[LG]《LLM Knowledge is Brittle: Truthfulness Representations Rely on Superficial Resemblance》P Haller, M Ibrahim, P Kirichenko, L Sagun... [FAIR at Meta & University of Zurich] (2025)
大语言模型知识脆弱性揭秘
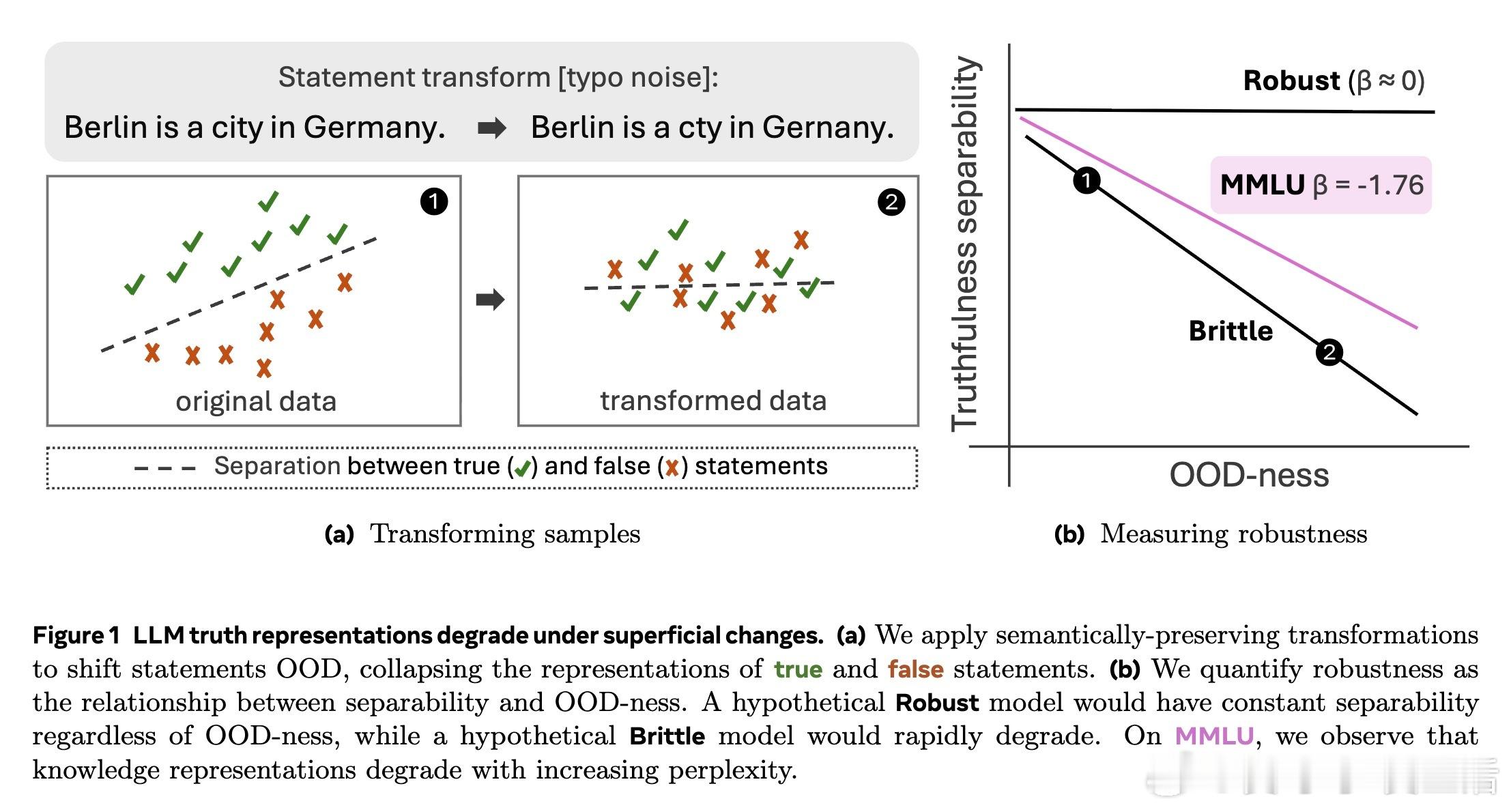
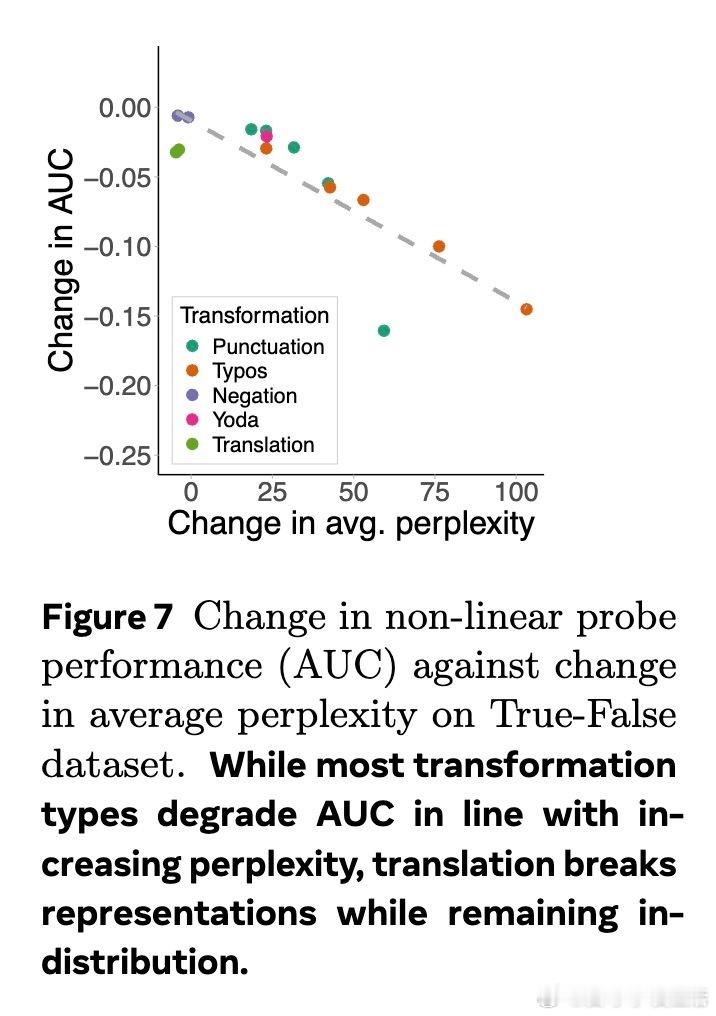
最新研究《LLM Knowledge is Brittle: Truthfulness Representations Rely on Superficial Resemblance》指出,当前大型语言模型(LLM)对事实真伪的内部知识表示极度依赖与训练数据的表面相似性。只要输入出现轻微变动(如拼写错误、格式变化、语序倒装甚至翻译),模型区分真假的能力就显著下降,表现出极强的脆弱性。
🔍 研究方法:
- 以“真或假”任务检测模型内部是否存在稳健的知识表示
- 通过拼写错误、标点噪音、颠倒语序、翻译等保持语义不变的扰动,推动样本离开训练分布(OOD)
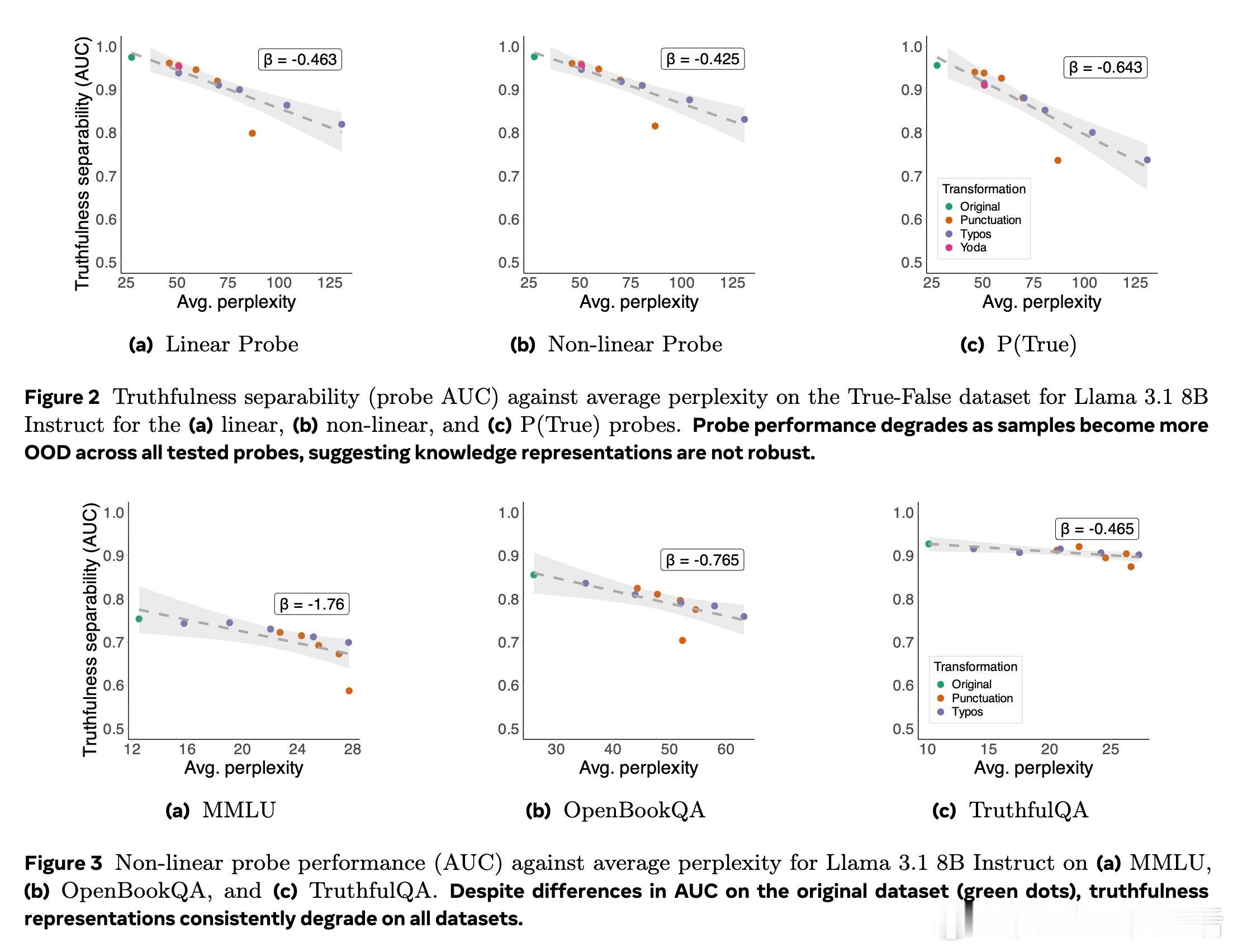
- 利用平均困惑度(perplexity)衡量输入的OOD程度
- 对4个模型家族、5个数据集、3种探测技术进行2000+实验验证
⚠ 关键发现:
1️⃣ 模型在训练数据近似表达上表现优异,但稍微偏离表面形式,知识表示分离度大跌,揭示知识表示极度浅层且非鲁棒。
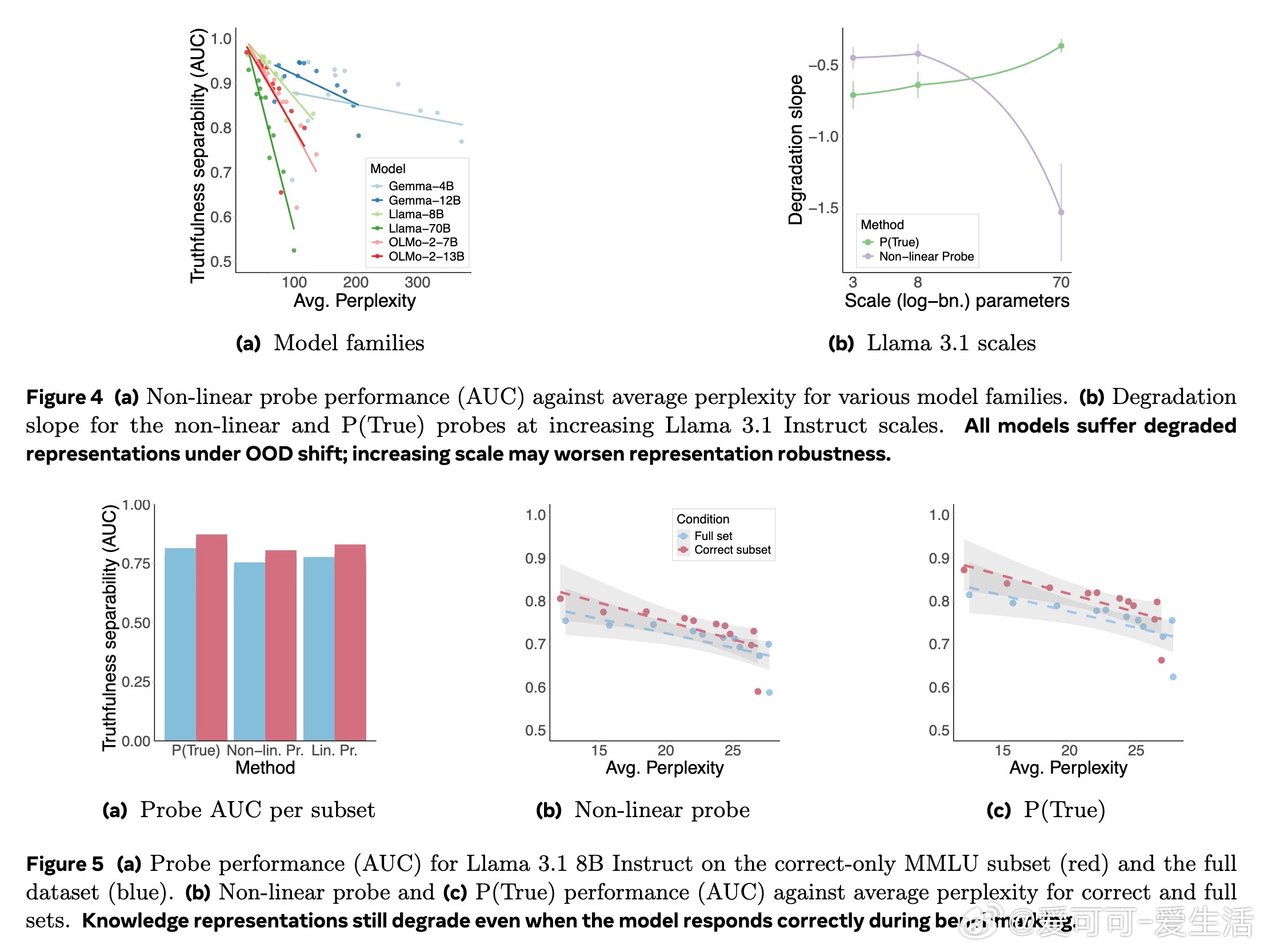
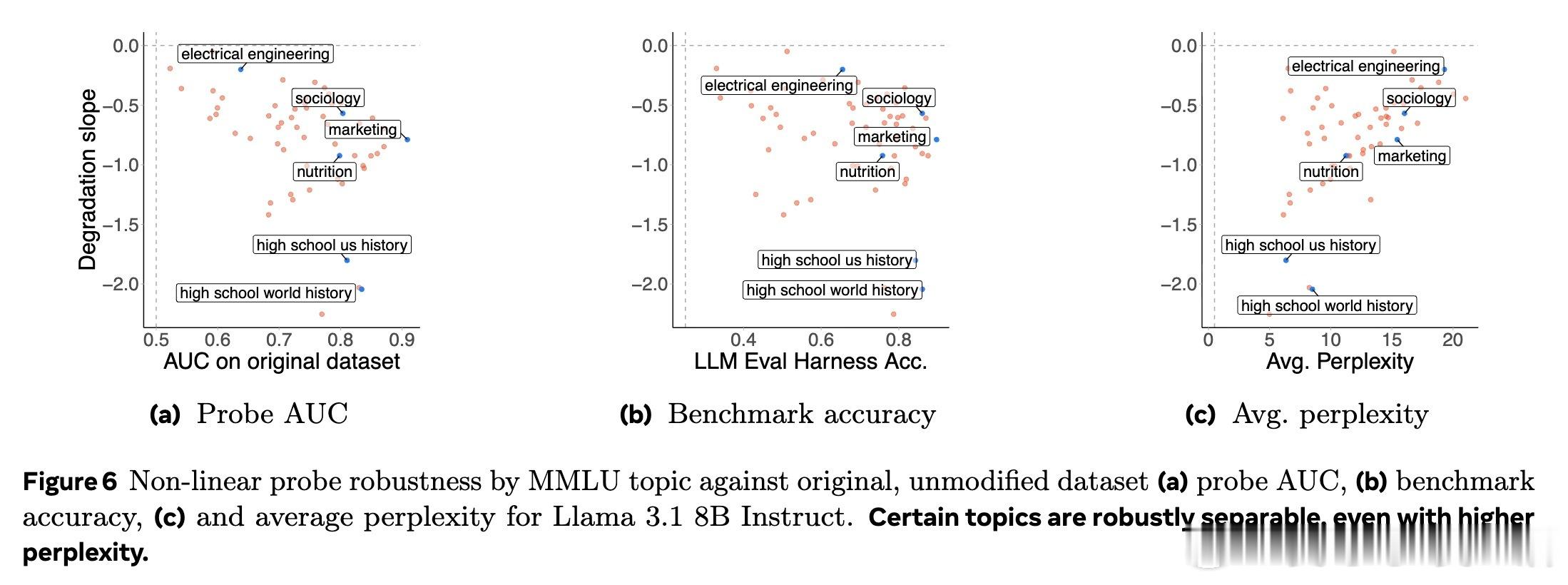
2️⃣ 不同主题知识的鲁棒性差异明显,比如营销与社会学领域较稳健,历史类知识则易崩溃;但这与预训练数据覆盖度无关。
3️⃣ 模型规模扩大不一定带来更强鲁棒性,甚至更大模型表现更脆弱。
4️⃣ 即使模型在标准基准上正确回答问题,其知识表示仍然脆弱,表明基准表现不能代表知识的稳健性。
🔑 结论与展望:
- LLM知识表示依赖表面特征,缺乏真正泛化能力
- 这为真伪探测等知识质量提升方法带来根本挑战
- 未来需重点研究如何构建稳定、泛化的知识表示以提升模型可靠性
全文阅读 👉 arxiv.org/abs/2510.11905
人工智能 大模型 机器学习 NLP 知识表示 模型鲁棒性