GPT5看X光片超越医生医学多模态AI超越人类
GPT-5的多模态能力,已经强到比医生还会看X光片了。
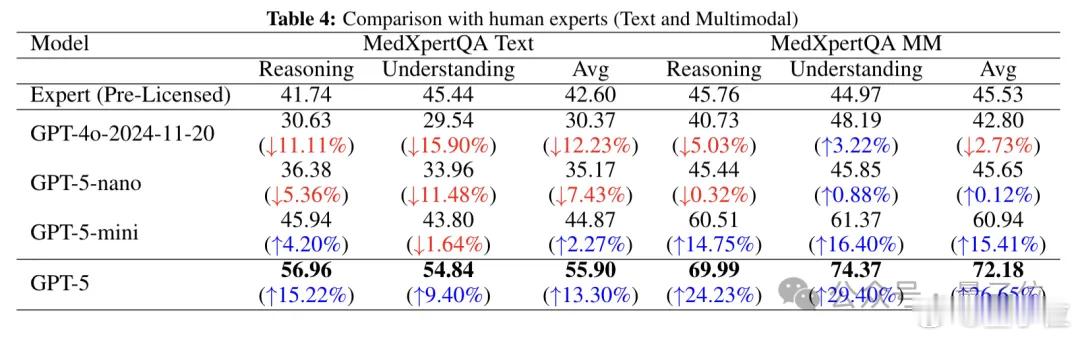
来自埃默里大学医学院的一项研究显示:GPT-5在医学影像推理准确率比人类医生高出24.23%,理解力更是领先29.40%。
怎么测试的?
研究团队找来了GPT-5、GPT-4o以及两个轻量版模型(GPT-5-mini、GPT-5-nano),在三个标准测试上展开对比:
1. USMLE:美国医师执照考试,纯文本问答,考察基础知识与临床推理;
2. MedXpertQA:4460道题目,包含文本+影像的多模态医学知识与推理测试;
3. VQA-RAD:医学图像问答,测试图像理解与文字生成能力。
结果显示,GPT-5全面胜出,尤其在MedXpertQA的多模态子集中,推理和理解力分别领先GPT-4o近30%,全面超越人类专家。
为什么GPT-5这么强?
团队认为关键在于GPT-5的“原生多模态架构”:
- 不再像GPT-4o那样依赖图像→文字→再推理的流程;
- 而是将图像、文本统一编码处理,通过共享向量空间与跨模态注意力机制,实现感知、理解与推理的闭环。
这样,GPT-5就能直接把图像中的细节和医学知识结合起来分析,推理链更完整,信息损耗更小。
在像USMLE Step 2这样需要“多步推理”的任务中,GPT-5还能结合“思维链提示”,表现出超强的临床决策能力。
但它能代替医生吗?
目前还不行。研究团队也特别指出:
- 实验场景是标准化测试题,和真实医院里患者情况千差万别不同;
- 在一个真实世界的医学影像挑战中(含X光、CT、MRI),GPT-5的表现依然比不上实习医生,更别说有经验的放射科专家。
医生们也表示:“AI确实进步很快,但要真正落地诊室,还早得很。”
感兴趣可查阅论文原文:arxiv.org/abs/2508.08224



![网友们都是看人下菜碟啊[大笑]昨天莎莎赢下伊藤后,马琳和莎莎同时下场,每次](http://image.uczzd.cn/8416208981410914980.jpg?id=0)