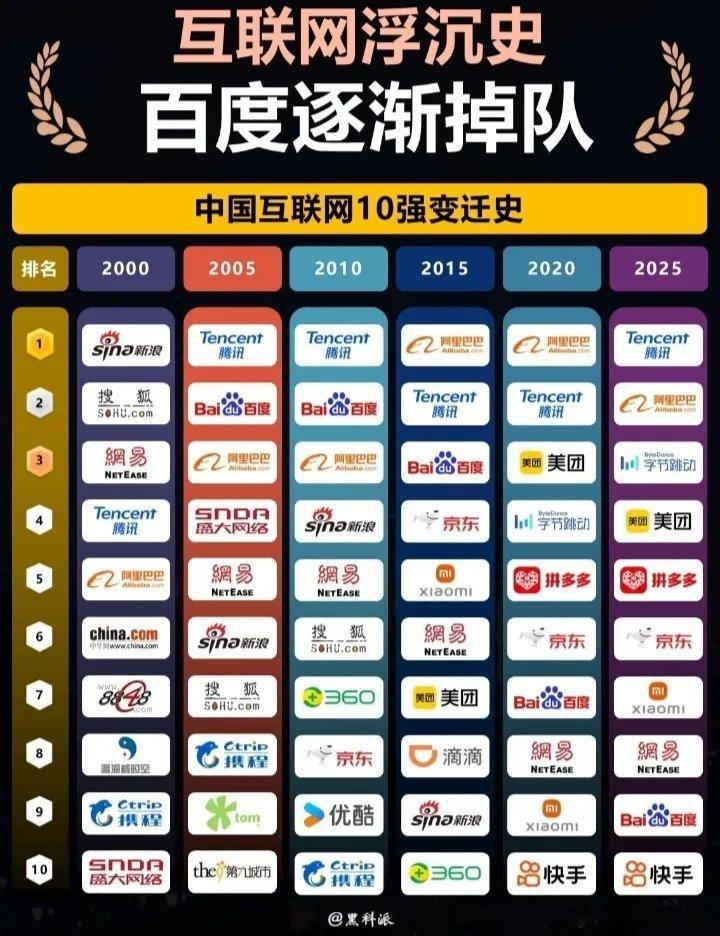
你知道AI晶片史上最大的订单是谁出货吗?不是Nvidia当大家以為算力版图已定调时,Anthropic把筹码压在 Google:宣布未来将「使用最高达 100 万颗 TPU」,金额级距落在数百亿美元等级,并计画在 2026 年陆续上缐超过 1GW 的运算能力。这不是小单,是产业讯号:推理时代,供应链规则正在改写。 关键不只在单颗晶片,而是系统级设计。Google 第七代 TPU Ironwood 一个 Pod 可扩到 9,216 颗,标称 FP8 42.5 ExaFLOPS,Google 自称「超过目前最大超级电脑的 24 倍」;单颗峰值為 4,614 TFLOPS,并以 Pathways 把数万颗 TPU 池化在一起运行。注意:这些是 AI 精度指标(如 FP8),与传统超算的 FP64 并非同一基准,但它说明了 Google 在大规模推理上的工程取向。 Ironwood 的「万卡级」互连是另一个重点:9.6 Tb/s 的晶片间连缐,把几千颗 TPU 紧密耦合成一台逻辑上的超级电脑,降低延迟与资料搬移成本,正对准高频、低延迟、强成本敏感的推理工作负载。 把镜头拉到经济性。Anthropic 对外说明选择 TPU 的核心理由是「价格效能与能效表现」。当推理流量远大于训练、电费与机柜位成為 P&L 第一大科目时,单位成本/每次推理才是董事会要看的 KPI。 这并不代表 Nvidia 退出𢧐场。Nvidia 的 Blackwell Ultra(GB300)在机柜等级的 NVL72 系统,官方与第三方资料显示:每柜标称 FP8 训练约 0.36 ExaFLOPS、FP4 推理约 1.1 ExaFLOPS;而微软已把多个 NVL72 组成超大丛集,对外宣称 FP4 推理可达 92.1 ExaFLOPS。两边都在拼「系统级」伸缩与供应链整备。 资本支出也在定锚产业走向。Alphabet 对 2025 年 CapEx 指引上修至 910–930 亿美元,最近一季约 6 成投入在伺服器(其馀為资料中心与网路)。当供给侧用「云端一条龙」做垂直整合时,成本曲缐会更快往下走。 我的结论(Joey视角)1. 推理优先的设计语言正在成形。训练时代的生态(CUDA/通用 GPU)不会消失,但推理时代评分表改成「每美元吞吐量 × 每瓦吞吐量 × 延迟」。Ironwood 把这个故事讲到「万卡级实装」。 2. 订单的含义要看「规模存取」而非「一次性采购」。Anthropic 对外是「计画可存取最高 100 万 TPU」,时间轴跨到 2026 年之后,属于长约级别的 capacity reservation。 3. 两强并行、各取所长。Google 在垂直整合与推理 TCO 上有攻势;Nvidia 在软体生态与广义扩展性仍具优势,且同样以 NVL72/超大丛集回应。这不是零和,而是工作负载分流。 ~~~~~~~~~~~~~~~谷歌芯片大厂,可能大部分人没想到吧?