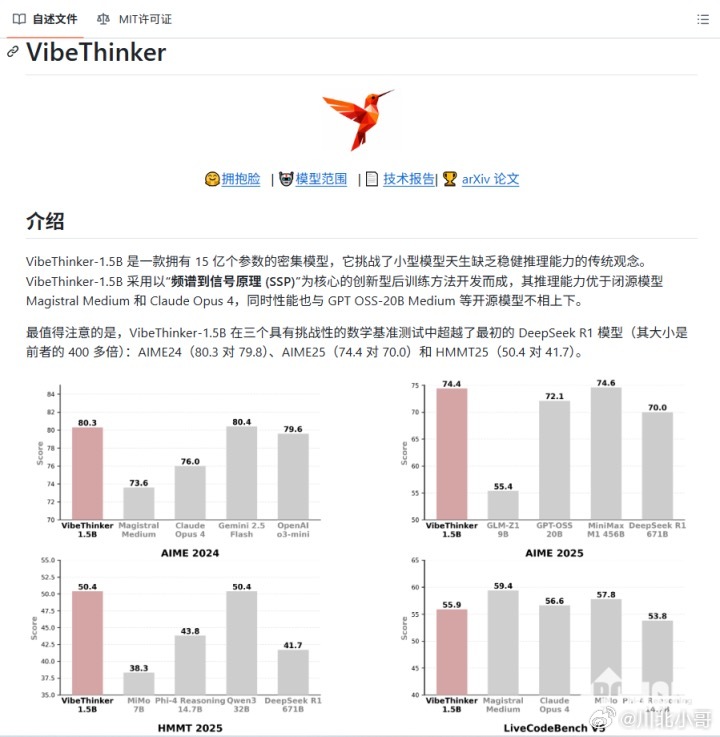
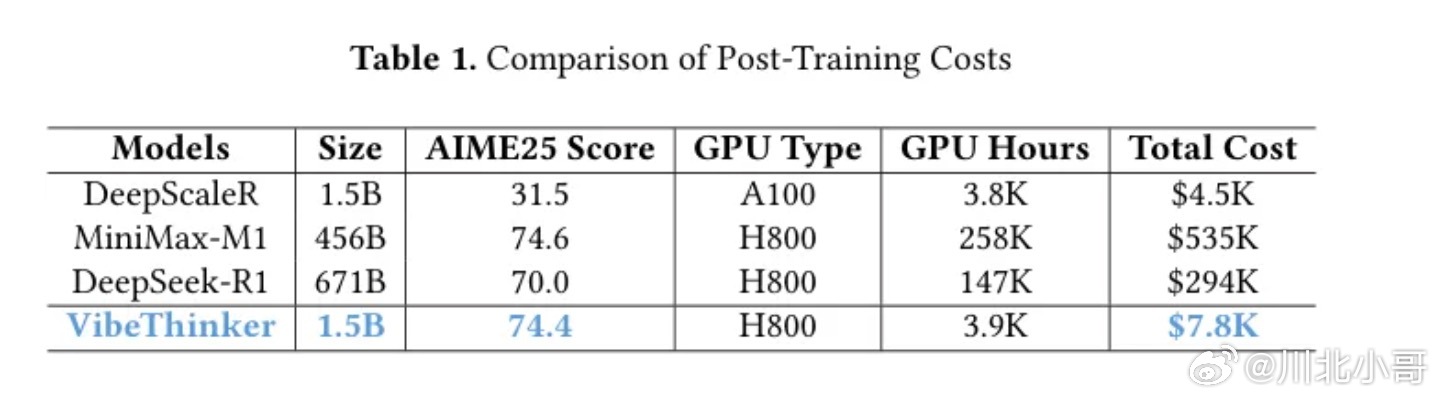
微博发布的开源的VibeThinker-1.5B,用15亿参数在数学竞赛基准中击败6710亿参数的DeepSeek R1,7800美元训练成本较同类大模型降低数十倍,彻底打破“参数即王道”的行业认知。其核心技术优势源于创新的SSP训练原则:SFT阶段聚焦“频谱多样性”,以Pass@ K 指标鼓励多思路解题,再通过模型合并融合各领域专家能力;RL阶段则精准“收敛信号”,借助MGPO框架聚焦“学习甜点区”优化,让小模型兼具思维广度与精度。相较于大模型,VibeThinker的优势堪称精准打击:成本上无需天价算力,中小企业皆可负担;部署上适配终端设备,本地运行兼顾隐私与速度;效率上垂直领域推理更高效,避免大模型的冗余消耗。但小模型也存在知识覆盖较窄、跨领域泛化不足的短板,而大模型虽在全局认知上占优,却受限于高成本、高延迟的落地困境。在大模型占据舆论高地的当下,小模型正凭借独特优势强势突围,成为AI行业的新风口。其“香”味核心源于三大硬实力:部署成本极低,无需昂贵GPU,可直接嵌入手机、机器人等终端,完美解决大模型“落地难”的痛点;数据隐私更有保障,本地运行无需依赖云端,规避了数据传输中的泄露风险;反应速度更快,在文档总结、内部检索等特定任务中效率远超大模型。相较于大模型,小模型虽参数有限、知识覆盖较窄,但在垂直领域更“术业有专攻”,能精准匹配中小企业或特定场景需求,而大模型则面临算力消耗巨大、泛化能力不足、存在知识与逻辑污染等问题。未来AI绝非两极分化,而是“大模型统筹+小模型落地”的协同生态。VibeThinker这类小模型,正以技术创新推动行业从“规模竞赛”转向“效率革命”,成为终端智能、垂直场景的核心载体,与大模型共同构建更具普惠性的AI产业新生态。