

论文:LLM Pruning and Distillation in Practice: The Minitron Approach
链接:https://d1qx31qr3h6wln.cloudfront.net/publications/minitron_tech_report.pdf
单位:nvidia
研究背景这篇文章要解决的问题是如何通过剪枝和蒸馏技术来压缩Llama 3.1 8B和Mistral NeMo 12B模型,分别将其参数规模减小到4B和8B。
该问题的研究难点包括:如何在没有原始训练数据的情况下,通过微调教师模型来减少数据分布不匹配的问题;如何有效地进行模型剪枝和蒸馏以保持模型的准确性。
之前的研究表明,结合权重剪枝和知识蒸馏可以显著降低大型语言模型(LLM)的训练成本;现有的Minitron压缩策略已经被证明在减少模型大小和提高推理性能方面是有效的。
研究方法
这篇论文提出了使用剪枝和蒸馏技术来压缩Llama 3.1 8B和Mistral NeMo 12B模型的方法。具体来说,
教师模型微调:由于无法访问原始训练数据,首先对教师模型在目标数据集上进行微调,这一步骤被称为教师校正。剪枝:接下来,应用剪枝技术来压缩模型。剪枝是一种通过移除模型权重中非零元素块来减小模型大小的技术。本文关注的剪枝方法包括深度剪枝和联合隐藏层/注意力头/多层感知器(MLP)宽度剪枝。蒸馏:使用蒸馏技术来恢复剪枝后模型的任何损失准确性。蒸馏涉及从较大的或更复杂的模型(称为教师模型)向较小的/较简单的模型(称为学生模型)转移知识。
细节解释
重要性估计:使用基于激活的重要性估计策略,同时计算所有考虑的轴(深度、神经元、头和嵌入通道)的敏感性信息。对于深度剪枝,使用三种不同的指标来评估层的重要性:
句子验证损失块重要性(BI)下游任务的准确性模型修剪:根据计算的重要性对每个轴的元素进行排序,并直接对相应的权重矩阵进行修剪。对于神经元和注意力头剪枝,分别修剪MLP和MHA层的权重;对于嵌入通道,修剪MLP、MHA和LayerNorm层中的嵌入维度。
实验设计数据集:使用Nemotron-4策划的持续训练数据集(CT)进行所有实验。
剪枝配方:基于Minitron论文中的最佳实践,具体如下:
宽度剪枝:使用l2范数和均值作为批处理和序列维度的聚合函数,执行单次剪枝,避免迭代方法。深度剪枝:遵循Gromov等人的观察,删除导致Winogrande上准确性下降最小的连续子组层。蒸馏:在蒸馏过程中,使用前向KL散度损失来最小化教师和学生概率的对数似然损失。蒸馏过程包括对教师模型进行微调和蒸馏。
结果与分析基础模型评估:与类似大小的模型相比,MN-Minitron-8B模型在所有基准测试中表现出更高的准确性,超过了最近的Llama 3.1 8B模型。Llama-3.1-Minitron 4B模型在准确性和训练效率上也表现出色,宽度剪枝变体优于深度剪枝变体。

指令调优模型评估:在指令跟随和角色扮演任务中,Llama-3.1-Minitron 4B模型表现强劲,仅次于Gemma2。在基于检索的问答和任务调用任务中,Minitron模型达到了最先进的性能。

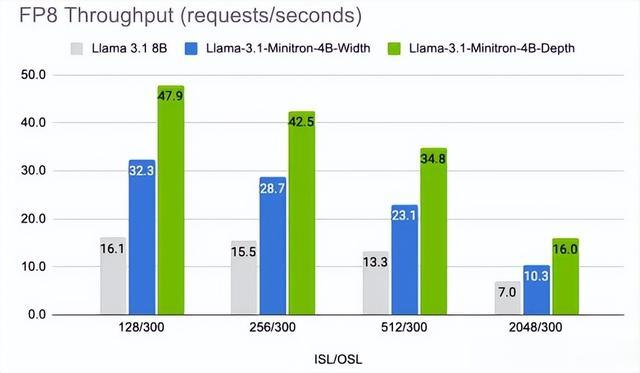
运行时性能分析:使用NVIDIA TensorRT-LLM优化后的模型在推理性能上也有显著提升。Llama-3.1-Minitron-4B-Depth变体在推理性能上平均提高了约2.7倍,而Llama-3.1-Minitron-4B-Width变体平均提高了约1.8倍。MN-Minitron-8B模型比Mistral NeMo 12B模型平均快了1.2倍。
 总体结论
总体结论这篇论文提出了一种通过剪枝和蒸馏技术来压缩大型语言模型的有效方法。研究结果表明,MN-Minitron-8B模型在准确性和推理性能上均达到了最先进,而Llama-3.1-Minitron 4B模型在保持高准确性的同时显著提高了训练效率。研究还强调了教师模型微调在蒸馏过程中的重要性,并展示了宽度剪枝在提高模型准确性方面的优势。
