GPU 训练新思路:摆脱反向传播的“Marketplace”算法详解
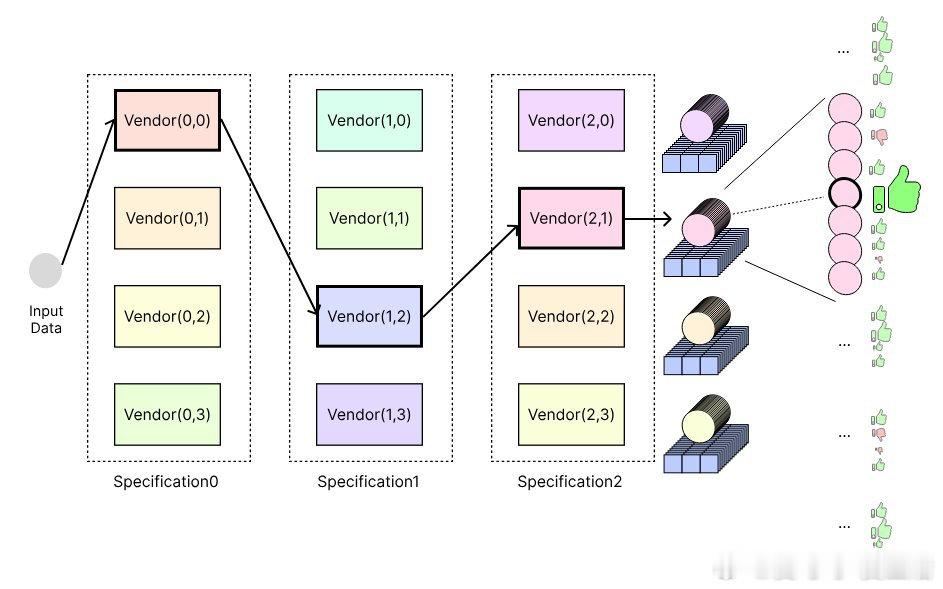
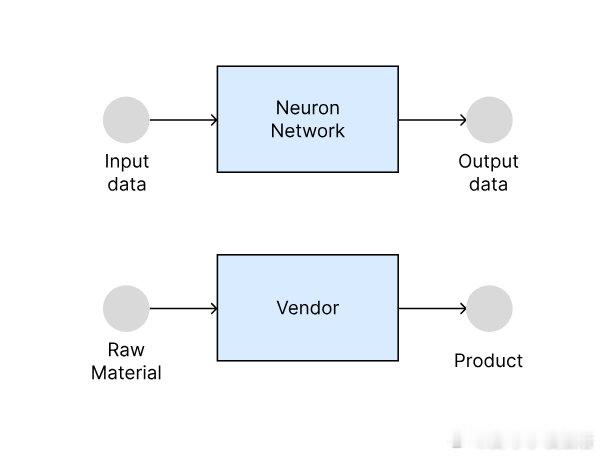
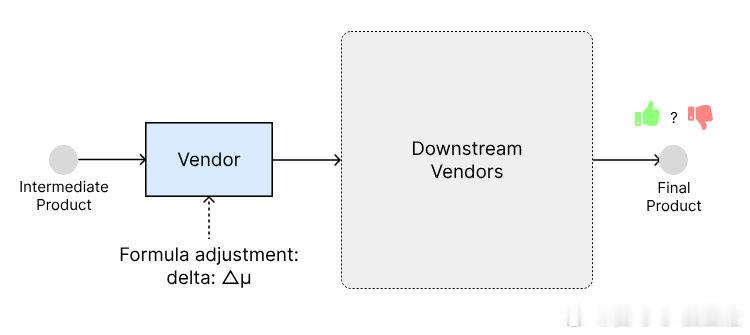
• 灵感源自自由市场机制,视神经网络为多个“供应商”竞价生产中间产品,层层递进,最终输出模型预测结果。
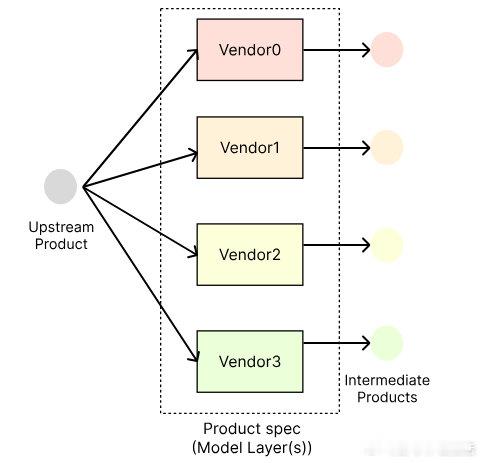
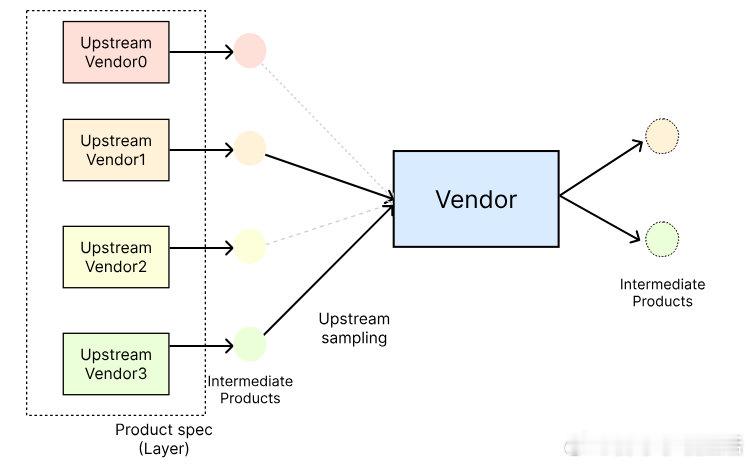
• 每层含多个“供应商”(权重变体),通过对上游中间产物进行采样,生成多样化产品路径,实现高效GPU并行计算。
• 训练流程:评估最终产品质量,选出最佳供应商权重,并让其他供应商复制并微调,形成良性竞争和演化。
• 避免了反向传播的内存和依赖瓶颈,尤其适合分布式训练,有望实现更大规模横向扩展。
• 关键调试点包括学习率设置和批归一化替换实例归一化,后者有效减少训练中的噪声影响。
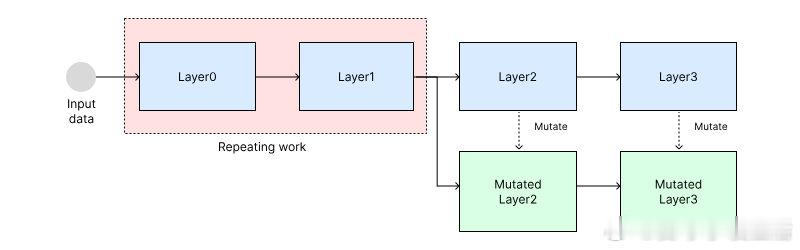
• 相较于一次性变异全模型权重,分层分组变异显著节省计算资源,市场深度N越大,权重组合越丰富,训练表现越好。
• 实验中,Marketplace对小型MNIST CNN模型表现良好,尝试过ResNet18大模型,训练趋势积极,但仍不及反向传播收敛速度快。
• 优势在于理论上的可扩展性和GPU资源利用率接近100%,不依赖模型可微性,适合探索非梯度优化路径。
• 未来方向涵盖基于随机种子的权重重构、分布式集群训练、引入动量改进随机变异、以及结合在线学习实现用户反馈驱动优化。
• 该算法与1985年《Bucket Brigade Algorithm》有相似之处,均基于局部竞争与奖励机制,但Marketplace更注重GPU友好并行与权重复制策略。
深度阅读👉 fangpenlin.com/posts/2025/08/18/marketplace-my-first-attempt-at-training-without-backprop-on-gpu-efficiently/
机器学习 深度学习 反向传播 分布式训练 GPU计算 算法创新 神经网络