[LG]《Learning In-context n-grams with Transformers: Sub-n-grams Are Near-stationary Points》A Varre, G Yüce, N Flammarion [EPFL] (2025)
深入解析transformers在in-context学习n-gram语言模型中的损失地形,揭示阶段性学习与训练平台期的本质成因:
• 研究聚焦于in-context下基于cross-entropy损失的n-gram预测,建立了参数配置的充分驻点条件,指出模型得分函数若仅依赖输入子序列,则该配置为驻点。
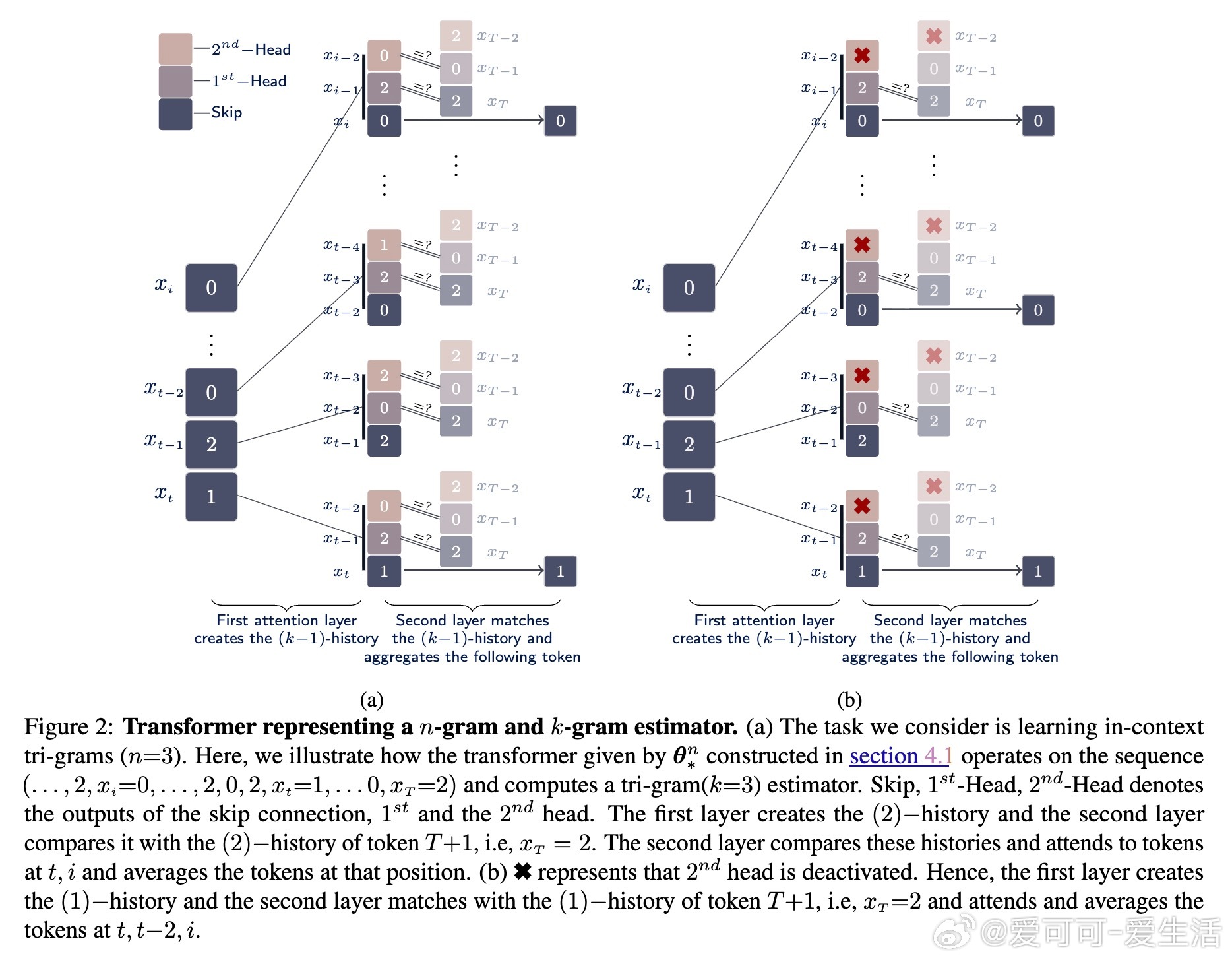
• 构造简化的disentangled transformer参数,实现k-gram估计器(k ≤ n),证明在序列长度与参数范数趋于无穷时,梯度趋近零,表明子n-gram对应的解为近驻点。
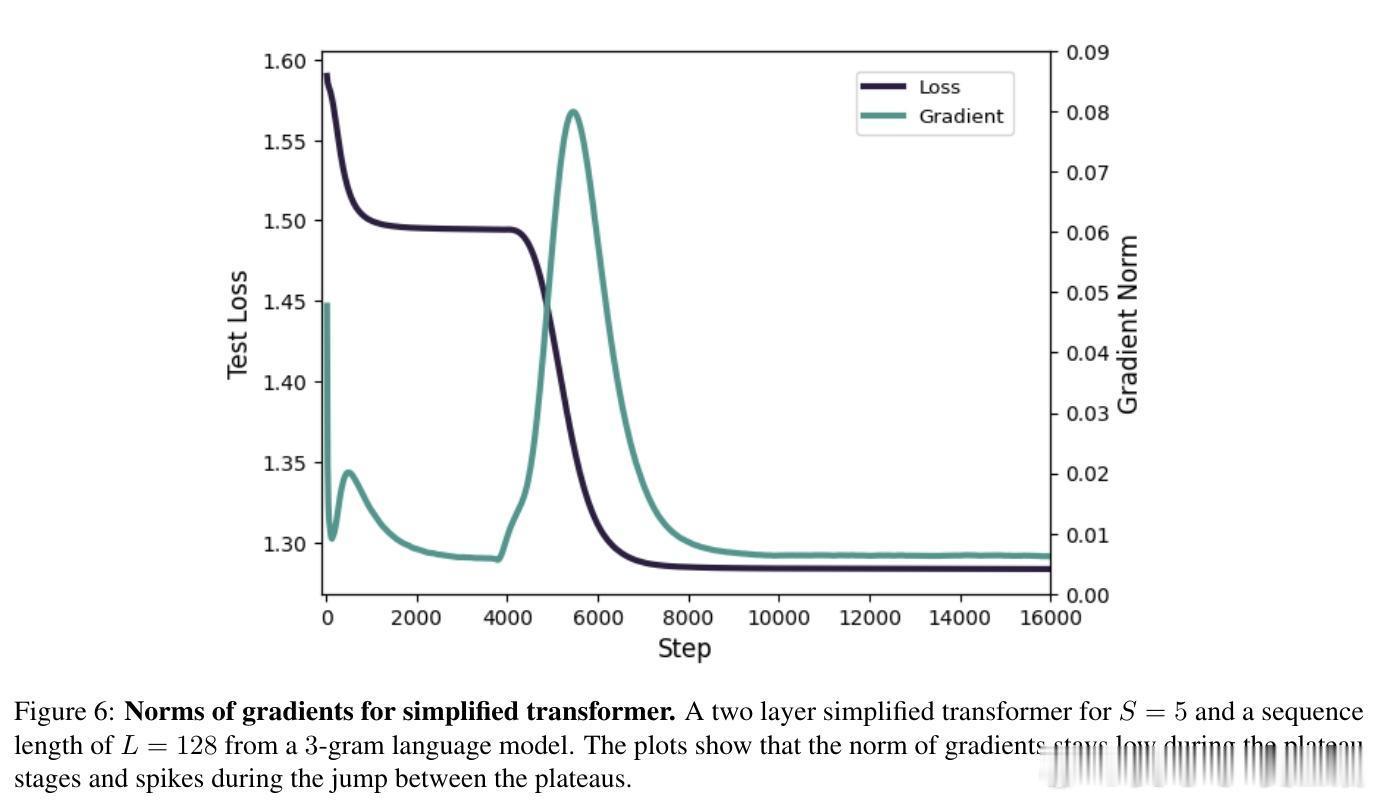
• 理论解释了训练中普遍观察到的阶段性跃迁和平台期现象:模型在学习更复杂依赖前,会在较简单的子n-gram解附近停留。
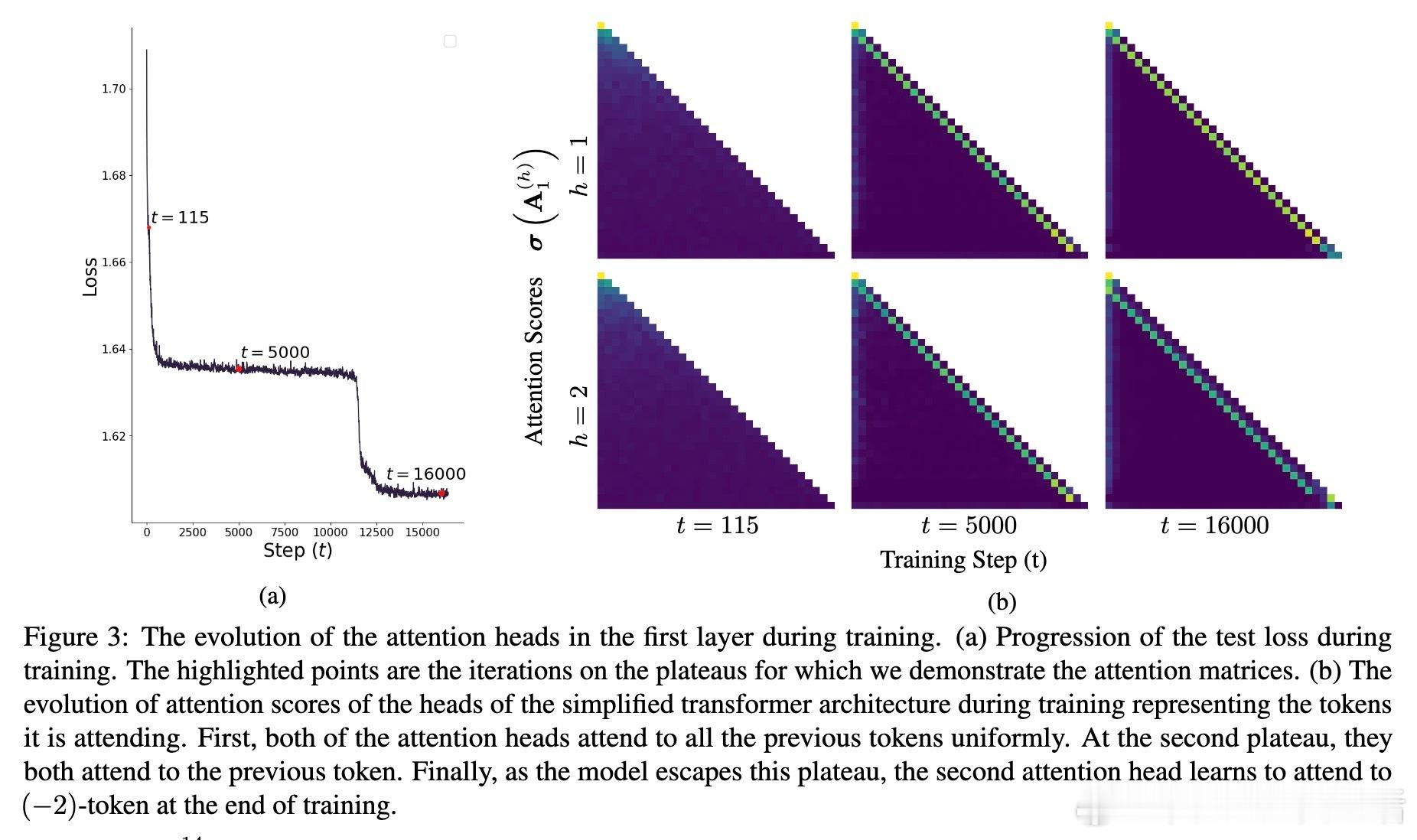
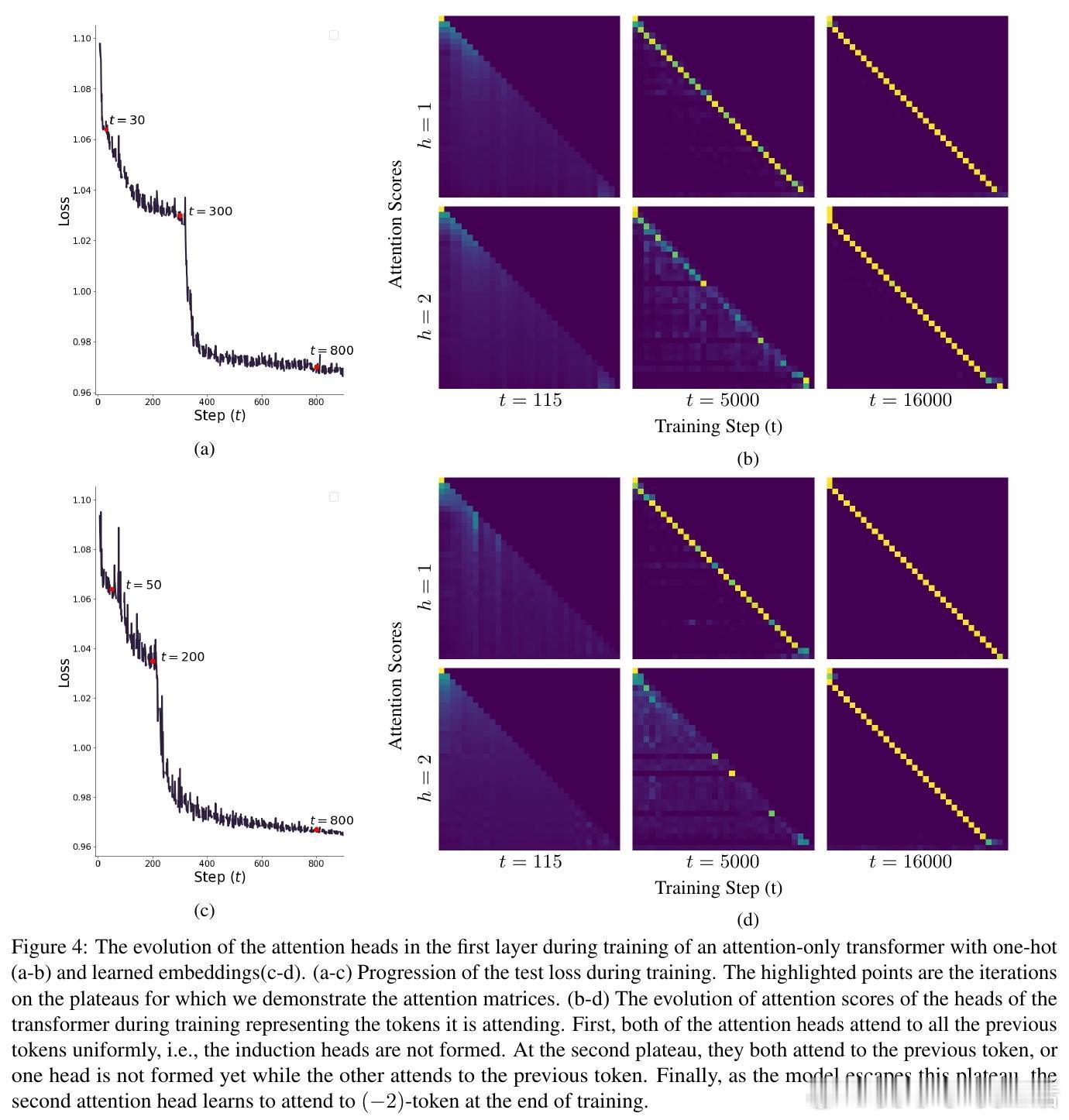
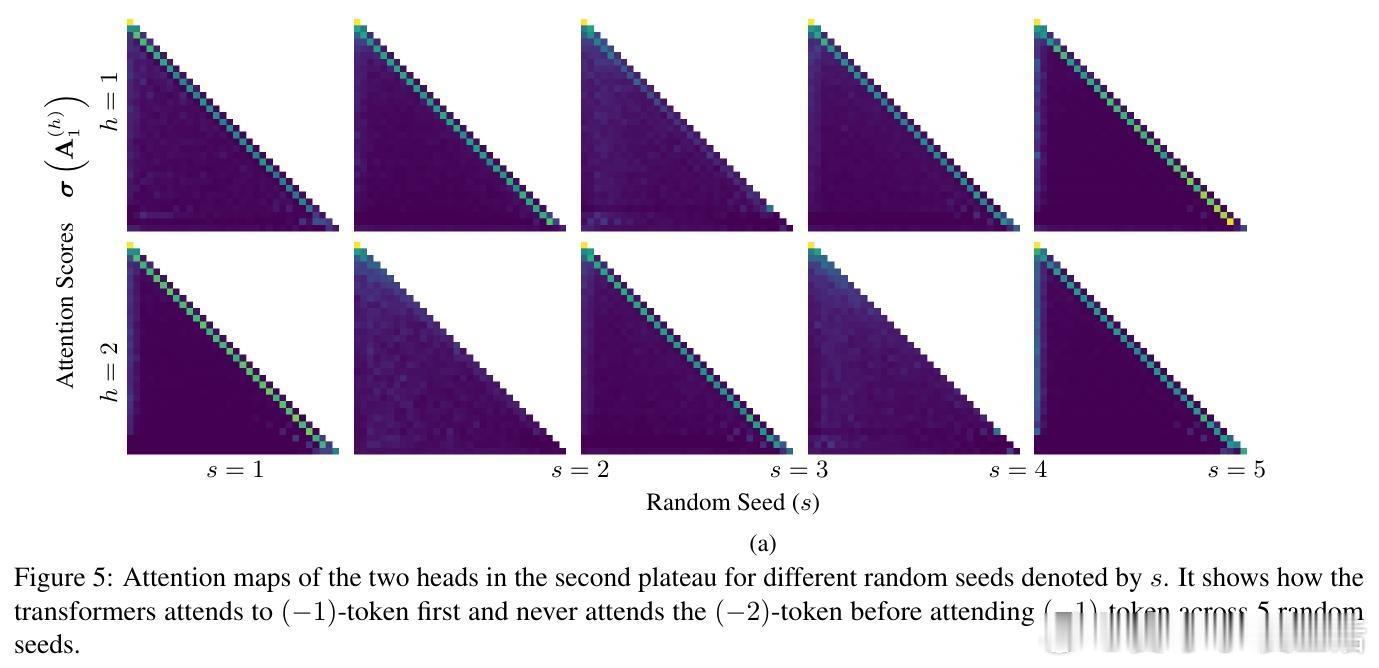
• 实验验证了不同训练阶段模型注意力的演进轨迹:从均匀关注到一阶历史,再到更高阶历史,完全符合理论预期。
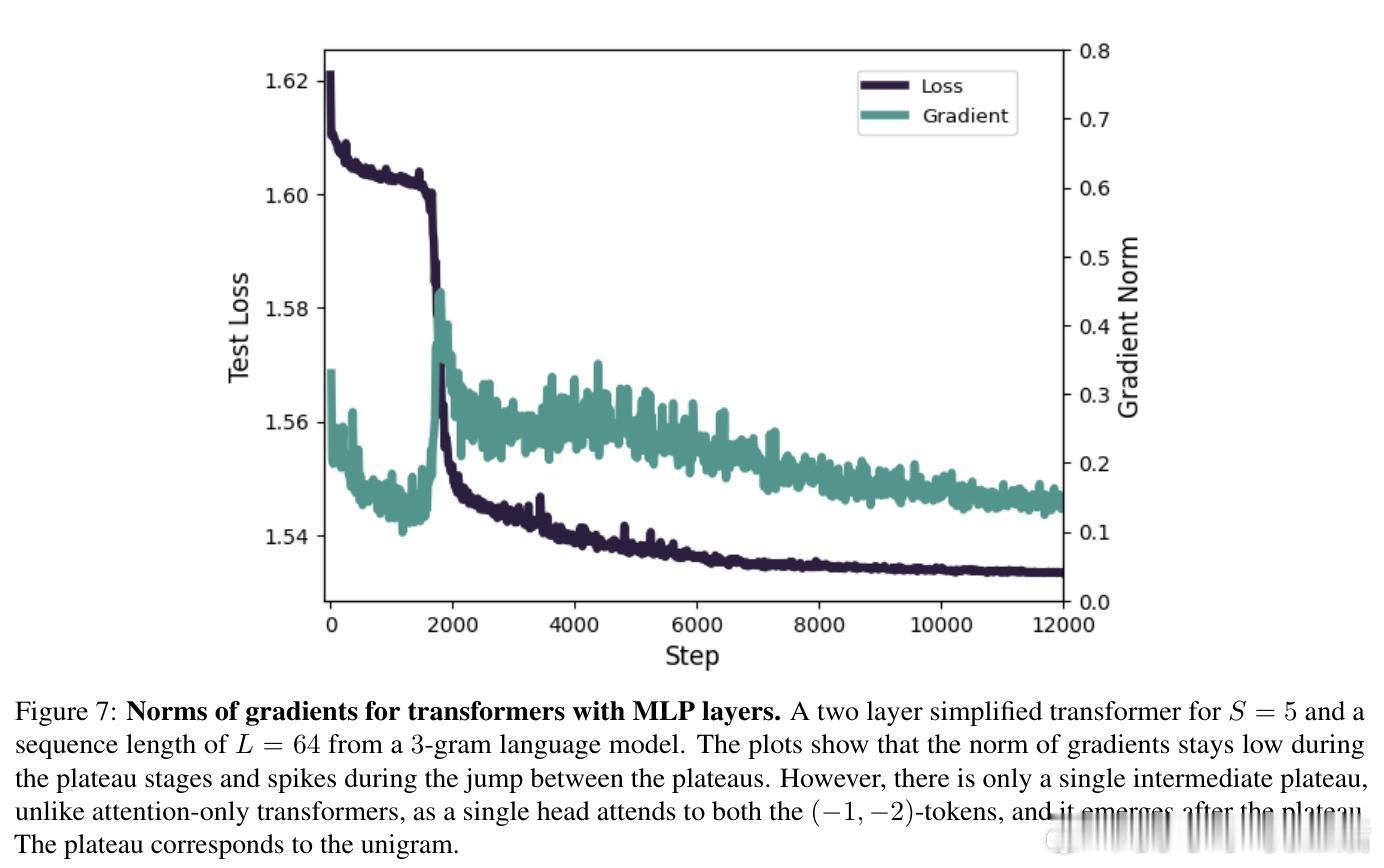
• 结果具备推广性,涵盖一般transformer结构、非连续子序列依赖及含MLP层的模型,揭示了transformers如何逐步掌握因果结构和语法规律。
• 该工作为理解大型语言模型阶段性能力涌现提供了数学基础,对优化训练策略和模型设计具有长远参考价值。
详细解读👉 arxiv.org/abs/2508.12837
机器学习自然语言处理TransformerinContextLearning语言模型深度学习