[CL]《Language Modeling with Learned Meta-Tokens》A N. Shah, K Gupta, K Ramji, P Chaudhari [University of Pennsylvania & IBM Research AI] (2025)
引入元标记(meta-tokens)与元注意力机制,提升长上下文语言模型的表现和泛化能力。
• 元标记为预训练期间周期性注入的特殊可学习标记,作为内容驱动的“锚点”,压缩并缓存前文上下文,实现高效信息检索。
• 结合稀疏激活的元注意力层,模型专门关注元标记,形成隐式快捷路径访问远距离上下文,支持训练上下文窗口长度的2倍以上泛化。
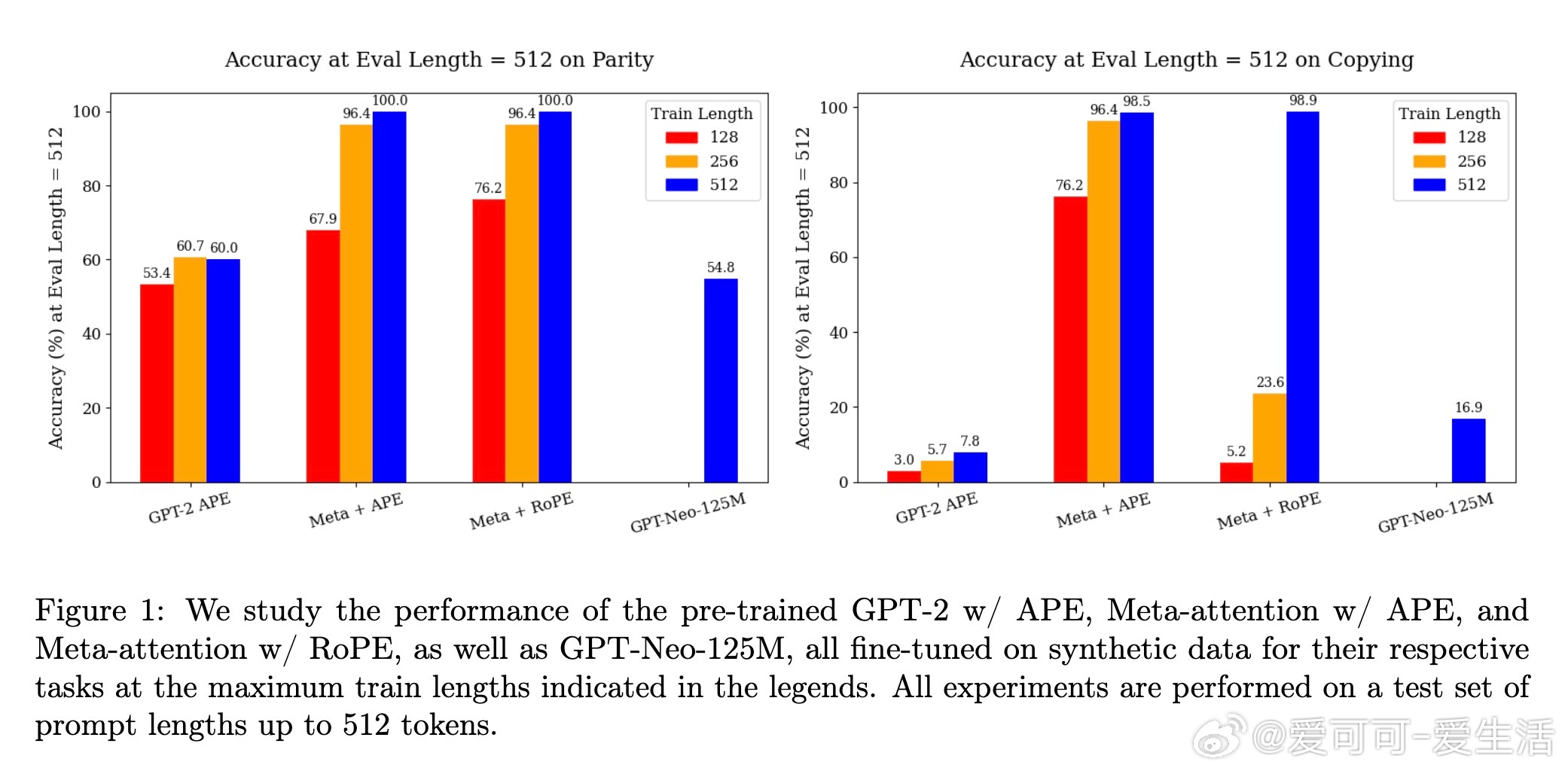
• 通过改造GPT-2架构并应用RoPE(旋转位置编码),在不到100B训练tokens下,元标记模型在合成任务(列表回忆、区段计数、奇偶校验、复制)上显著超越GPT-2和GPT-Neo基线。
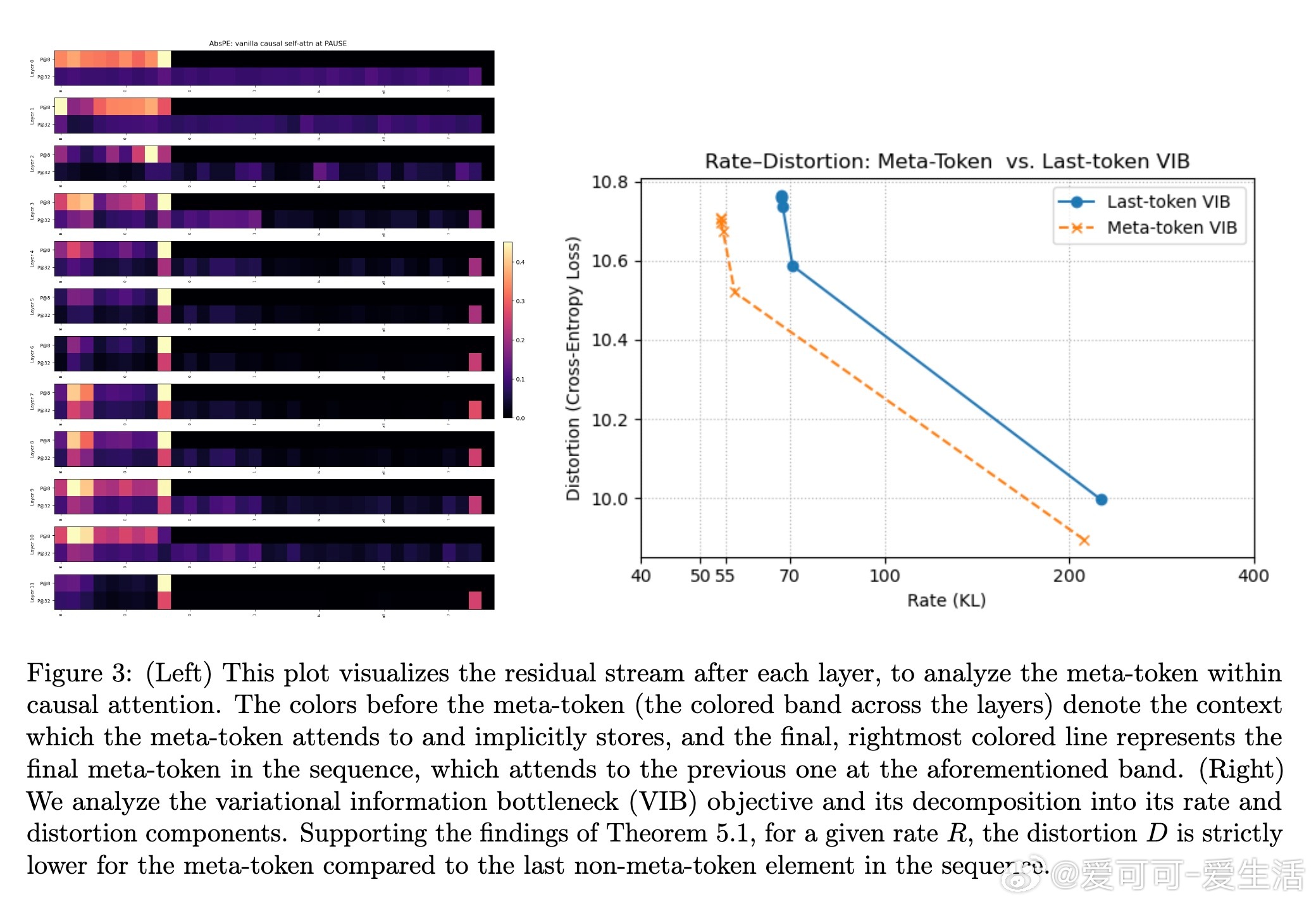
• 零化元标记处的位置编码反而提升性能,表明模型依赖元标记内嵌的上下文内容而非显式位置,减少了编码冗余和信息瓶颈。
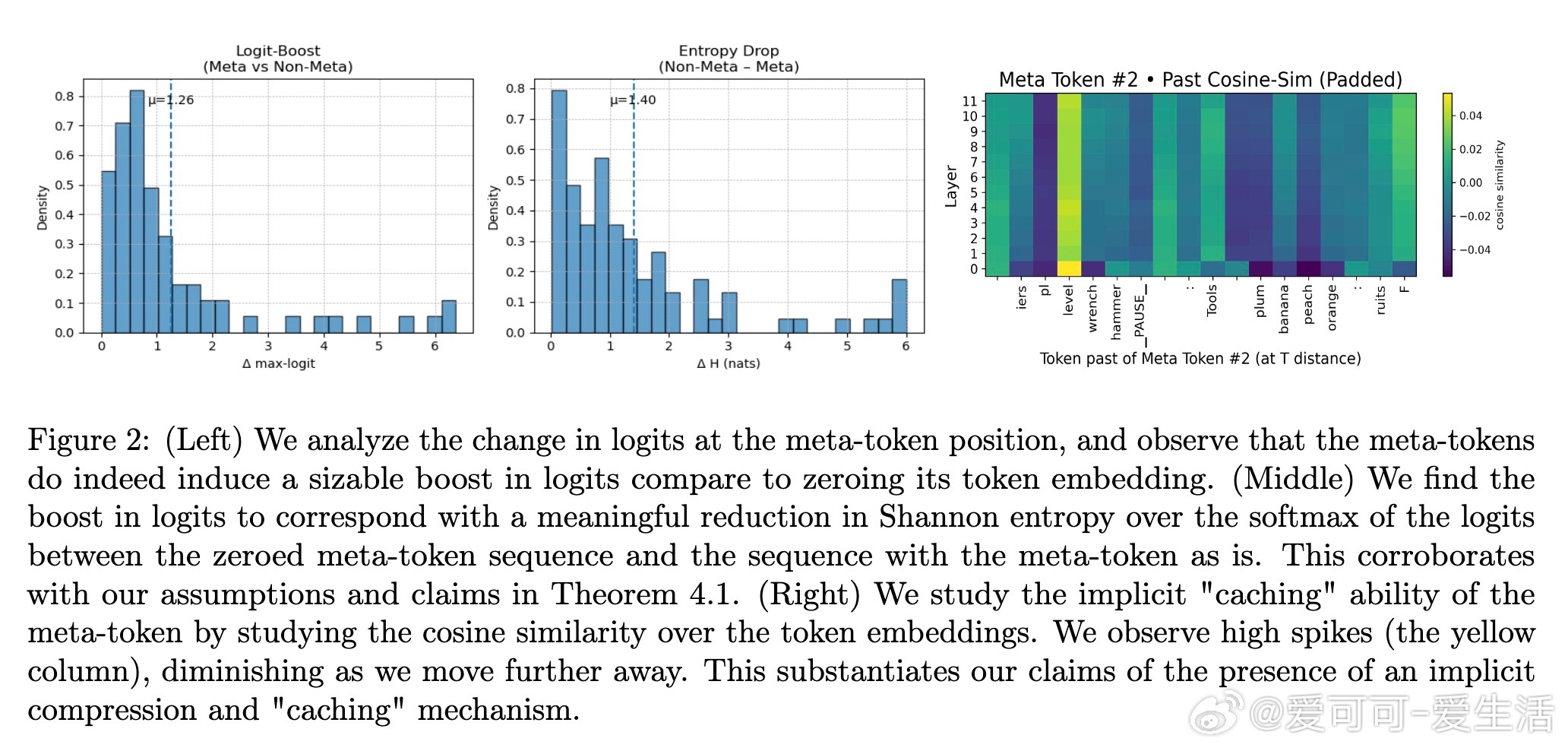
• 理论与实证结合,元标记通过增加logit边际降低注意力熵,实现“定位聚焦”效应;信息论分析(率失真理论)证实元标记作为高效上下文压缩器的角色。
• 推理阶段计算开销微增,仅约1.11倍,且优化稀疏注意力后可进一步降低负担。
• 该方法兼容动态扩展上下文窗口技术(如YaRN),具备实际长文本处理潜力。
心得:
1. 将上下文压缩与显式位置编码解耦,元标记引导模型学会内容驱动的定位,挑战了传统位置编码的绝对依赖。
2. 通过引入训练友好的稀疏元注意力,模型能在有限训练数据下有效学习复杂的长距离依赖,提升数据效率。
3. 元标记作为隐式缓存和快捷检索机制,为未来长文本理解和多任务泛化提供了通用且轻量的架构改进方向。
详情阅读🔗arxiv.org/abs/2509.16278
人工智能自然语言处理Transformer长上下文建模机器学习