DINOv3正式发布,推动自监督视觉基础模型迈上新台阶🦖
核心亮点:
• 7B参数ViT大模型及多款蒸馏小模型,兼顾性能与效率
• 在17亿张无标注图像上训练,完全摆脱人工注释依赖
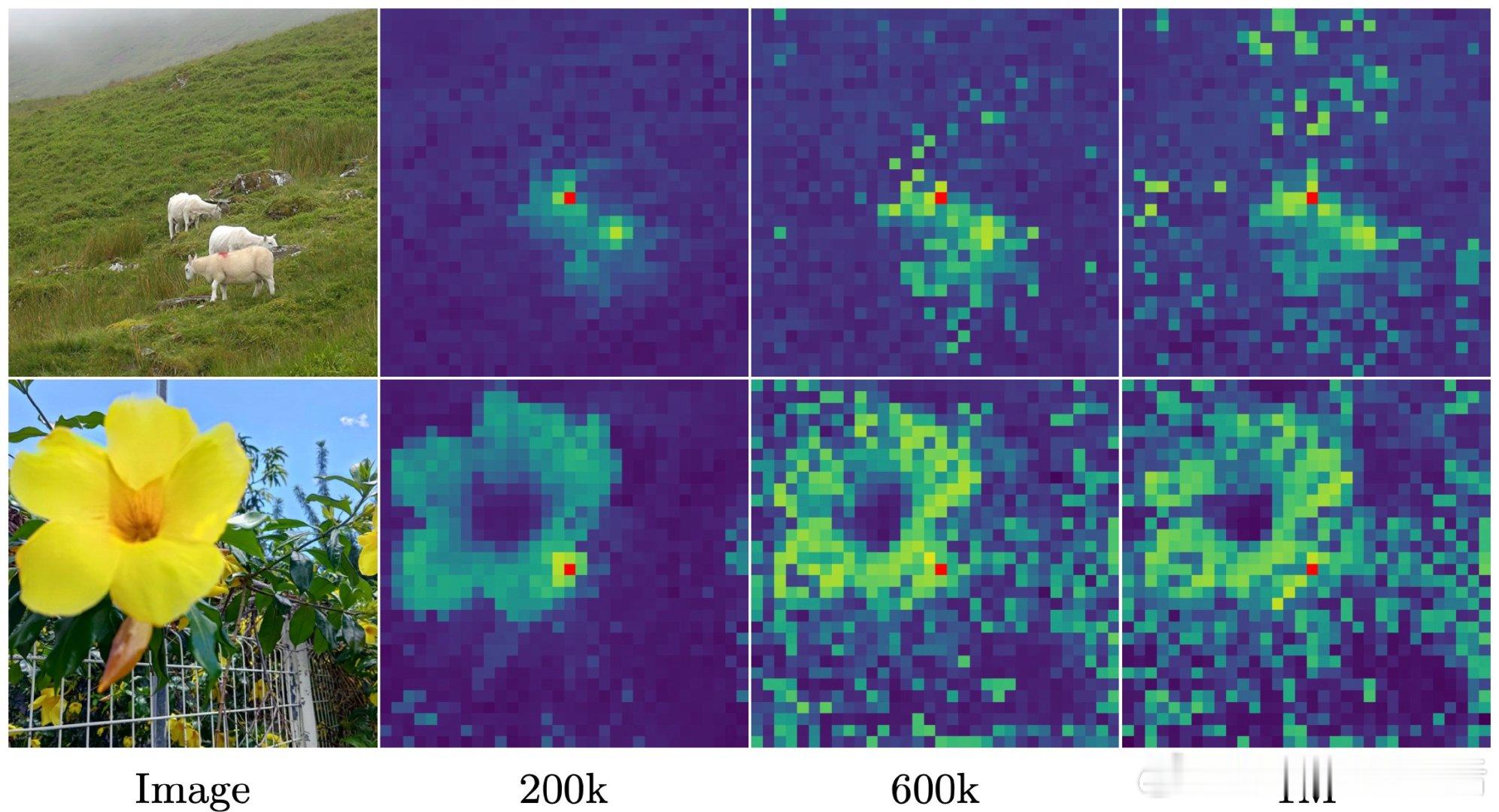
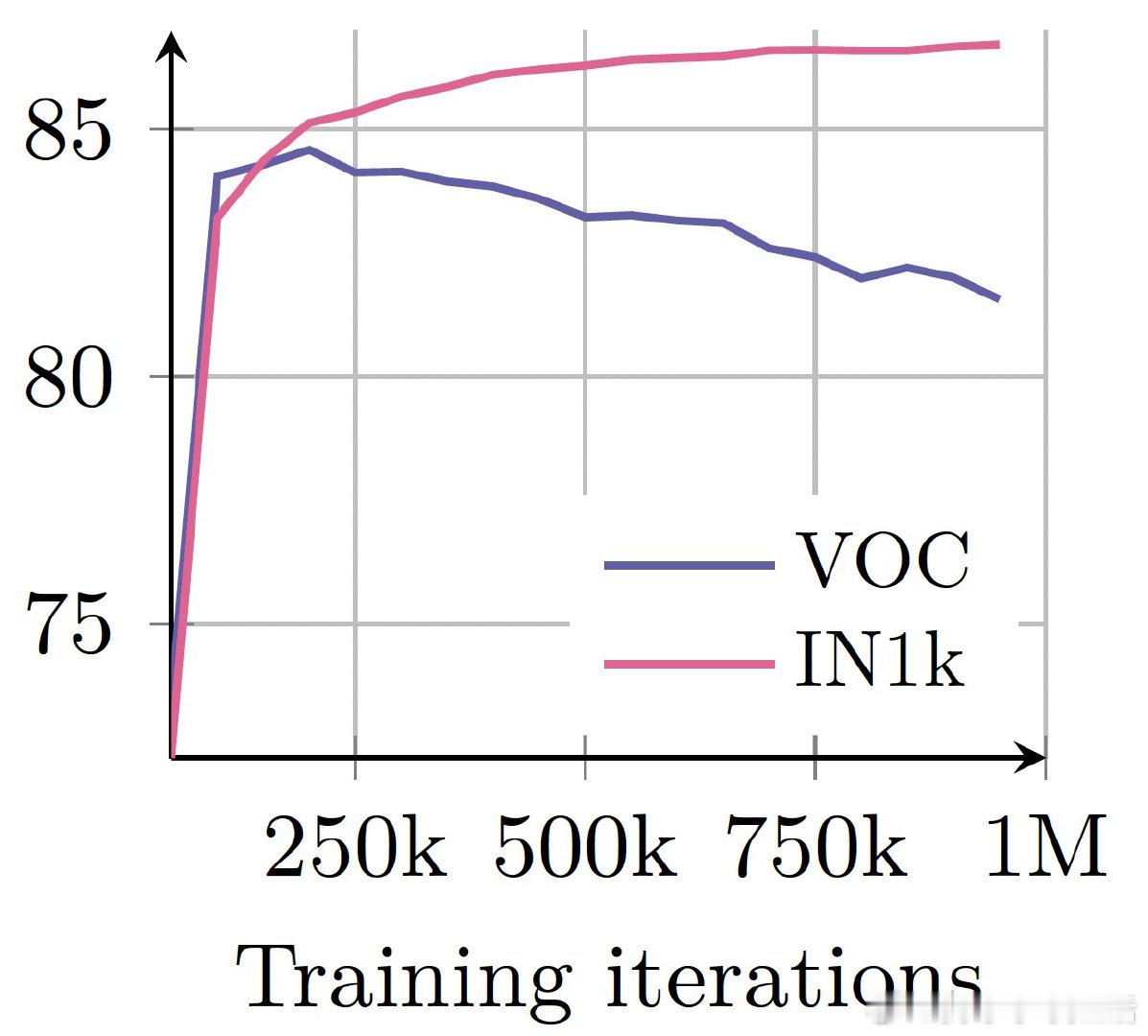
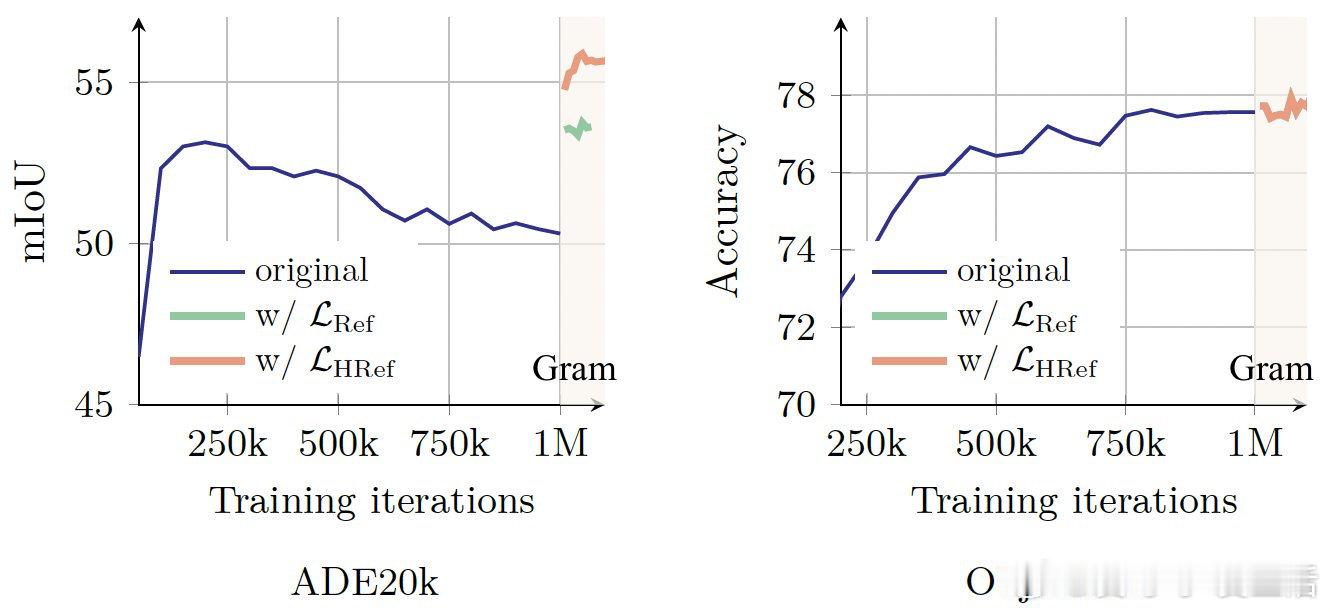
• 创新Gram Anchoring技术,有效解决大模型长时间训练中密集特征退化问题
• 支持高分辨率适配(最高4K),引入相对空间坐标和二维RoPE,提升细节表达
• 特征图稳定、无边缘伪影,物体分割效果接近聚类级别
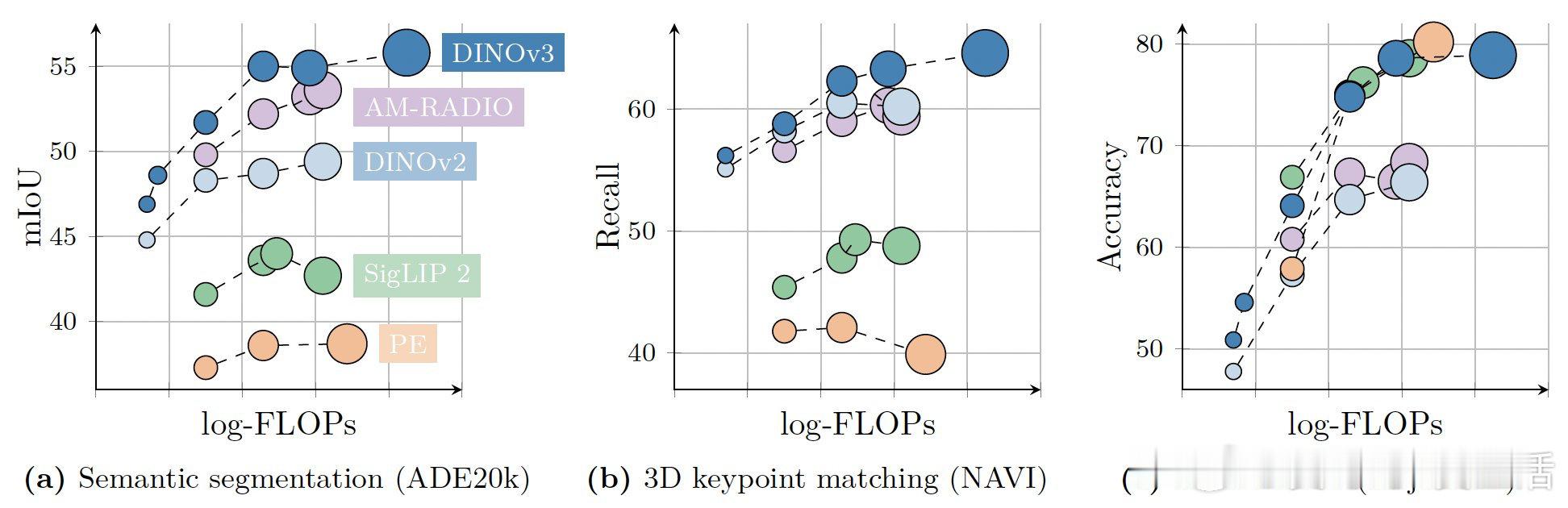
• 冻结骨干网络即可实现出色下游表现:COCO目标检测mAP 66.1,ADE20k线性分割mIoU达55.9,视频跟踪J&F 83.3
• 模型家族丰富:ViT-7B主力,ViT-S/B/L/H+多规格,ConvNeXt变体适配资源受限场景,支持文本对齐ViT-L(dino.txt)
• 跨域泛化能力强,卫星图像任务(冠层高度估计、土地覆盖分类)刷新SOTA
实际应用:
自动驾驶车辆识别环境、工业机器人视觉感知、农业精准施肥、手机图像场景识别、环境监测与灾害响应等多领域均可受益。
开源资源:
• 训练、评估代码及示例notebooks:github.com/facebookresearch/dinov3
• HF Transformers预训练模型合集:huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
• 详细技术博客:ai.meta.com/blog/dinov3-self-supervised-vision-model
• 论文全文:ai.meta.com/research/publications/dinov3
自监督学习 计算机视觉 深度学习 基础模型 视觉Transformer 卫星遥感 目标检测 语义分割 AI开源