随着大语言模型(Large Language Model, LLM)的高速发展,LLM已经逐渐渗透到我们的日常工作生活中。而上下文长度是LLM应用的一个重要研究方向,它决定了Chabot多轮对话中的对话轮数、检索增强生成(Retrieval-Augmented Generation, RAG)中的检索材料长度,以及各类Agent的工具数量等。同时,长文本能力在淘宝已有非常广泛的应用场景,比如商品理解,基于Agent的对话客服等。但是直接训练长上下文的LLM所需要的成本是十分昂贵的,因此文本扩长技术是一种高效的方法。但是现有的长文本扩长方法需要额外的训练阶段来进行扩长,且需要准备长文本数据。为了解决这一问题,我们提出一种用于LLM高效扩长的方法E2-LLM。该方法仅需要一个训练阶段,而且无需收集长文本数据,支持短文本训练,任意长度推理。基于该工作整理的论文已发表在ACL 2024,欢迎阅读交流。
作者|幕兴、文泱、气节等
论文|E2-LLM: Efficient and Extreme Length Extension of Large Language Models
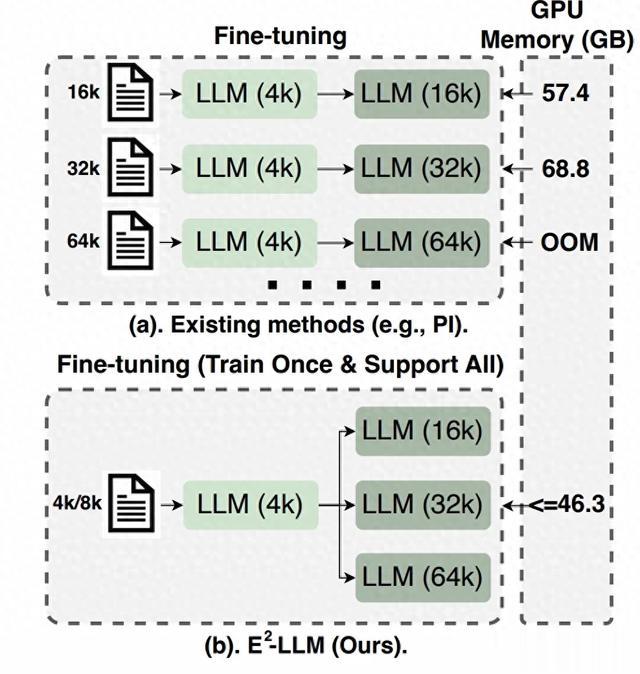
图1. 现有扩长方法比较,带有浅色的“LLM (4k)”是指带有默认上下文窗口的LLM(例如,带有4k的LLaMa2)。颜色较深的“LLM (16k/32k/64k)”表示微调后具有扩展上下文窗口(16k/32k/64k)的LLM。(a)对于现有的方法,我们需要收集长上下文数据(例如,16k/32k),并微调LLM模型,以适应GPU内存使用率高的不同上下文扩展窗口。(b).对于E2 -LLM,我们直接使用短上下文数据(例如,4k/8k),只训练llm一次,使用可接受的GPU内存使用量,并在推理时支持不同的评估上下文窗口(例如16k/32k/64k)。
在文章开始前,为了更好的描述方法细节,这里还是有必要首先介绍符号定义,设计本方法相关的符号会在介绍过程中引入。
: 表示预训练期间的最长文本长度。
: 表示扩长后的目标文本长度。
: 表示上下文中的具体位置,。
: 表示每个attention head的维度。
: 表示输入的的embedding vector序列,。
: 表示预训练的LLM。

本方法在旋转位置编码(Rotary Position Embedding, RoPE)上进行扩长。我们希望可以在短文本上训练,长文本上推理。因此我们提出了两种不同的扩长方法,分别从不同单位间距和相对距离角度进行扩长。

首先,RoPE可以按照下式进行表示:
其中表示虚部单元,。
基于此我们在计算self-attention的attention score 按照下式进行计算:
其中和表示query vector和key vector。
因为RoPE的这种只和m-n相关的编码性质,位置插值(Position Interpolation,PI)被提出,用于将更长的q和k之间的相对距离范围压缩到训练区间内,通过内插方式,允许LLM处理更长的文本。公式如下所示:
将位置编码范围从压缩到,其中,因此我们可以定义一个缩放的参数,因此上式可以变为:
本方法在PI中进一步引入了位置偏移,如下式所示:

在训练阶段通过动态调整位置编码密度,来增强LLM对于不同单位间距的鲁棒性,公式如下所示
我们从G中按照分布P来采样g,我们观察到对于不同数据,使用的相对距离密度是不一样的。可见图2中,对于g取2,5,10的时候,我们的密度差距各异的,当g取2时,可以实际训练到最长度为8192的相对距离密度。而当g取10的时候,内插距离密度等价于上下文长度40960压缩到4096内。
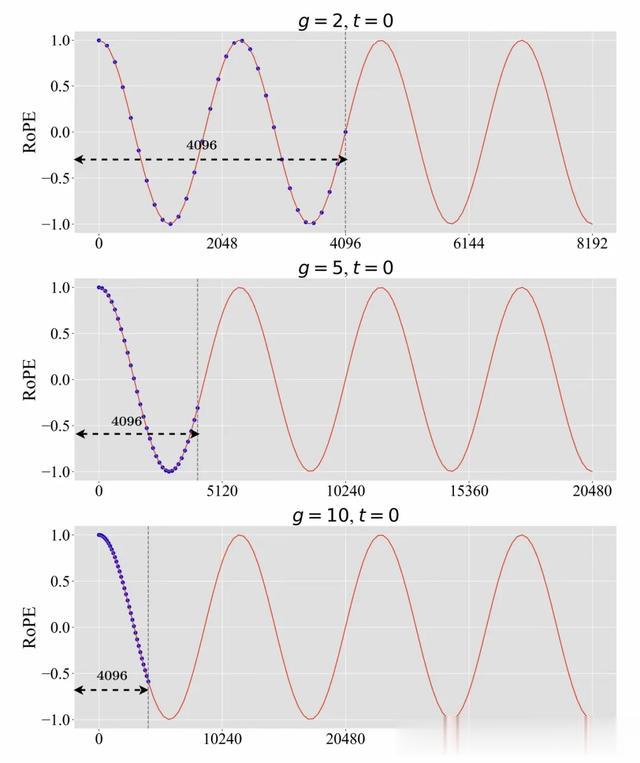
图2. 使用不同尺度参数(即g = 2,5,10)时训练的位置指数(蓝色点)。为了说明,将位置偏移量t设置为0。

我们发现仅使用基于缩放系数g的增强仅仅改进的相对距离,而真实的相对距离还是未经过训练的,为了进一步优化鲁棒性和生成效果。我们提出基于偏移距离t的位置编码增强,来改变RoPE的相对距离。相关工作发现很大一部分的attention score会关注在开始位置的token上,因此本方法也保持了初始Token的偏移不变,而修改其它Token的偏移,而且该参数也是随着训练一直在改变的。第次迭代的距离偏移的计算方式如下式所示。
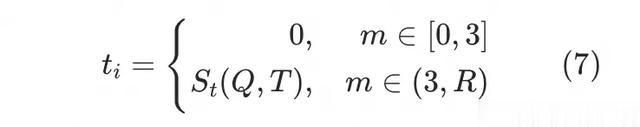
其中表示以预设的概率分布,对进行采样,。对于key vector的绝对位置索引, query vector的绝对位置索引,attention score计算公式可以被重写为下式。
因此越大,和之间的相对位置距离就越大。这可以让模型适应不同相对距离范围的位置。
如下图所示,我们选择的时候,我们可以学习到的相对距离最远为4092+4096=8188。
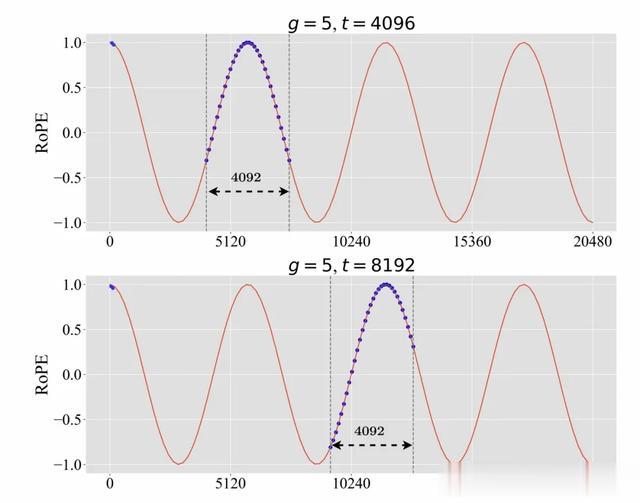
图3.使用不同位置偏移距离时的训练位置指数(蓝色点),为了可视化,将g设为5。前四个标记的位置索引不被移动。

E2-LLM方法可以仅仅训练一次,就适配不同长度的推理任务。
训练过程:我们训练LLM使用较短的上下文长度,在每一次迭代过程中,同时替换和,位置编码形式如下所示。
为了更清晰介绍训练过程,我们通过下面的伪代码进行介绍。

图4. E^2-LLM 训练伪代码。
推理过程:一阶段训练完成后,我们不需要进行任何额外的训练阶段,或者调整模型结构。我们仅仅需要根据实际需要的推理文本长度修改参数即可,例如我们需要推理32768长度的文本,那么我们设置,而当需要65536长度时,则设置。而且我们可以仅仅部署一个模型就适配不同长度的推理。


基座模型:基于Llama2-7B和Llama2-13B上使用E2-LLM方法来展示方法的有效性。
训练设置:训练资源为两台8卡A100,我们使用Adamw优化器,,学习率设置为,总共训练步数为30000步,每一步的batchsize为16。
数据集: 训练集合包括Pile、ShareGPT和长文本总结数据集,测试集包括Proof-Pile以及LongBench。

1. LongBench实验结果
我们对比了一些具有长上下文的LLM,包括GPT3.5-Turbo-16k,Llama2-&b-chat-4k,LongChat-v1.5-7B-32k, Vicuna-v1.5-7B-16k,LongLora-7B-16k,Llama2-13B-chat-4k,Vicuna- v1.5-13B-16k,PI-Llama2-13B-16k。
结果如下表所示。首先,相比于商业模型(GPT-3.5-Turbo-16k),我们的方法在英文上取得较为接近的结果44.55% vs 44.60%。其次,随着E2-LLM模型的评测长度增加,我们的得分是逐步上升的,而对于部分评测集长度未达到16k,这部分的得分是无明显变化的。最后,为了公平对比,我们和PI-Llama2-13B-16k对比,我们使用相同的数据和训练策略,仅保证位置插值的方式不同,可以看到我们的方法取得显著的提升。
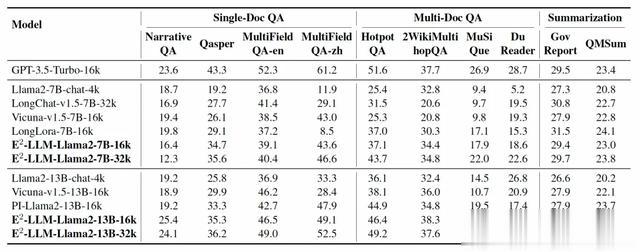
表1. Longbench中单文档问答, 多文档问答以及摘要任务的多模型对比。
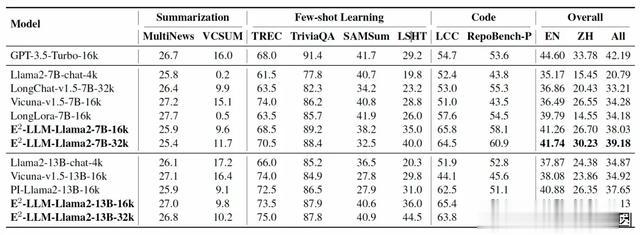
表2. Longbench中的摘要任务, few-shot learning以及代码任务的多模型对比。
2. Proof-Pile实验结果对于Proof-Pile数据集,我们随机选择128个超过64k的文档,计算LLM在这些文本上的困惑度(perplexity, PPL),所有的PPL计算使用滑动窗口。对比的模型是Vicuna-v1.5-16k和LongChat-v1.5-32k,这两个模型都是在llama2上通过PI进行扩长的,结果如下所示,相比于对比模型,提出的方法取得了显著的优势。而且我们仅仅需要4k的训练,而对比的方法均需要长文本训练。

表3.多模型在Arxiv Proof-pile dataset上的ppl对比,其中的PI表示位置插值。
3. 消融实验3.1 不同增强策略对比我们在Longbench上,分别加入增强策略和,可以看到仅用单增强策略,均不如两个策略一起使用,因此说明两种增强策略均可获得收益。

表4. 消融实验
3.2 不同训练步骤的效果为了了解训练过程中,LLM长文本能力的情况,我们对比了不同迭代次数的Longbench得分,如图4所示。前5k迭代时,我们可以看到模型在没有使用长文本训练的情况下,快速提升长文本提取能力,而在5k步后,随着训练次数的增加,整体是呈现稳定上升趋势的。
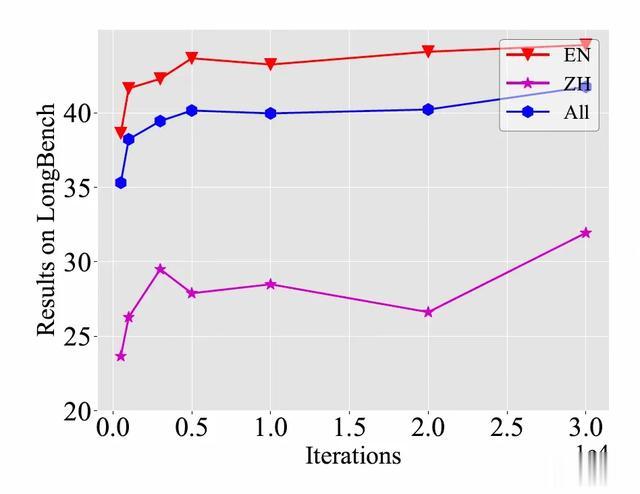
图5. 随着训练过程Longbench得分变化

扩展到未训练长度E2-LLM方法不仅仅可以在理论范围内支持更长文本,还有较好的外推性。因此我们在训练过程中设置,理论支持最大的上下文长度为80k,我们设置不同的插值方法去测试不同长度下文本的PPL。结果如图5所示。可以看到仅仅在4k上训练的模型,可以在100k中保持较好的PPL,这可以说明我们的方法在OOD 比例上也可以较强的鲁棒性。

图6. 在未见过位置上的泛化能力
近期,我们还成功将方法E2-LLM应用在Llama2-7B和Llama2-13B上,仅用较少的训练资源,扩展上下文长度到200k。效果见图6。

图7. 在200k上下文长度上的泛化能力
可视化Attention Map为了进一步分析E2-LLM对LLM训练的实际影响,我们分析了attention map,我们在E2-LLM-8k、E2-LLM-16k、E2-LLM-32k和E2-LLM-64k上做了详细的分析。如图7中所示,纵轴表示输出的位置,横轴表示输入token的位置序号。我们找了一些较长的paper,分别截断到8k、16k、32k和64k。然后我们随机在截断后的文本中插入3个key-value对,最后在文本末尾插入一个问题。正确答案的位置在8k、16k、32k和64k中分别在[4470,4503], [9572,9605], [15891,15924] 和 [37958, 37991]。根据我们的可视化结果,我们观察到输出序列在这些位置 的注意力 值非常显著,这表明E2-LLM 在生成时可以很好地索引正确的位置。

图8. 在8k、16k、32k以及64k输入长度下的attention heatmap可视化
我们提出E2-LLM方法,在RoPE方法上通过两种增强策略,仅用一阶段训练且不需要长文本数据,就可以高效的扩展LLM上下文长度。在多个benchmark上,都证明我们提出方法的有效性。未来我们希望从以下三个方面改进:(1)受限于资源限制,本次实验仅在7B和13B上验证,未来我们将在更大的模型(例如 Llama2-70B或Qwen2-72B)和更长的上下文长度(例如 128k或192k)上验证方法的效果。(2)E2-LLM是一个通用的方法,我们未来尝试应用于不同的位置编码方法上。(3)我们将继续推进将该方法应用于淘天更广泛的业务场景。
作者:幕兴、文泱、气节等
来源-微信公众号:淘天集团算法技术
出处:https://mp.weixin.qq.com/s/zm9n8dMNkHXIO8GBuytjww
