflow)的25个TensorFlow任务。我们设置了与离线评估类似的Jigsaw预处理模块,通过从文档页面创建一个包含25个提示的上下文库来实现。我们重复使用变量名称模块,并手动进行参数和树转换的假设分析。表8显示了Jigsaw在TensorFlow数据集上的性能。从表中可以看出,单独的Codex只能解决25个任务中的8个,变量转换将性能提高到15个任务。我们手动比较了代码输出和预期输出,以检查参数和树转换是否可以学习。根据这一分析,我们发现语义修复有可能将性能提高到19个任务。我们以下列一些例子。
对于查询“给定张量in1,在其中替换所有的1为0”,PTLM输出如下:

使用变量转换,由Jigsaw合成的此查询的正确代码如下所示:

对于查询“给定张量in1和索引张量ind,在张量in1中获取索引ind处的元素之和”,PTLM输出了以下错误代码:

如果从使用中收集到足够的数据点,Jigsaw可以通过学习AST到AST转换来合成如下所示的正确代码:

总之,这表明所提出的预处理和后处理模块是有用的,并且也可以推广到其他库和编程语言。
转述:拓紫苑
