在学习和工作中,我们经常需要使用日志来记录程序的运行状态和调试信息。而为了更好地区分不同的日志等级,我们可以使用不同的颜色来呈现,使其更加醒目和易于阅读。
在下图运行结果中,我们使用了 colorlog 库来实现彩色日志输出。通过定义不同日志等级对应的颜色,我们可以在控制台中以彩色的方式显示日志信息。例如,DEBUG 级别的日志使用白色,INFO 级别的日志使用绿色,WARNING 级别的日志使用黄色,ERROR 级别的日志使用红色,CRITICAL 级别的日志使用蓝色。

但是在查看日志文件时,我们会发现日志信息是系统默认的字体颜色,并且前后多了一些特殊符号,例如 [32m 等。这是因为在控制台中使用的是 ANSI 转义序列来实现彩色文本效果,而这些特殊符号是 ANSI 转义序列的一部分。如下图所示:

现在有一个需求,在前端页面直接查看日志内容并还原彩色文本效果,因此,我们将进行以下内容讲解:
什么是 ANSI 转义序列?如何在前端页面直接查看日志内容?如何在前端页面还原彩色文本效果?本文代码点击此处跳转,往期系列文章请访问博主的 项目实战专栏,博文中的所有代码全部收集在博主的 GitHub 仓库中;
ANSI 转义序列ANSI 转义序列是美国国家标准化组织(American National Standards Institute,ANSI)制定的标准,是一种用于控制文本终端显示的特殊字符序列。它们以 \033[ 开头,以字母和数字组合的形式表示不同的控制功能。
ANSI 转义序列可以用于控制文本的颜色、背景色、文本样式(如粗体、斜体等)、光标位置、清屏等操作。通过在输出文本中插入适当的 ANSI 转义序列,可以实现丰富的终端显示效果。
以下是一些常用的 ANSI 转义序列示例:
\033[0m:重置所有属性,恢复默认设置;\033[31m:设置文本颜色为红色;\033[42m:设置背景颜色为绿色;\033[1m:设置文本为粗体;\033[4m:设置文本为下划线;\033[2J:清屏;需要注意的是,ANSI 转义序列在不同的终端和操作系统上的支持程度可能会有所不同。在某些终端中,可能无法正确解释和显示 ANSI 转义序列。
我们以 \033[31m 和 \033[42m 为例,输出一个绿底红字的句子 Hello World! --sidiot.,代码如下所示:
log.debug("\033[42m\033[31mHello World! --sidiot.\033[0m\033[0m")运行结果:
 前端页面直接查看日志内容
前端页面直接查看日志内容这里的话,我们使用 Python 的 http.server 模块来启动一个简单的 HTTP 服务器。
比较快捷的方式就是在日志文件夹中打开终端,输入 python -m http.server 8888 即可,运行结果如下所示:
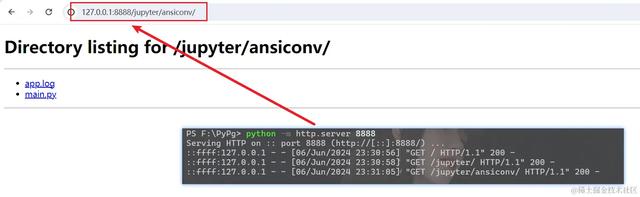
不过这种方式相对来说还是不太安全的,因此我们可以通过设置白名单的方式,来规避一些潜在的安全隐患,代码如下所示:
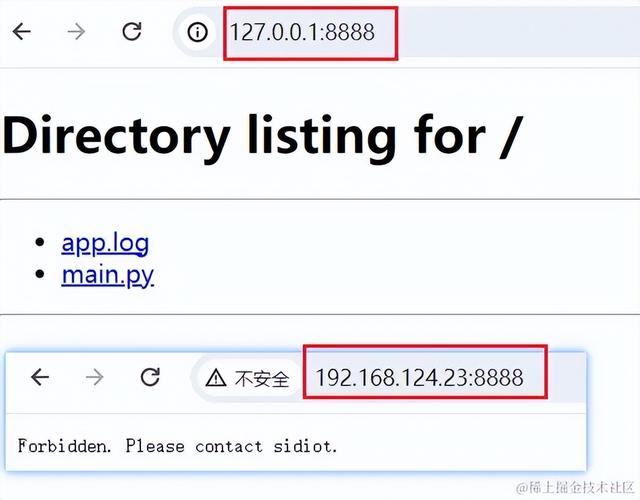
import http.serverimport socketserverclass HTTPRequestHandler(http.server.SimpleHTTPRequestHandler): def check_client_address(self): # 设置白名单,只允许特定的IP地址或主机访问 whitelist = ['127.0.0.1', 'localhost'] client_address = self.client_address[0] if client_address not in whitelist: self.send_response(403) self.end_headers() self.wfile.write(b'Forbidden. Please contact sidiot.') return False return True def do_GET(self): if not self.check_client_address(): return super().do_GET()with socketserver.TCPServer(('0.0.0.0', 8888), HTTPRequestHandler) as httpd: httpd.serve_forever()目前本机的 IP 为 192.168.124.23,当我们以 127.0.0.1 来访问 8888 服务端口时,访问是成功的,但是当我们用 192.168.124.23 来访问服务端口时,访问是失败的。
运行结果:
现在我们点击文件,它会直接通过浏览器直接下载,但是我们需要的是在网页上能够直接阅览文件中的内容,因此我们可以从 do_GET() 下手。
我们可以设计一个根据传入的文件名参数,读取本地文件并作为响应结果进行返回的方法,然后根据一定的规则进行触发,代码如下所示:
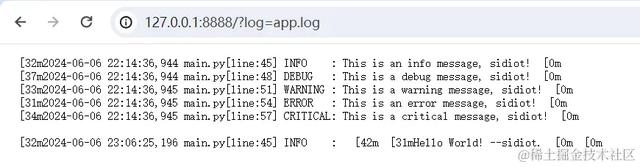
def read_file(self): try: self.send_response(200) self.send_header("Content-Type", "text/plain; charset=utf-8") self.end_headers() self.wfile.write(open(self.path[6:], 'rb').read()) except FileNotFoundError: self.send_response(404) self.end_headers() self.wfile.write(b'File not found!')def do_GET(self): if self.check_client_address(): if self.path.startswith("/?log="): self.read_file() else: super().do_GET()上述代码通过检查请求的资源路径来处理 GET 请求。如果请求的资源路径前缀是 /?log=,且是当前目录下存在的日志文件,它会读取文件并将其内容作为响应发送。否则,它会使用基类的默认行为处理普通的 GET 请求。
运行结果:
至此,我们已经实现了前端页面直接查看日志内容的功能。
前端页面还原彩色文本效果原理分析
当我们想要在前端页面展示 ANSI 字体的彩色效果时,我们只需要简单地将 ANSI 转义序列转换成相应的 HTML 代码就可以实现了。这个转换过程实际上可以通过编写一个 Python 函数来实现,该函数可以接受包含 ANSI 控制码的字符串作为输入,并将其转换为带有相应样式的 HTML 代码输出,代码如下所示:
def convert_ansi_to_html(ansi_text): ansi_to_html = { '\x1b[31m': '<span style="color: red;">', '\x1b[42m': '<span style="background-color: green;">', ..., } html_text = re.sub(r'\x1b[[0-9;]*m', lambda match: ansi_to_html.get(match.group(0), ''), ansi_text) return html_textif __name__ == '__main__': ansi = "\033[42m\033[31mHello World! --sidiot.\033[0m\033[0m" print(ansi) html = convert_ansi_to_html(ansi) print(f"convert content: {html}")需要注意的是,在 ANSI 转义序列中,\x1b 和 \033 都代 表ASCII 码中的 Escape 字符,用于开始一个转义序列。
运行结果:

使用 ansiconv 转换
接下来,我们借助已有的库函数 ansiconv 进行 ANSI 的转换。
通过 pip 进行安装:
pip install ansiconv根据 ansiconv 的官方文档使用其中的三个方法 to_plain(),to_html() 和 base_css() 来实现在前端页面展示 ANSI 字体的彩色效果,代码如下所示:
import ansiconvansi = "\033[42m\033[31mHello World! --sidiot.\033[0m\033[0m"print(f"Ansi: {ansi}")plain = ansiconv.to_plain(ansi)html = ansiconv.to_html(ansi)print(f"Convert Plain: {plain}")print(f"Convert HTML: {html}")在 base_css() 中会有相关的 CSS 映射表,如下所示:
css_rule('.ansi31', color="#FF0000"),css_rule('.ansi42', background_color="#00FF00"),运行结果:

研究 ansiconv 源码
我们将通过研究 ansiconv 的源码,以便深入了解它是如何将 ANSI 转换成纯文本或 HTML 代码的工作原理。
to_plain() 的源码如下所示:
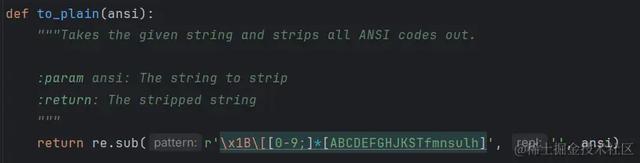
上述代码使用正则表达式匹配字符串中的 ANSI 转义序列,并将其替换为空字符串,从而得到不包含转义序列的纯文本。
正则表达式的含义如下:
\x1B:匹配 ESCAPE 字符;\[:匹配左方括号;[0-9;]*:匹配零个或多个数字或分号;[ABCDEFGHJKSTfmnsulh]:匹配 ANSI 转义序列中的控制字符;我们通过 re.findall() 方法来获取所有匹配的结果,这样够清晰地捕获所有符合条件的匹配项,从而更好地理解 ansiconv 是如何进行 ANSI 到纯文本的转换,代码如下所示:
ansi = "\033[42m\033[31mHello World! --sidiot.\033[0m\033[0m"print(re.findall(r'\x1B[[0-9;]*[ABCDEFGHJKSTfmnsulh]', ansi))运行结果:

to_html() 的源码如下所示:
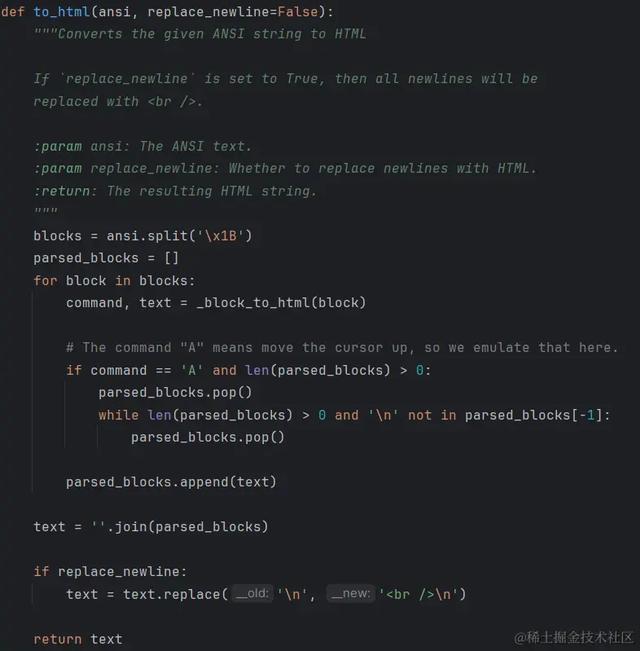
上述代码将 ANSI 字符串分割成块,并对每个块调用 _block_to_html() 函数进行解析和转换,同时还处理了 ANSI 命令 "A",模拟向上移动光标的行为。如果 replace_newline 为 True,则 HTML 字符串中的换行符 \n 将替换为 <br />\n 以保留 HTML 输出中的换行符。
其中 _block_to_html() 的源码如下所示:
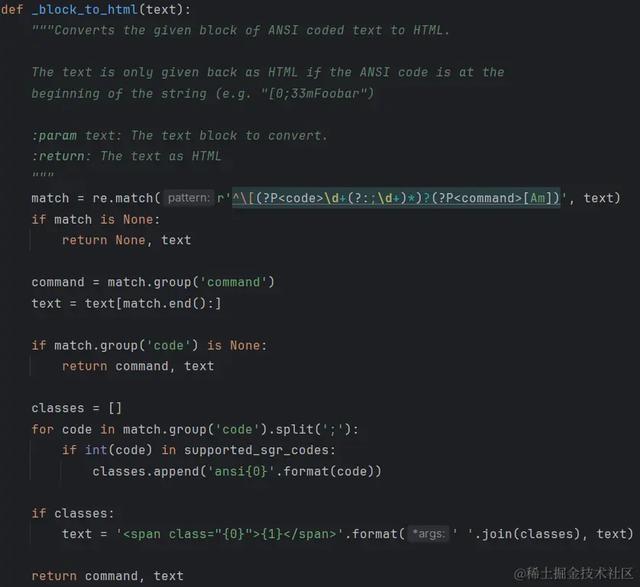
上述代码使用正则表达式匹配 ANSI 代码,并根据匹配结果生成对应的 HTML 代码。
正则表达式的含义:
^:表示匹配字符串的开头。\[:匹配左方括号 [。(?P<code>\d+(?:;\d+)*)?:这是一个命名捕获组,用于匹配 ANSI 代码中的数字部分。它由以下组成: \d+:匹配一个或多个数字。 (?:;\d+)*:这是一个非捕获组,用于匹配分号 ; 和一个或多个数字的重复出现。(?: ... ) 表示非捕获组,* 表示重复零次或多次。(?P<command>[Am]):这是另一个命名捕获组,用于匹配 ANSI 代码中的命令部分。它由以下组成: [Am]:匹配字符 A 或 m。我们可以通过运行源码里的部分代码来帮助理解,代码如下所示:
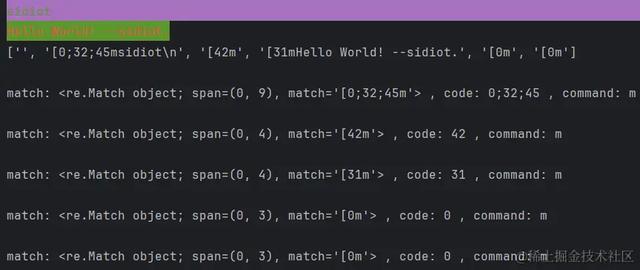
text = ("\x1B[0;32;45msidiot\n" "\033[42m\033[31mHello World! --sidiot.\033[0m\033[0m")print(text)blocks = text.split('\x1B')print(blocks)for block in blocks: match = re.match(r'^[(?P<code>\d+(?:;\d+)*)?(?P<command>[Am])', block) if match is not None: print("\nmatch:", match, ", code:", match.group('code'), ", command:", match.group('command'))运行结果:
实际应用
通过深入理解 ANSI 转换思路和 ansiconv 源码,我们可以为之前的 http.server 服务带来全新的优化。
首先,将原先的 read_file() 方法进行优化,代码如下所示:
def read_file(self, content_type, file_io): try: self.send_response(200) self.send_header("Content-Type", f"{content_type}; charset=utf-8") self.end_headers() self.wfile.write(file_io) except FileNotFoundError: self.send_response(404) self.send_header("Content-Type", "text/plain; charset=utf-8") self.end_headers() self.wfile.write(b'File not found!')上述代码通过接收 content_type 和 file_io 两个参数,实现将自定义内容作为响应返回给客户端。
然后修改请求路径,使其能够返回纯文本和 HTML 两种不同类型的内容,代码如下所示:
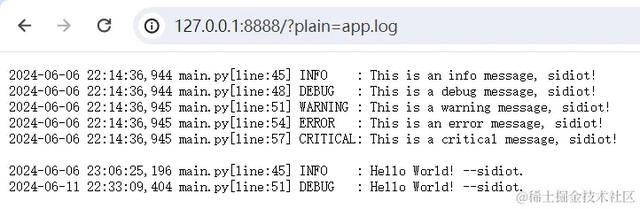
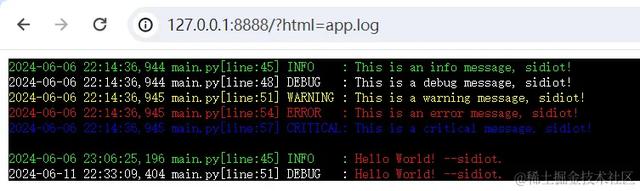
def do_GET(self): if self.check_client_address(): if self.path.startswith("/?plain="): file = open(self.path[8:], 'rb').read() plain = ansiconv.to_plain(file.decode('UTF-8')) self.read_file("text/plain", plain.encode()) elif self.path.startswith("/?html="): file = open(self.path[7:], 'rb').read() conv = ansiconv.to_html(file.decode('UTF-8')) css = ansiconv.base_css() html = """ <html> <head><style>{0}</style></head> <body> <pre>这里要注意的是,需要设置 CSS 样式,不然 类是无法进行渲染的。纯文本运行结果:
HTML 运行结果:
 后记
后记在本文中,我们探讨了如何实现将 ANSI 字体在前端页面进行彩色展示的方法。在前端页面中直接显示 ANSI 转义序列是不起作用的,因为浏览器不会解析和处理这些转义序列。
为了在前端页面实现彩色展示,我们介绍了一种方法,即将 ANSI 转义序列转换为对应的 HTML 代码。通过解析 ANSI 转义序列并将其转换为适当的 HTML 标签和样式,我们可以在前端页面上还原彩色文本的效果。
在本文中,我们使用了 Python 中的 ansiconv 库来实现 ANSI 转换。该库提供了 to_plain 和 to_html 两个方法,分别用于将 ANSI 转义序列转换为纯文本和 HTML 代码。我们还展示了如何使用这些方法来转换 ANSI 字符串,并在前端页面上显示转换后的结果。
通过本文的介绍,读者可以了解到如何在前端页面实现彩色文本的展示,从而提升用户体验和可读性。无论是在日志查看器、终端模拟器还是其他需要展示彩色文本的应用中,这种技术都能发挥重要作用。
以上就是 从终端到浏览器:实现 ANSI 字体在前端页面的彩色展示 的所有内容了,希望本篇博文对大家有所帮助!欢迎大家持续关注我的博客,一起分享学习和成长的乐趣!✨
作者:sidiot链接:https://juejin.cn/post/7381820436274184202
