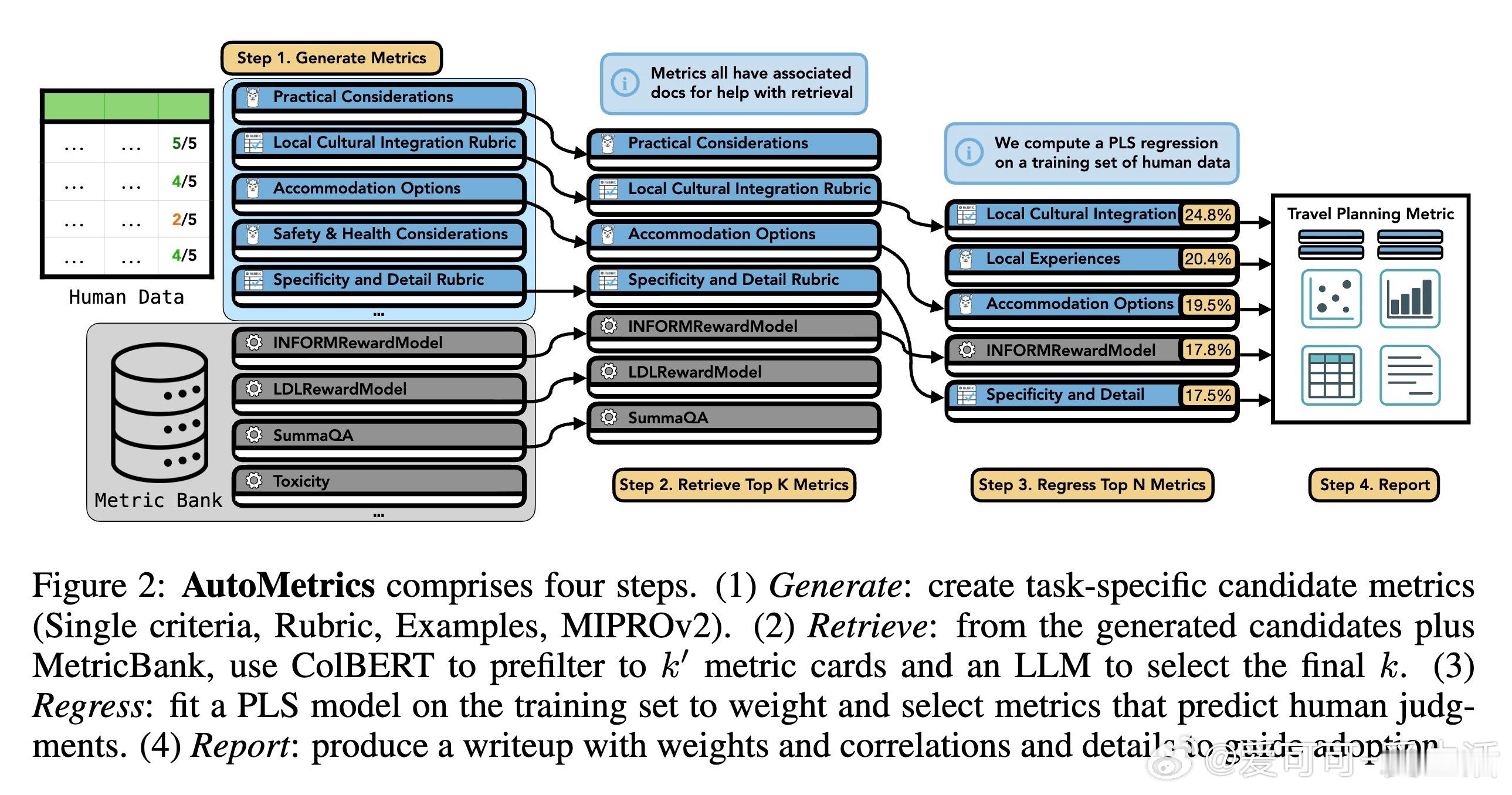
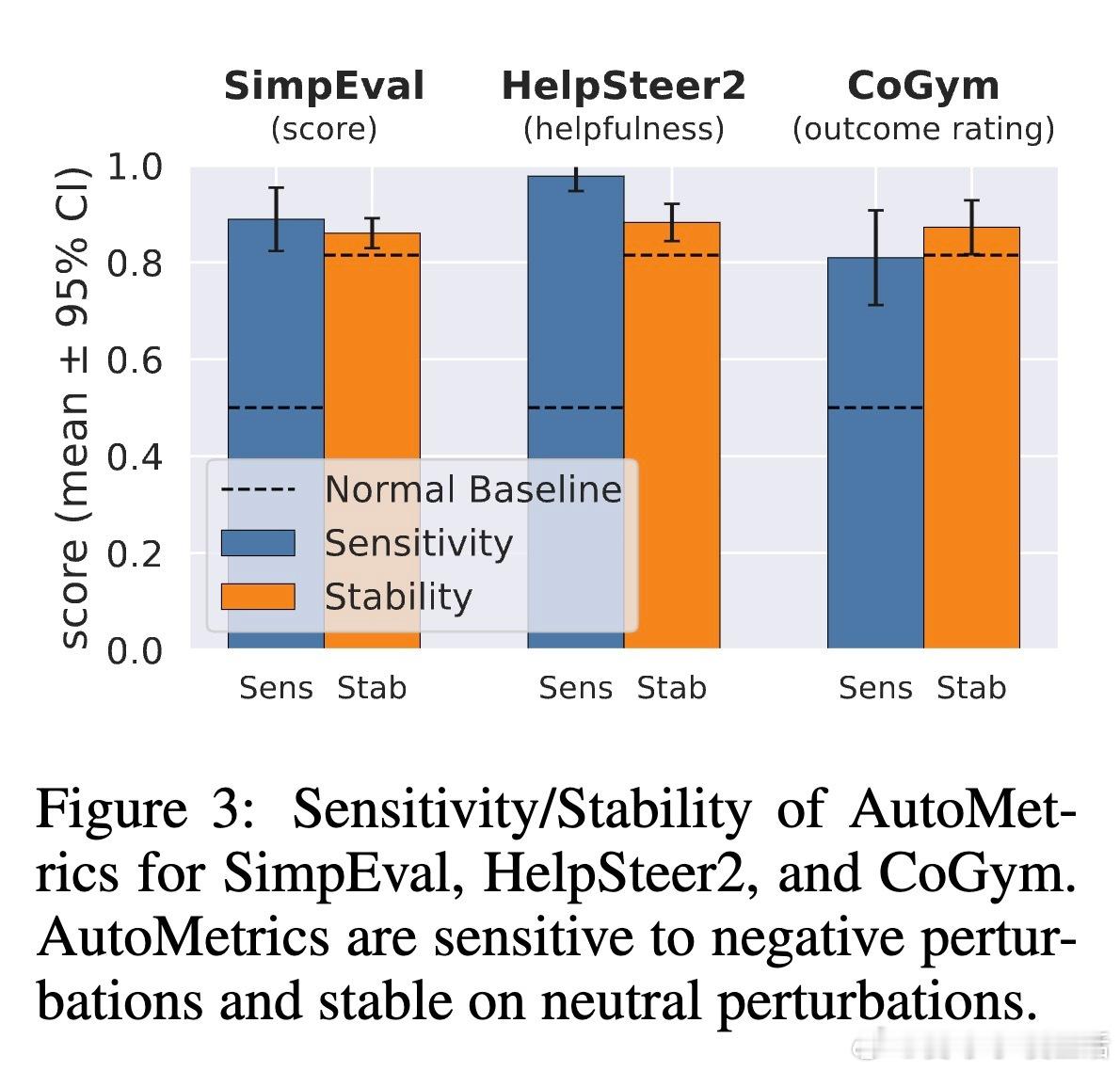
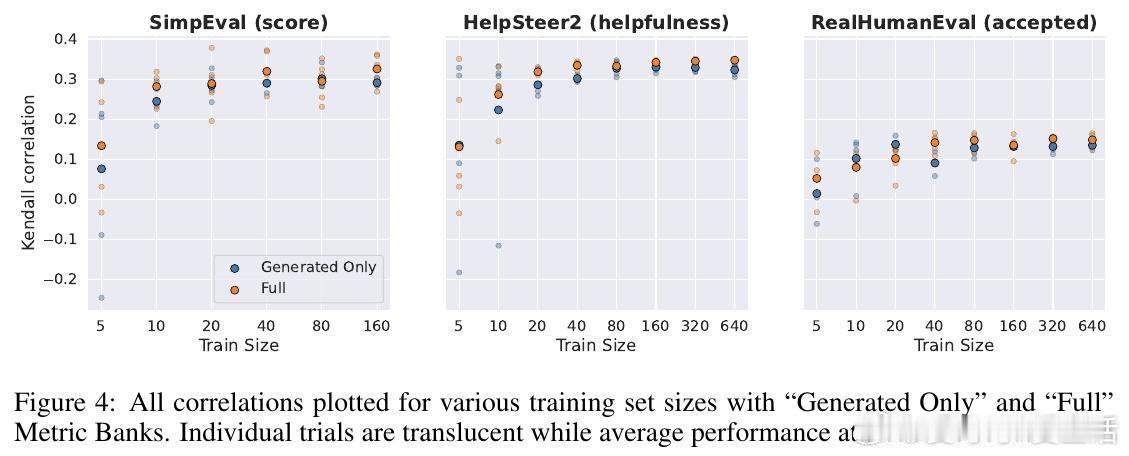
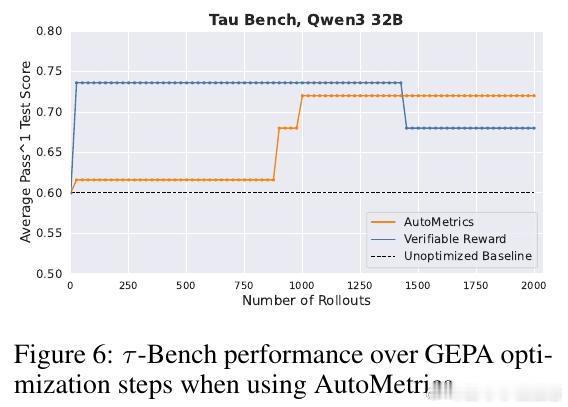
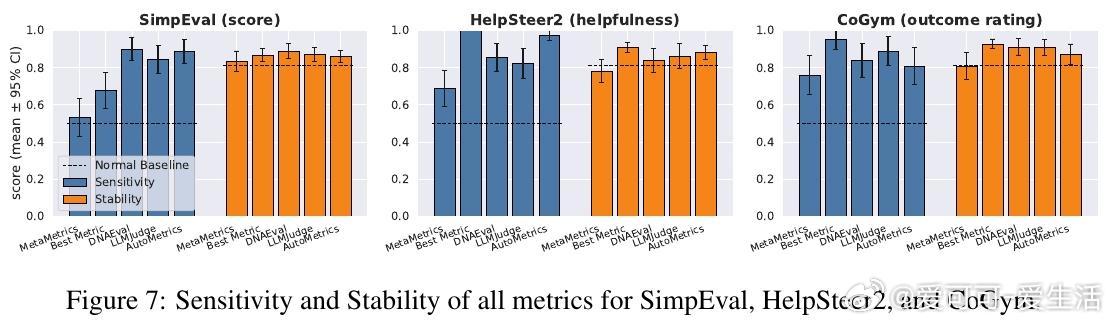
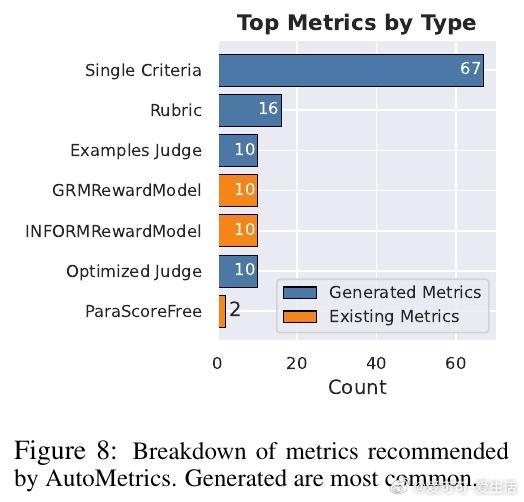
[CL]《AutoMetrics: Approximate Human Judgements with Automatically Generated Evaluators》M J. Ryan, Y Zhang, A Salunkhe, Y Chu... [Stanford University & American Express] (2025) 当AI应用以前所未有的速度涌现时,我们面临一个尴尬的现实:衡量AI好坏的速度,已经跟不上AI进化的速度。斯坦福大学与美国运通联合发布的最新研究 AutoMetrics,为这个难题提供了一个优雅的解法。它告诉我们:评估不应该是静态的尺子,而应该是随任务进化的罗盘。1. 评估的困境:黄金准则的奢侈与无奈在旅游规划、医疗记录生成或开放式对话等领域,人工反馈永远是黄金准则。但人工评估不仅昂贵、缓慢,而且无法规模化。目前的替代方案 LLM-as-a-Judge 虽然方便,却往往难以精准捕捉用户真实的偏好,甚至在不同任务间表现极不稳定。2. AutoMetrics:从稀疏反馈到精准度量的桥梁AutoMetrics 的核心逻辑在于:利用极少量的用户反馈(通常少于100条),自动合成一套高度拟合人类判断的评估指标。它不再依赖单一的提示词,而是通过一个系统化的流水线来构建度量衡。该框架包含四个关键步骤:- 生成:针对特定任务生成候选准则,包括评分量表、示例和提示词优化。- 检索:从内置的 MetricBank(包含48个经典NLP指标的库)中提取相关指标。- 回归:利用偏最小二乘回归(PLS)对所有候选指标进行加权,筛选出与人类信号相关性最强的组合。- 报告:产出可解释的评估报告,明确告知开发者哪些因素在影响最终得分。3. 数据效率的奇迹AutoMetrics 最令人惊叹的地方在于它的数据效率。实验证明,仅需约80个反馈样本,其生成的指标与人类评判的肯德尔相关系数(Kendall correlation)相比传统的 LLM-as-a-Judge 提升了高达 33.4%。这意味着开发者可以在原型阶段,用极低的成本换取极高的评估可信度。4. 从评估工具到优化引擎评估的终点不是打分,而是优化。研究显示,AutoMetrics 生成的指标可以作为代理奖励(Proxy Reward),在系统优化中达到与验证奖励(Verifiable Reward)同等的效果。在 Tau-Bench 智能体任务中,使用 AutoMetrics 引导的优化显著提升了智能体的成功率。5. 深度思考:评估定义了AI的上限如果说算法是AI的引擎,那么评估指标就是它的天花板。你无法优化一个你无法准确衡量的事物。AutoMetrics 的意义在于,它将评估从一种事后的静态审计,转变为一种动态的、可学习的系统能力。在低数据约束下,通过回归分析将传统度量(如词汇重叠)与现代LLM判断相结合,实际上是在利用历史的严谨性来约束大模型的灵活性。这种融合不仅提高了准确性,更赋予了自动化评估急需的可解释性。这一工具包和 MetricBank 的开源,将极大加速LLM应用从实验室原型向工业级产品的跨越。对于每一位在开放域苦于评估难度的开发者来说,这都是一份及时的指南。论文地址:arxiv.org/abs/2512.17267