
单词文件
内存限制大小1MB。在1GB单词文件当中,返回频数最高的100个词。
2、算法思路在内存限制为 1M 的情况下,可以使用一些分块处理和排序算法来解决。
分块读取文件:将文件分成多个小块,每次读取一个小块到内存中进行处理。可以根据内存限制和文件大小来确定每个小块的大小。统计每个词的频率:对于每个小块,遍历其中的每行,将每个词添加到一个哈希表或字典中,并增加其对应频率的值。合并各个块的统计结果:将所有小块的统计结果合并到一个全局的哈希表或字典中。排序并获取前 100 个词:对全局的统计结果进行排序,根据词的频率降序排列。然后获取top 100 个词作为结果。输出结果:将前 100 个词输出到指定的位置。
在有限内存下处理大数据
3、python 代码def top_100_words(file_path, memory_limit=1024 * 1024): # 打开文件并读取所有内容 with open(file_path, 'r', encoding='utf-8') as file: content = file.read() # 分割文件内容为小块 chunks = [content[i: j] for i in range(0, len(content), memory_limit // 2)] # 统计每个词的频率 word_counts = {} for chunk in chunks: for word in chunk.split(): if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 # 排序并获取前 100 个词 sorted_words = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)[:100] # 输出结果 for word, count in sorted_words: print(f"{word}: {count}")# 指定文件路径file_path = 'your_file.txt' # 调用函数统计前 100 个高频词top_100_words(file_path)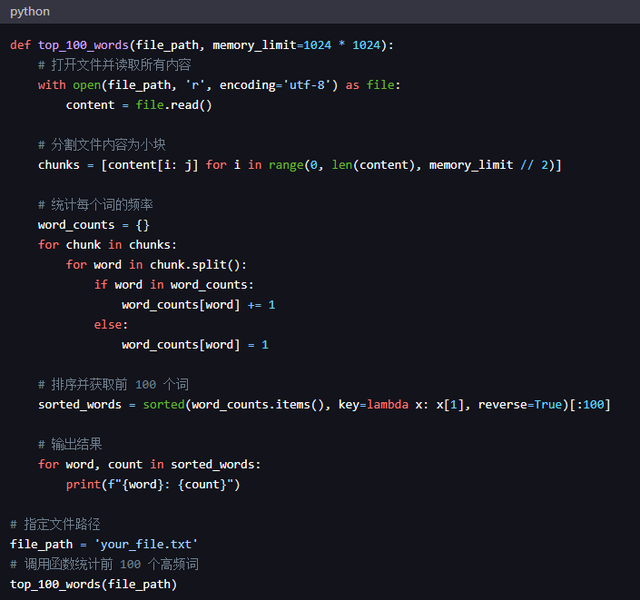
python code
代码过程:
首先将文件内容分割为小块,然后在每个小块中统计词的频率。最后,我们对所有小块的统计结果进行合并和排序,获取前 100 个高频词并输出。
