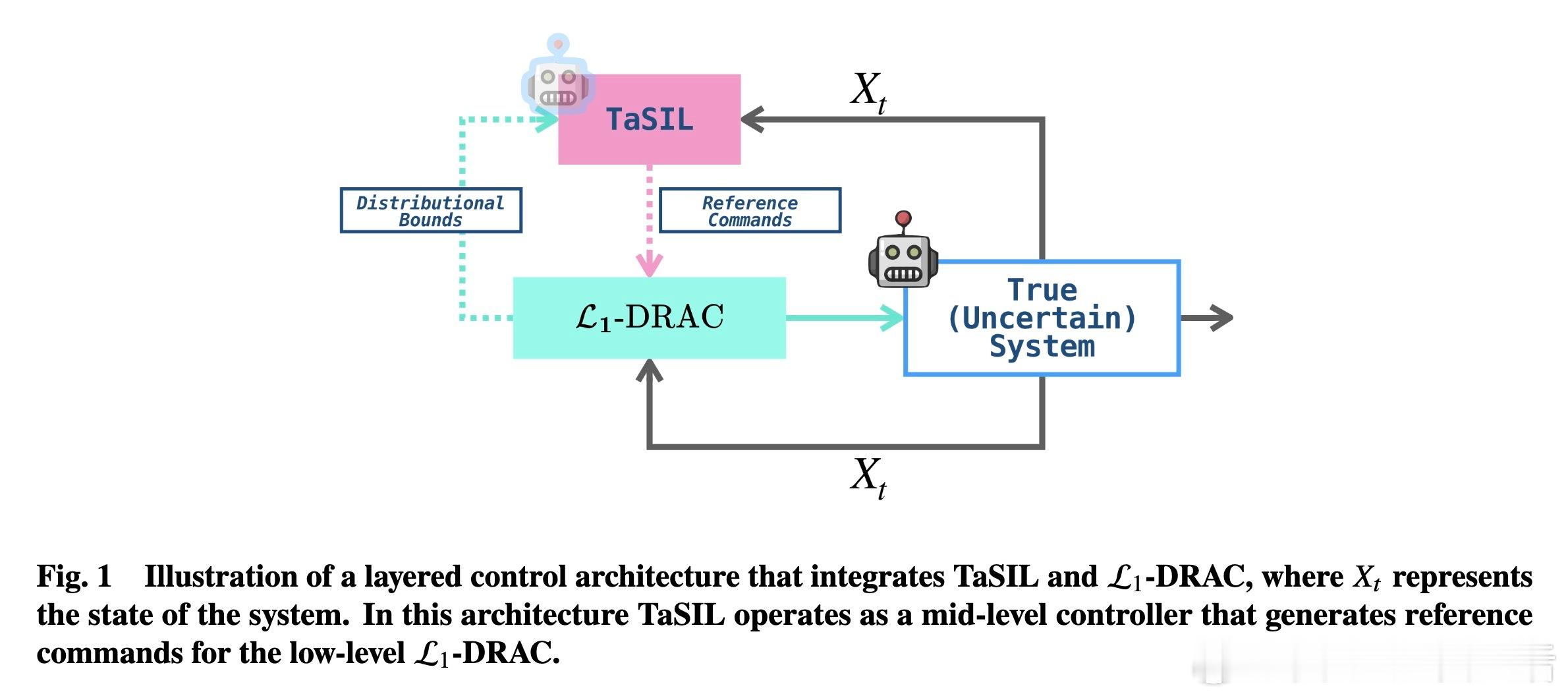
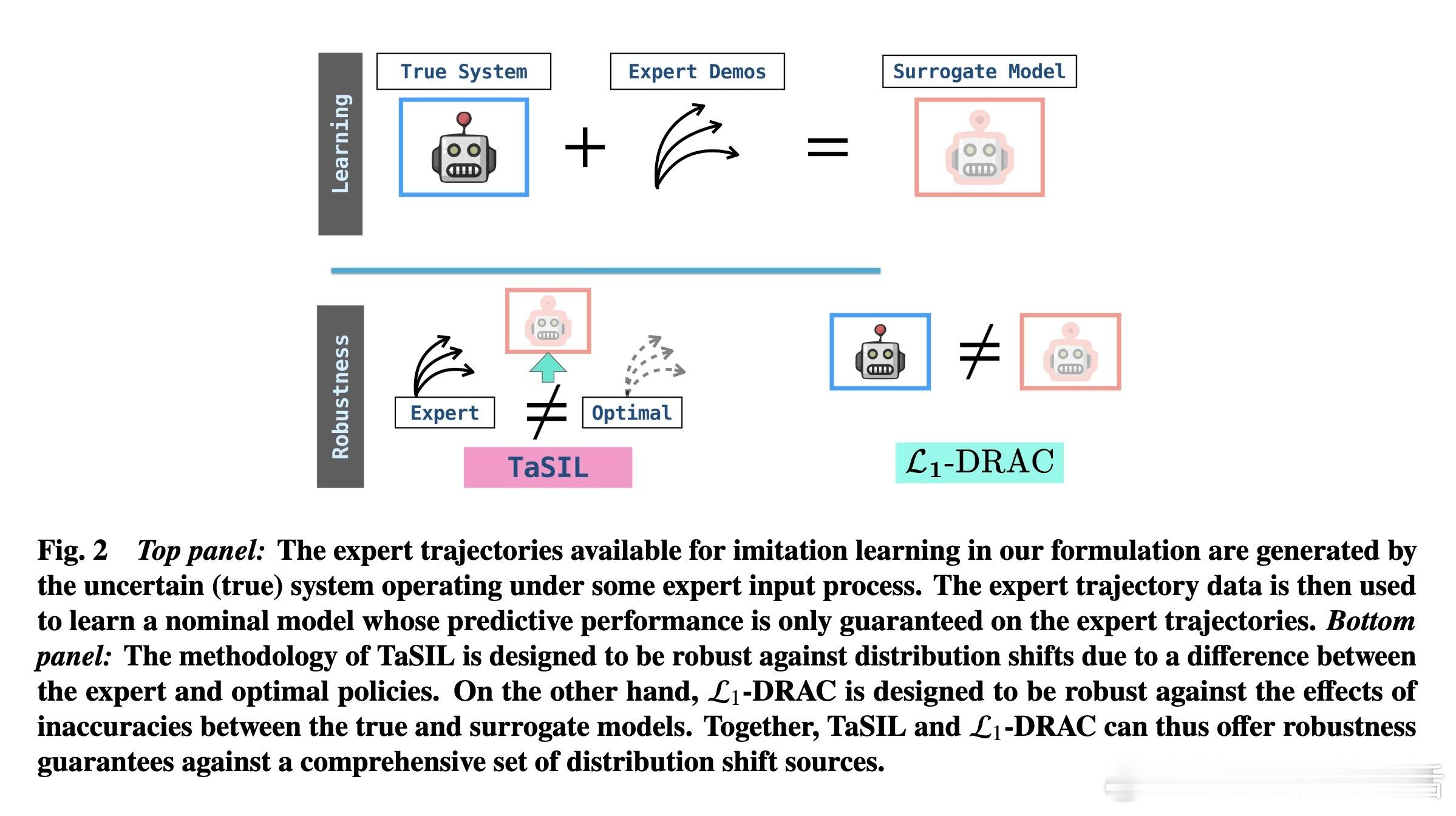
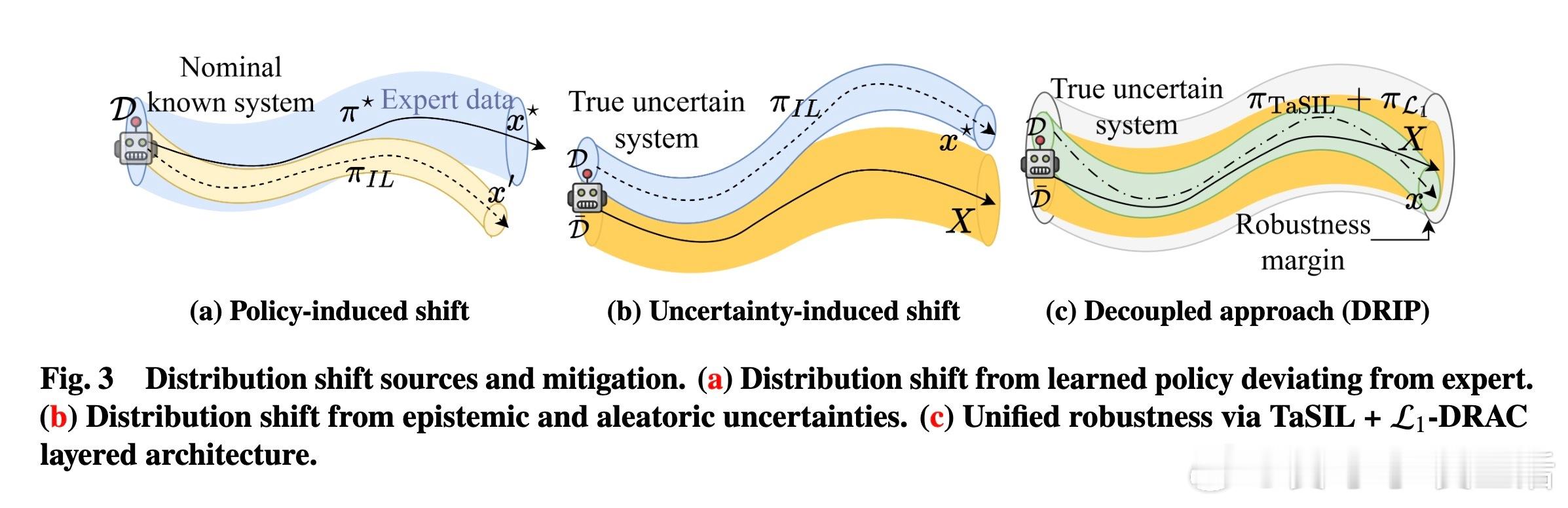
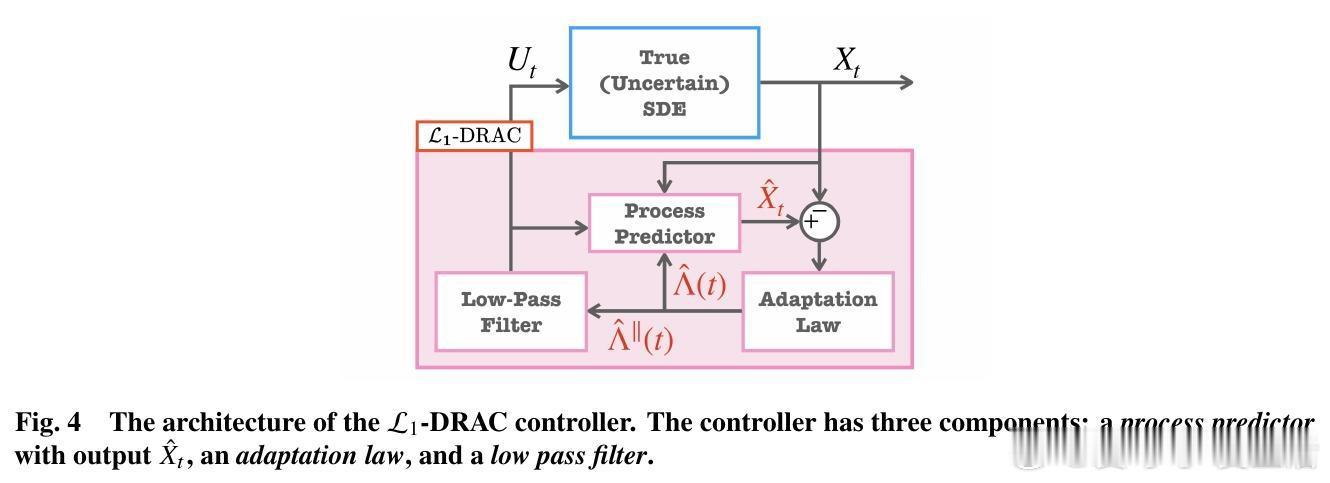
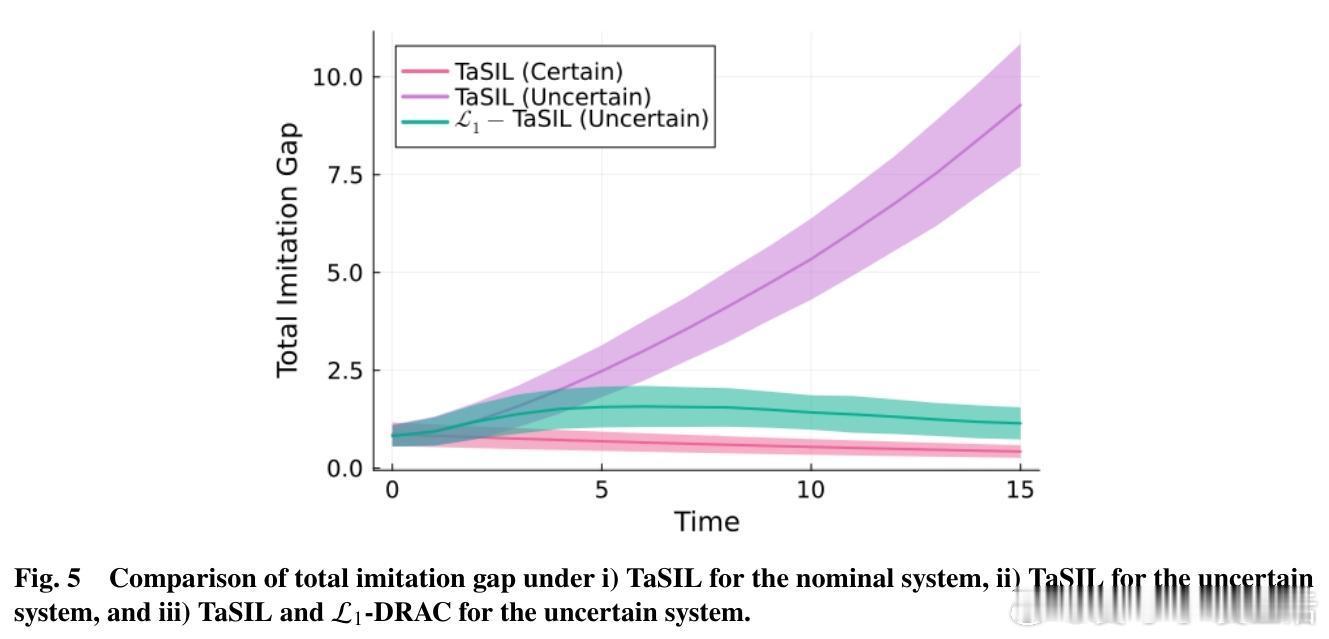
[LG]《Distributionally Robust Imitation Learning: Layered Control Architecture for Certifiable Autonomy》A Gahlawat, A Aboudonia, S Banik, N Hovakimyan... [University of Illinois Urbana-Champaign & University of Pennsylvania] (2025) 模仿学习(Imitation Learning)虽然高效,但在面对现实世界的复杂性时,往往显得脆弱。UIUC与加州理工、麻省理工等机构合作的最新论文提出了一种名为DRIP的分层控制架构,旨在解决自动驾驶和机器人领域最核心的痛点:分布偏移。这不仅仅是一个算法的改进,更是一次关于可验证自主系统(Certifiable Autonomy)的深度思考。1. 模仿学习的阿喀琉斯之踵模仿学习的核心在于复刻专家的行为。然而,在实际部署中,系统总是会不可避免地偏离专家轨迹。这种微小的偏离会随时间累积,形成模仿间隙(Imitation Gap)。分布偏移主要源于两个维度:一是策略误差,即学习者没能百分之百精准地掌握专家的意图;二是环境的不确定性,包括外部干扰、模型建模不精细以及传感器的随机噪声。2. 协同进化的双层架构:DRIP研究团队提出的DRIP架构,其核心逻辑在于解耦。它将复杂的鲁棒性问题拆解为两个相互配合的图层:中层控制器采用TaSIL(泰勒级数模仿学习)。它的任务是处理策略诱导的偏移。通过在学习目标中引入高阶灵敏度信息,TaSIL能让系统在偏离专家路线时,具备自我纠偏的意识。底层控制器则由L1-DRAC(L1分布鲁棒自适应控制)坐镇。它像是一个坚实的盾牌,专门抵御环境中的随机不确定性和系统建模误差。3. 整体大于部分之和DRIP最精妙之处在于,它证明了鲁棒性是可以叠加的。TaSIL保证了即使策略不完美,系统也能在名义模型下保持稳定;而L1-DRAC则确保了无论现实世界与名义模型之间存在多大的鸿沟,系统都能强行回归到名义行为上。这种分层设计实现了一种确定性:我们不需要一个全知全能的模型,只需要一个能感知边界并实时修正的机制。4. 迈向可验证的自主性传统的深度学习往往是黑盒,难以在安全关键型系统中获得认证。DRIP通过控制理论的严谨性,为整个控制管线提供了可证明的性能边界。这意味着,我们可以在保留感知层(如视觉识别)的高性能的同时,通过这套分层架构,为决策和执行层打上可验证的补丁。5. 深度思考与启发真正的鲁棒性,不是追求永不犯错,而是在犯错的瞬间就拥有重回正轨的能力。DRIP的成功告诉我们,解决复杂系统问题的最优解往往不是构建一个更庞大的单一模型,而是通过合理的架构设计,让不同的组件各司其职。解耦不是为了分离,而是为了更高级别的融合。这种训练一次、终身自适应的模式,摆脱了对昂贵模拟器和持续专家反馈的依赖,为可认证的自主系统铺平了道路。原文链接:arxiv.org/abs/2512.17899