近期,DeepSeek无疑成为了众人瞩目的焦点,这款由杭州深度求索人工智能基础技术研究有限公司开发的高性能大语言模型,凭借其出色的的智能问答、文本生成、代码编写和多模态交互能力成功刷屏各大平台。基于深度神经网络算法并结合大规模自监督学习与针对性优化训练,DeepSeek能理解并生成自然语言,为用户提供有价值的回答和建议。那么,如何在本地部署DeepSeek呢?本文将为您提供详细的教程和步骤,快一起来看~
Deepseek本地部署配置选择DeepSeek有提供多种模型版本以满足不同用户需求,具体如下所示,建议根据技术进展定期更新。
模型版本
模型大小
显存要求(单精度)
CPU核心数
内存要求
推荐显卡型号(单卡/多卡)
适用场景
1.5B
~2.3GB
≥6GB
4核+
16GB
RTX 3050 6GB/GTX 1660 Super
基础文本生成、轻量级图像分类
7B/8B
~14GB/16GB
≥10GB
8核+
32GB
RTX 3060 12GB/RTX 4060 Ti 16GB
中等复杂度NLP推理、代码补全
14B
~28GB
≥20GB
12核+
64GB
RTX 4090 24GB/RTX 6000 Ada 48GB
多模态推理、工业级数据分析
32B
~64GB
≥48GB(单卡)
16核+
128GB
NVIDIA RTX A6000 48GB/双RTX 4090 NVLink
企业级知识图谱构建、3D渲染
70B
~140GB
2×H100 80GB
32核+
256GB
NVIDIA H100 HGX 双卡配置(NVLink)
大语言模型全参训练、科学仿真
671B
~350GB
4×H100 80GB
64核+
512GB
DGX H100 SuperPOD 8卡系统
(InfiniBand)
超大规模AI研究、通用人工智能(AGI)探索
DeepSeek简化部署流程指南为了让用户更轻松便捷地部署DeepSeek模型,我推荐借助聪明灵犀软件,不仅内置多种DeepSeek模型版本可供自由选择,而且整个操作过程流畅且安全!
1、部署DeepSeek模型
▪ 下载安装后打开软件,找到并点击首页的【一键本地部署deepSeek】下的“立即体验”。
▪ 进入页面后先选择下载模型与安装地址,然后等待模型下载完成。这个过程可能需花费一些时间,具体取决于网络速度和模型大小。

2、与模型对话
▪ 模型安装好后直接点击该页面的“立即体验”即可启动CherryStudio。
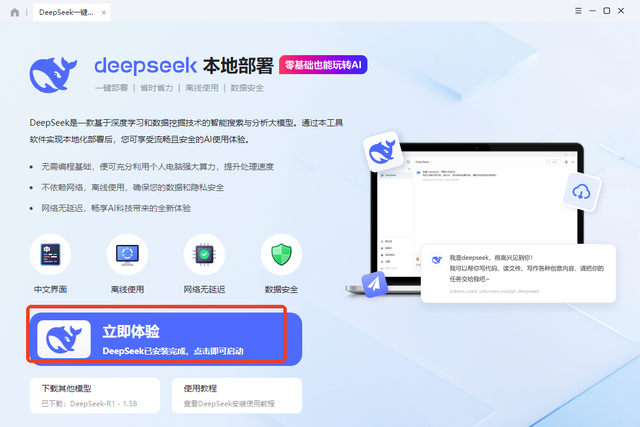
▪ 在新打开界面找到并点击左下角的“设置”图标。

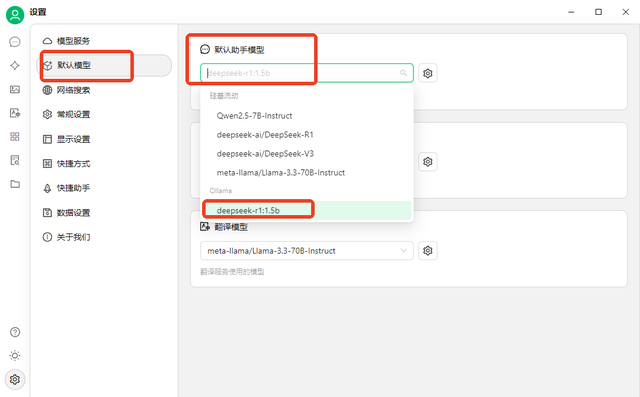
▪ 在弹出的“设置”窗口点击“模型服务”选择“Ollama”,开启该模型后按下底部的“管理”。

▪ 在弹出的“管理”窗口下会显示不久前已下载的模型,然后点击右侧的“+”,在Ollama“模型”列表中显示即为添加成功。

▪ 切换到“默认模型 ”选项并将默认助手模型设置为刚才添加的模型。
▪ 切换回对话界面,此时可以看到所用模型就是刚添加成功的那个。如果不是,点击即可快速调整。

▪ 在界面底部输入消息并发送就能进行聊天了,还支持开启网络搜索和上传文档以获取更丰富的对话体验。

以上就是今天的全部内容分享了,希望能帮助大家轻松实现DeepSeek模型的本地部署,并与其展开智慧交流,从而更充分地发挥DeepSeek模型的卓越潜能!
