[LG]《Transitive RL: Value Learning via Divide and Conquer》S Park, A Oberai, P Atreya, S Levine [UC Berkeley] (2025)
在强化学习中,长时间跨度任务面临“地平线诅咒”:传统时序差分(TD)方法的偏差随时间累积,蒙特卡洛(MC)方法则受高方差困扰。最新预印本《Transitive RL: Value Learning via Divide and Conquer》(arxiv.org/abs/2510.22512)提出了一种创新算法——转移强化学习(Transitive RL,TRL),基于分而治之思想,利用目标条件强化学习(GCRL)中固有的三角不等式结构,实现价值函数的高效更新。
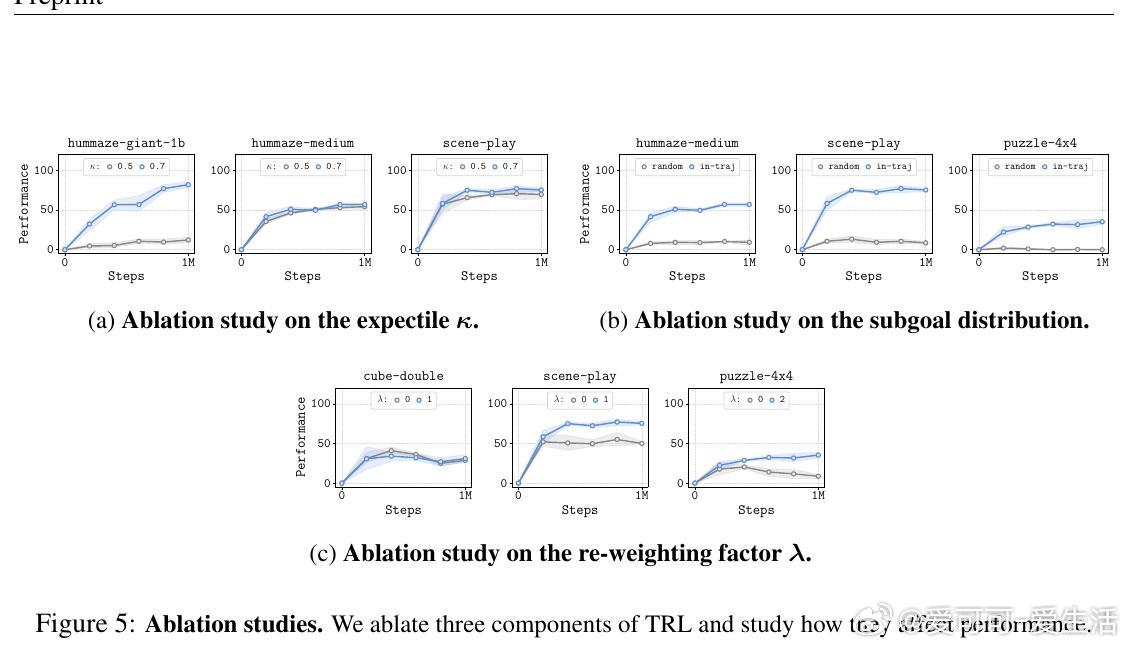
TRL的核心在于将长轨迹的价值估计拆解为多个较短轨迹的组合,通过软期望回归和轨迹内子目标的“行为子目标”限制,有效抑制了价值高估问题,避免了传统方法中对整个状态空间取最大时带来的不稳定。此外,TRL采用基于距离的重加权策略,优先优化短路径子问题,提升训练稳定性。
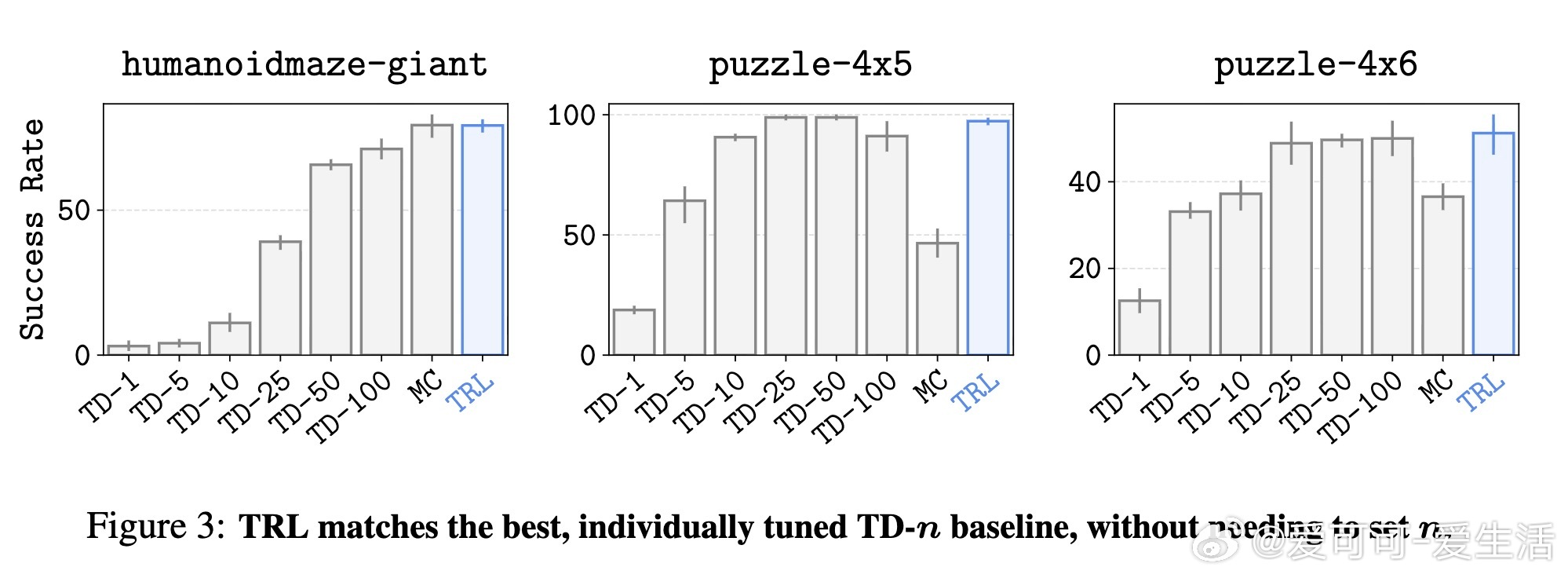
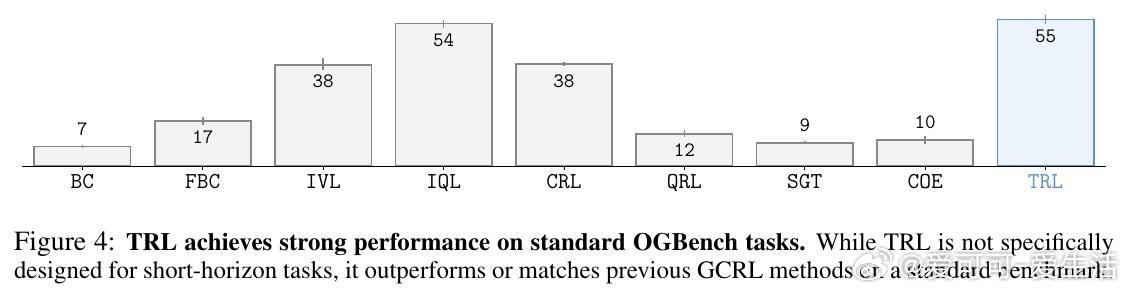
实验结果表明,TRL在Humanoid Maze大型迷宫、Puzzle按钮拼图等复杂长时间跨度任务中,优于或匹配了当前主流的TD-n步和MC方法,同时在标准OGBench基准测试中也展现出强劲表现,尤其在无需精细调节超参数n的情况下取得最佳成绩,显著提升了离线目标条件强化学习的可扩展性。
这项工作不仅验证了分而治之策略在价值学习中的潜力,也为未来探索在随机环境下的无偏价值估计及推广至更通用的奖励驱动RL任务奠定了基础。TRL的成功证明了三角不等式软约束结合轨迹内子目标选择,是解决长时域强化学习问题的有效路径。
详细技术细节、算法伪代码及丰富实验数据均可参考原文:
arxiv.org/abs/2510.22512
欢迎访问作者博客了解更多:
seohong.me/blog/rl-without-td-learning