ES 进行信息检索的时候,boolean 查询组合条件有 must/must_not/should/filter四个操作。
其中 must 和 filter 的用途都是用于过滤必要符合的条件,但是 filter 在查询过程中不算分并且可以进行缓存,这样逻辑简单又可以加速的查询方式经常得到官方的提倡。
可是,只有 filter 的条件可以被缓存么?这里的缓存是属于哪一部分?
缓存有什么样的进入和淘汰机制?怎么去监控缓存的使用情况?
这些问题也会伴随着对 Elasticsearch 的深入使用自然而然的产生。
本文中,我们结合官方的一些资料进行探索。
2、什么是 Filter Context?仔细去看官方的文档可以发现,在 filter 的使用介绍里是这么写的。
Filter clauses are executed in filter context, meaning that scoring is ignored and clauses are considered for caching.
这里不仅措辞严谨的说 filter 条件以 filter context 的方式执行,
并在如下官方链接做了详尽解释。
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-filter-context.html#filter-context
简而言之,filter context 主要用于查询的过滤条件,并且不用算分,与 bool 的 filter 条件没有严格关联,除了 bool 的 filter 外,bool 中的 must_not, constant_score 查询中的 filter,聚合中的 filter 也都属于。

filter context
3、如何进入 Query Cache现在我们来看看查询是怎么进入 Query Cache的:
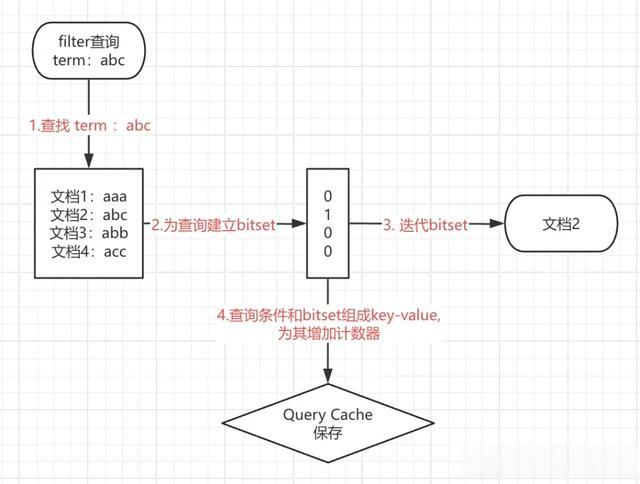
3.1. 找到匹配文档在倒排索引中找到 filter 条件符合的词项,并在所有的文档中检索这个词项。
3.2. 建立一个位图 bitset建立一个只包含1和0的位图 bitset,这个 bitset 用于描述所有文档的匹配情况,匹配的文档被设置为1。ES 实际执行时,使用的是 RoaringBitMap。
3.3. 迭代 bitset一旦为某个查询生成了 bitset, Elasticsearch 就会遍历 bitset 以查找满足所有过滤条件的匹配文档集。
执行顺序通常是首先迭代最稀疏的bitset(因为它排除了最多数量的文档)。
3.4. 增加使用计数把查询条件和其结果的 bitset 组合作为 key-value 进行缓存,这里利用对查询条件的使用记录来判断是否进缓存。
简单来说,如果一个查询在最近的256个查询中被多次使用,它将被缓存在内存中。更为详细的保留机制见下一节。
 4、Query Cache 的缓存机制
4、Query Cache 的缓存机制总体来说,Query Cache 是 Lucene 层面实现的,ES 层面会进行一些策略控制和信息统计。
Query Cache 仅应用于相对较大的 segment。
对于文档数少于 1 万或 segment 大小(size,单位:MB、GB等)小于整体索引大小 3% 的 segment(如下公式),Query Cache 将不启用。
docs_count(segment) < 10000 || segment.size < 3%*index.size因为小 segment 的查询本身已经足够快,不需要缓存来加速。
其管理策略类是 lucene 的 UsageTrackingQueryCachingPolicy,符合 LRU 的规则,也就是说 Query Cache 中的查询结果长时间不被访问会被优先淘汰。
这里判断是否被缓存的方法是shouldCache(Query query),有兴趣的同学可以去研究下
判断是否可以缓存的主要规则如下:
判断是否为 filter 查询assert query instanceof BoostQuery == false;命中永不缓存 shouldNeverCache 条件的淘汰,其中包括:TermQuery、MatchAllDocsQuery、MatchNoDocsQuery、以及子查询为空的BooleanQuery、DisjunctionMaxQuery某些大于特定阈值的查询可以被缓存:3.1 大于2次:MultiTermQuery、MultiTermQueryConstantScoreWrapper、TermInSetQuery、PointQuery(在 isCostly方法中定义)3.2 大于5次:除了上面列出条件的所有 filter 查询5、使用和观测 Query Cache最后,我们来看下怎么去使用和观测 Query Cache。
默认情况下节点的 Query cache最多缓存 10000个子查询的结果,或者最多使用堆内存的10%,都可以通过配置来调整:
indices.queries.cache.count #默认 10000indices.queries.cache.size #默认 10%对 Query Cache 也可以进行人工清理:POST /<index>/_cache/clear?query=true
而 Nodes stats API 和 Index stats API 都提供了 Query Cache 的监控
"query_cache": { "memory_size_in_bytes": 1110305640,//使用的size "total_count": 45109997,//历史查询总条数 total=hit+miss "hit_count": 1192144,//命中的 "miss_count": 43917853,//未命中的 "cache_size": 1309,//当前缓存的条数 "cache_count": 51509,//历史缓存总条数 "evictions": 50200//被驱逐的条数}使用小建议:
当 evictions 大量发生时,缓存被大量置换,对高敏感的业务可能会有一定的查询抖动。在监控项上添加一个 hit/total 的百分比监控,更加直观。6、小结本文短暂总结了 Filter context 如何形成 Query Cache 并进行维护观测的整体流程。
其中对 Query Cache 和其他缓存有兴趣的同学可以研读张超老师的文章:
https://mp.weixin.qq.com/s/q5iN2rOwkb0Bw1MXowZ6LQ
重点:Filter context 本身可以省去复杂的算分过程,再加上 Query Cache 的加速优势,建议大家在编写只需要匹配过滤查询语句中优先选择。
也就是:实际业务开发能使用 filter 过滤的,记得一定加上!
作者介绍金多安,Elastic 认证专家,Elastic资深运维工程师,死磕Elasticsearch知识星球嘉宾,星球Top活跃技术专家,搜索客社区日报责任编辑
来源-微信公众号:铭毅天下Elasticsearch
出处:https://mp.weixin.qq.com/s/Jsgx_RL0T794Z2bxuKtqOA
