最新测评震撼出炉!17大顶尖AI谁最“胡说
图表会看世界
2025-12-12 15:00:53
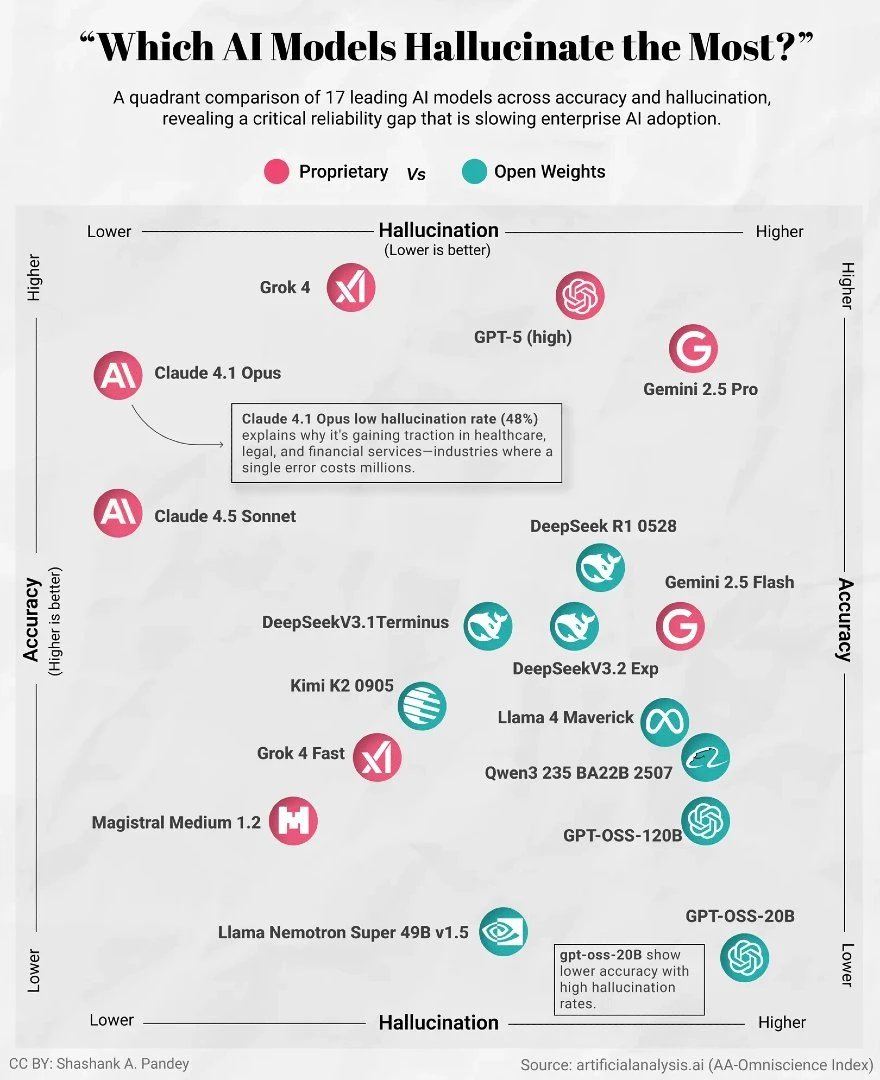
🧠 图片比较了 17 款领先 AI 模型的两个关键指标:准确率(越高越好)与幻觉率(越低越好)。
⸻
✨ Claude 4.1 Opus:高准确率+低幻觉率的双料冠军
Claude 4.1 Opus 位于“高准确+低幻觉”的黄金象限,幻觉率仅 48%,表现最接近“企业级理想模型”。正因如此,它在医疗、法律、金融等“容错率极低”的专业领域快速占据领先地位。旁注特别强调:一个错误可能花费数百万美元,因此可靠性是关键。
⸻
😵 GPT-5:准确率高,但幻觉率偏高
GPT-5 处在高准确、但幻觉偏高的位置。说明它拥有极强的智能能力,但在专业场景下仍可能出现高风险内容。这类模型适合创作、头脑风暴,但对于严肃业务仍需额外审查。
⸻
🌪️ Gemini 2.5 Pro:准确率高但幻觉也偏高
Google 的 Gemini 2.5 Pro 与 GPT-5 很相似,同样拥有高智能、但幻觉率不低。这类模型在信息生成方面能力强,但在高风险行业落地时需要严格的安全层。
不过 Gemini 2.5 Flash 则表现较好,准确度不错且幻觉率显著更低,是轻量模型中的亮点。
⸻
🔍 DeepSeek 系列:实用性极强,可靠度稳步上升
DeepSeek R1、DeepSeek V3.2、DeepSeek Terminus 等多款模型整体处于“准确高+幻觉中等偏低”的区域,是开源模型阵营中非常亮眼的表现。特别是 DeepSeek R1,其位置接近高准确低幻觉象限,说明它的专业能力与稳定性发展迅速。
⸻
🦙 Llama 系列:准确中等,但幻觉率更低
Llama 4 Maverick、Qwen 2、GPT-OSS-120B 等多款开源模型处在较均衡的位置。虽然准确率不如顶尖闭源模型,但幻觉率更可控,是企业采用开源模型的重要原因之一。
⸻
⚠️ GPT-OSS-20B:准确率偏低+幻觉率偏高
图注明确指出:GPT-OSS-20B 处于性能“最弱”象限,即准确率与幻觉率都不理想,提醒用户慎用。
⸻
🧩 Grok 系列:幻觉率偏高,准确度中等
Grok 4 与 Grok 4 Fast 均偏向中间位置,其中 Grok 4 的幻觉率偏高,准确度尚可,适合作为创意型模型,但不足以承担关键任务。
⸻
0
阅读:0
