
InfiniBand在高性能计算和人工智能领域占据核心地位,其高速、低延迟的网络通信能力支持大规模数据传输与复杂计算。在网络内计算领域,InfiniBand的应用日益广泛,通过内部计算降低延迟,提升系统效率,为HPC和AI领域带来卓越的性能与智能。InfiniBand,助力前沿科技迈向更高峰。
InfiniBand网络内计算:它是什么?InfiniBand网络内计算(INC)是InfiniBand技术的革新应用,通过整合计算能力于网络之中,显著提升系统性能。它精准解决AI与HPC中的通信瓶颈,为数据中心的可扩展性带来全新视角,是网络计算领域的杰出创新。
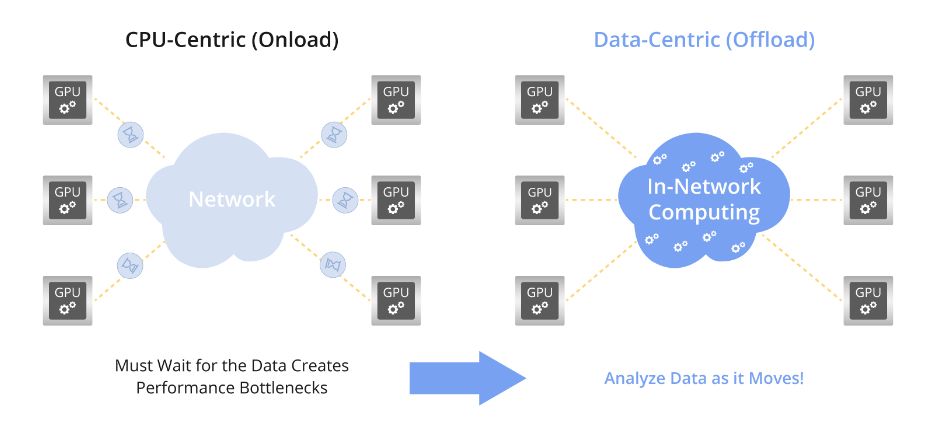
In-Network Computing理念革新性地将计算功能融入InfiniBand网络的交换机和适配器,实现数据传输与简单计算并行。此举直接消除了将数据转移至服务器等终端节点的需求,极大提升了数据处理效率,展现了前所未有的网络计算新境界。
数据中心中的InfiniBand网络内计算现代数据中心正迈向分布式并行处理架构新纪元,受云计算、大数据、高性能计算和AI推动。CPU、内存、存储资源分散于数据中心,经InfiniBand、以太网、光纤通道及Omni-Path高速网络紧密连接。协同设计与分工合作共促数据处理高效完成,构建以业务数据为核心、均衡的系统架构,引领数据处理新潮流。
InfiniBand网络内计算革新数据处理方式,将计算任务移至网络内部,释放CPU压力,实现集成化网络计算,大幅减少延迟,显著提升系统性能。其关键技术如网络协议卸载、RDMA、GPUDirect等,实现在线计算、低延迟通信及高效数据传输。这一深度集成方案为高性能计算和AI应用注入强大动力,引领计算技术新纪元。
InfiniBand网络内计算的关键技术网络协议卸载InfiniBand网络适配器和交换机全面处理网络通信协议栈,包括物理层至传输层,其卸载技术省去了额外软件和CPU资源,极大提升了通信性能,实现高效数据传输。
RDMARDMA技术革新网络传输,突破数据处理延迟瓶颈。它通过直接内存间传输,无需CPU介入,极大降低延迟,显著提升网络传输效率,为服务器端数据处理带来革命性优化。
RDMA技术让用户应用程序直接传输数据至服务器存储,数据再经网络高速传至远程系统存储。这一创新过程避免了重复数据复制与文本交换,显著减轻CPU负担,实现高效数据传输。
GPUDirect RDMAGPUDirect RDMA技术运用RDMA功能实现GPU节点间直连通信,显著提升GPU集群通信效率。
GPUDirect RDMA技术实现了集群内GPU进程间的直接通信,允许RDMA适配器直接在节点间GPU内存传输数据。该技术无需CPU介入,减少了PCIe总线访问,避免了不必要的数据复制,从而显著提升通信性能,实现高效的数据传输。
SHARPSHARP,一种专为高性能计算和AI应用设计的集体通信网络卸载技术,通过可扩展层级聚合与减少协议,显著提升集体通信的效率。
SHARP将计算引擎单元集成到InfiniBand交换机芯片中,支持各种定点或浮点计算。在包含多个交换机的集群环境中,SHARP在物理拓扑结构上建立一个逻辑树形结构,使得多个交换机能够并行且分布式地处理集体通信操作。这种SHARP树状结构的并行和分布式处理极大地减少了集体通信的延迟,减轻了网络拥塞,并提高了集群系统的可扩展性。该协议支持诸如屏障(Barrier)、Reduce、All-Reduce等操作,从而提升了大规模计算环境中的集体通信效率。
InfiniBand网络内计算应用:HPC与AIInfiniBand在网络内计算在高性能计算中的应用在高性能计算(HPC)领域,InfiniBand对于缓解CPU/GPU资源竞争至关重要。其通信密集特性要求高效通信协议支持。为此,卸载技术、RDMA、GPUDirect及SHARP等技术得到广泛应用,以优化计算性能,特别是在处理计算密集型任务时,这些技术更是不可或缺。
InfiniBand网络内计算在人工智能中的应用人工智能的前沿发展高度依赖InfiniBand网络内计算,加速训练过程,实现高精度模型。当前,GPU或专用AI芯片是训练平台的核心,通过InfiniBand显著提升训练效率。卸载应用程序通信协议对降低AI训练延迟至关重要。GPUDirect RDMA技术强化GPU集群间通信带宽,显著减少通信延迟,为AI训练注入强劲动力。
结论InfiniBand网络内计算,作为HPC与AI领域的革新技术,高效可靠地支撑计算需求。作为信息技术的重要创新,它持续推动网络计算技术向前迈进,展现无限潜力。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
