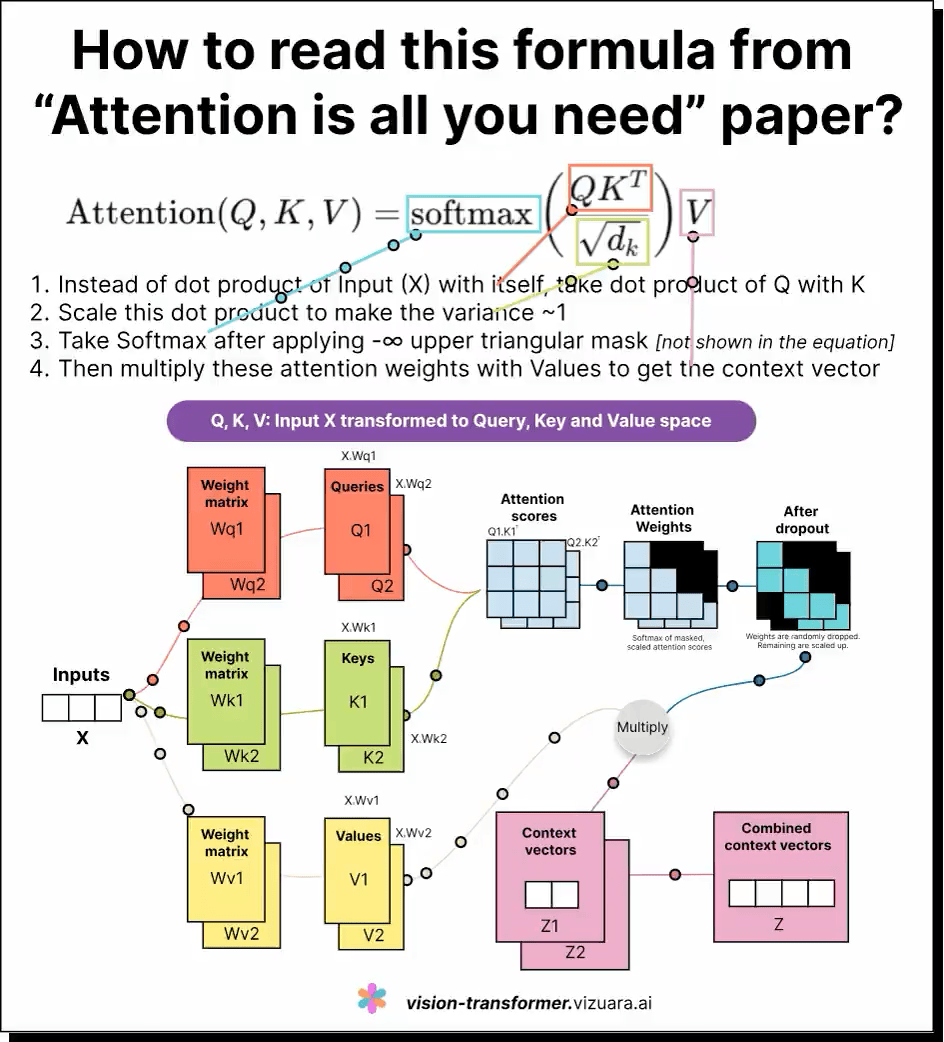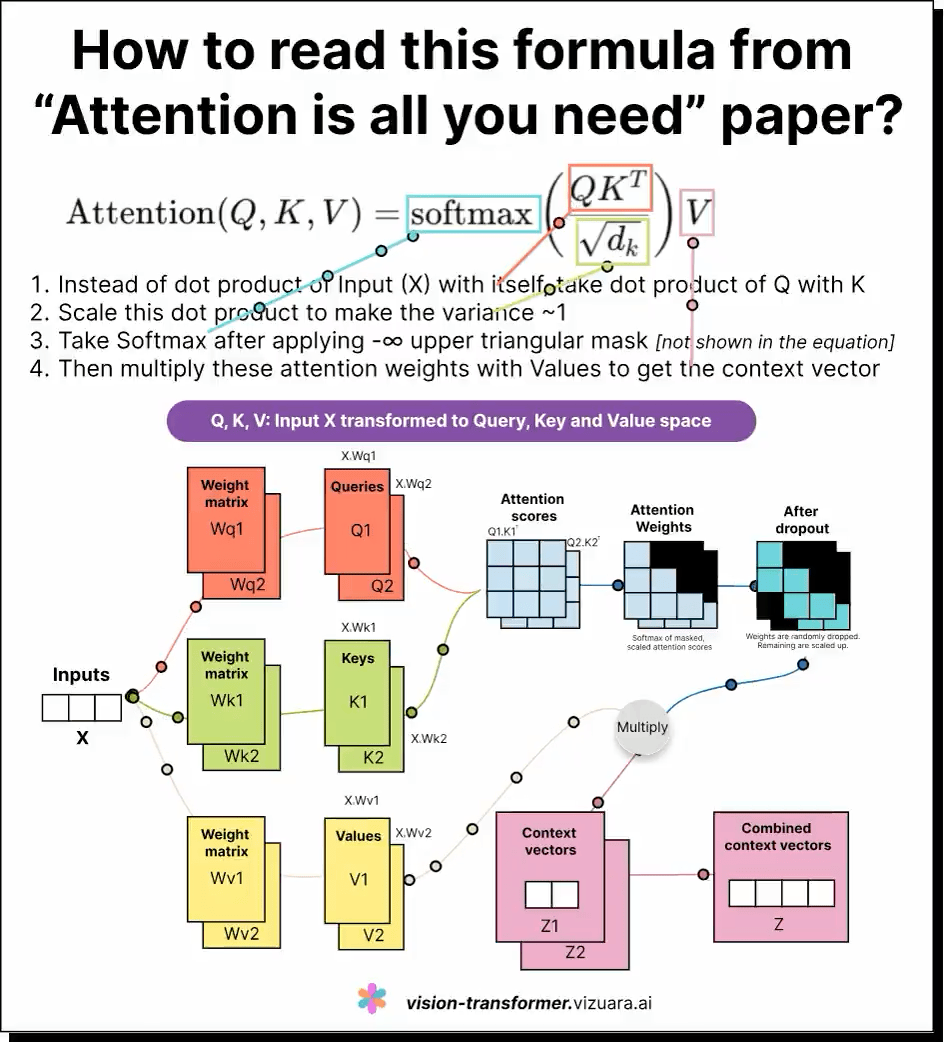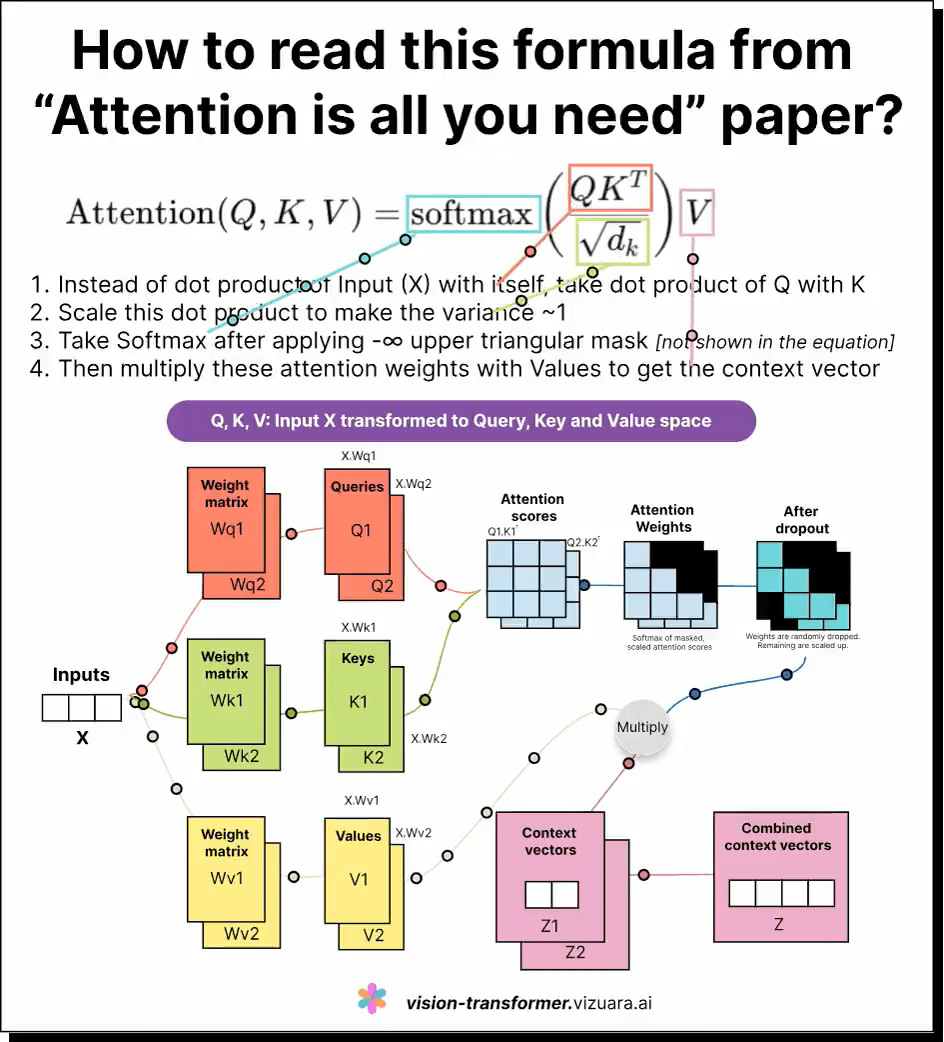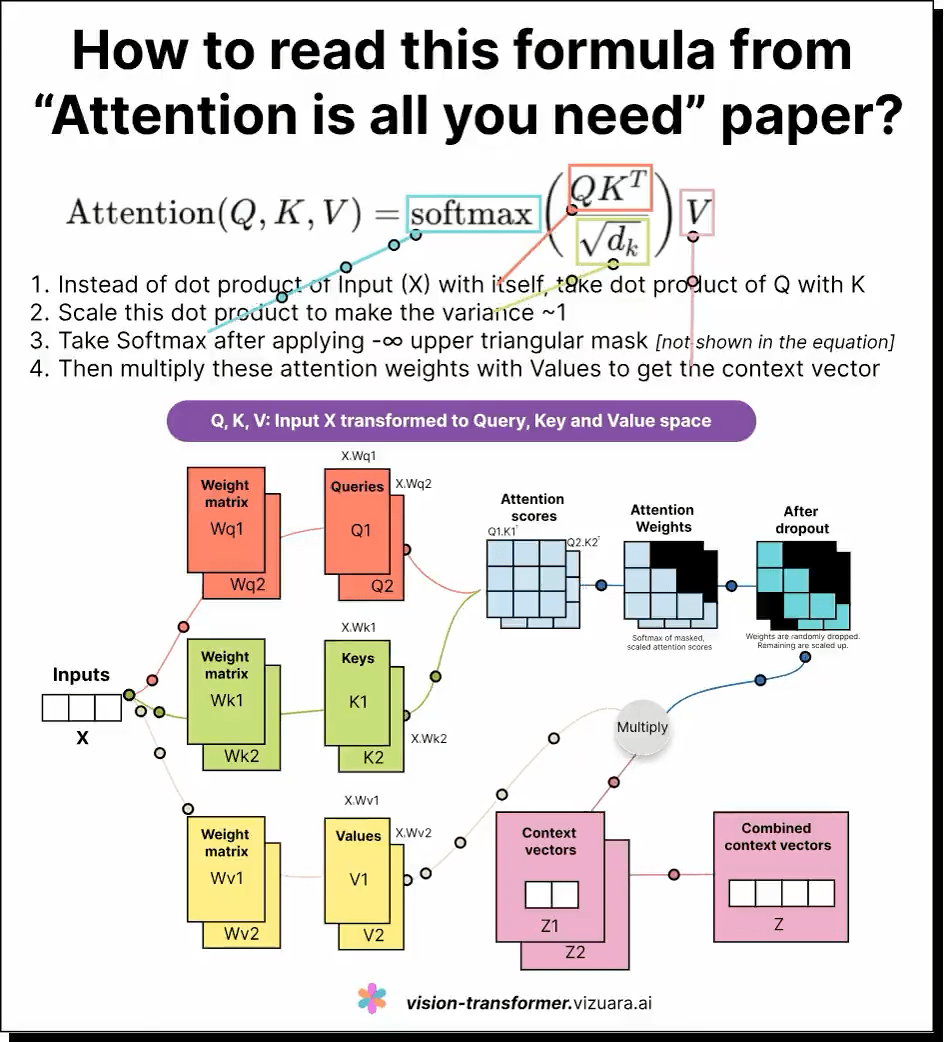
这是一条对大型语言模型(LLM)中自注意力机制(self-attention)公式的深刻解读。虽然公式看似简单,且易于记忆,但真正理解查询(Q)、键(K)、值(V)三者的含义及其相互作用,却非常困难。
通过形象化的可视化展示,许多学习者获得了直观的认知,帮助他们理解模型如何在序列中捕捉词与词之间的关联并动态调整注意力分布。正如有用户形容,将LLM的工作过程看作“菜单-子菜单-子子菜单”的层级导航,有助于精准设计上下文提示,引导模型聚焦语义方向。
当然,也有观点指出“Attention并非万能”,强调需要结合更多机制来提升模型能力。技术交流中,大家还热议了如何制作动图、工具推荐及更深入的数学理解,展现了对这一核心技术的浓厚兴趣和探索热情。
如果你也曾被Q、K、V弄得头疼,这条内容无疑是极佳的入门和深化指南。
—— 原推文:x.com/Hesamation/status/1979669577719218478