最近发布在medRxiv*预印本服务器上的一项研究显示,研究人员评估了ChatGPT 3.5版和4版在回答心力衰竭相关问题时的准确性和再现性。

背景
研究人员估计,到2030年,美国每年与心力衰竭相关的医疗费用支出将达到700亿美元左右。其中约70%的费用支出来自住院,占美国所有住院人数的1-2%。多项研究表明,患者掌握的心脏病管理知识越多,其住院时间往往越短。
人们越来越喜欢使用网络来获取健康信息,每天谷歌上都有近10亿个与医疗保健相关的问题搜索。近期,聊天生成预训练转换器(ChatGPT)受到了大家的追捧。
该研究
在该研究中,研究人员从权威医疗组织和脸书支持团体收集了125个关于心力衰竭的常见问题。经过仔细评估,排除了18个内容重复、措辞模糊或没有阐述患者观点的问题。
然后,剩余的107个问题使用“新聊天”功能两次输入到两个版本的ChatGPT中,让每个版本都对每个问题生成两个回答。
为了评估回答的准确性,两名委员会认证的心脏病专家使用由四类组成的量表对其进行了独立评分,包括全面、正确但不充分、部分正确和部分不正确以及完全不正确。对ChatGPT-3.5和ChatGPT-4的回答都进行了该评估过程。还通过比较每个模型中每个问题的两个回答的综合得分和准确性得分来评估回答的再现性。
评审员之间的任何评分差异都由第三位评审员解决,第三位评审员是一位拥有20多年临床经验的委员会认证的晚期心力衰竭专家。
研究结果
对两个ChatGPT模型回答的评估显示,大多数回答被认为是“全面”或“正确但不充分”。与ChatGPT-3.5相比,ChatGPT-4在“管理”和“基础知识”类别中的综合知识显得更有深度。

ChatGPT-3.5在“其他”类别中的表现更好,包括支持预后和手术等主题。例如,关于钠-葡萄糖协同转运蛋白-2(SGLT2)抑制剂对心脏的益处,ChatGPT-3.5提供了一般答案,而ChatGPT-4提供了关于这些药物对利尿和血压影响的更详细但简洁的答案。
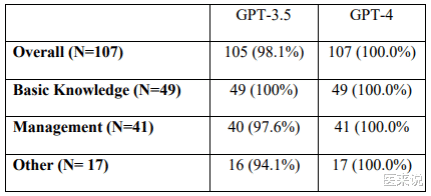
来自ChatGPT-3.5的回答中,约2%被评为“部分正确和部分不正确”,而来自ChatGPT-4的回答没有一个被归类于“部分正确和部分不正确”或“完全不正确”。在检查再现性时,两个模型对大多数问题都提供了一致的回答,ChatGPT-3.5版本在所有类别中的得分都超过94%,ChatGPT-4的所有回答都实现了100%的再现性。
结论
该研究显示,在回答心力衰竭相关问题方面,ChatGPT-4的表现优于ChatGPT-3.5,能提供更全面的回答,且没有任何错误回答。这两个模型在大多数问题上都表现出很高的再现性。这些发现表明,大型语言模型(LLM)在为患者提供可靠和全面信息方面具有惊人能力和快速发展。
ChatGPT有潜力成为心脏病患者的宝贵资源,在医疗保健提供者的指导下为他们提供知识。ChatGPT拥有对用户友好的界面和类似人类的对话反应,可以吸引相关患者将其用于健康相关信息的搜索。通过改进培训,ChatGPT-4提高了相关性能,这种培训的重点是更好地理解用户意图和处理复杂场景。
虽然ChatGPT在这项研究中表现良好,但仍存在重要局限性。偶尔情况下,该模型可能会提供不准确但可信的回答,有时甚至是荒谬的回答。
出处:
[1]News-Medical.Net
[2]Preliminary scientific report. King, R., Samaan, J. S., Yeo, Y. H., et al. (2023). Appropriateness of ChatGPT in answering heart failure related questions. medRxiv. doi:10.1101/2023.07.07.23292385.
