Ollama 是一个开源框架,专门为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。它的目标是简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型。Ollama 的主要特点包括轻量级与可扩展性、API 支持、预构建模型库、模型导入与定制、跨平台支持以及命令行工具与环境变量等。它支持从特定平台导入大型语言模型,兼容 PyTorch 或 Safetensors 深度学习框架,并允许用户添加或修改提示以引导模型生成特定类型或风格的文本输出。此外,Ollama 提供了针对 macOS、Windows(预览版)、Linux 以及 Docker 的安装指南,确保用户能在多种操作系统环境下顺利部署和使用。
Ollama 本地安装流程步骤 1:下载 Ollama访问 Ollama 的 官方下载页面 或者直接从 Docker Hub 获取相应的镜像。 对于 Windows 用户,你可以直接下载适用于 Windows 的安装程序 OllamaSetup.exe。步骤 2:安装 Ollama下载完成后,双击 OllamaSetup.exe 安装程序。
对于 Windows 用户,你可以直接下载适用于 Windows 的安装程序 OllamaSetup.exe。步骤 2:安装 Ollama下载完成后,双击 OllamaSetup.exe 安装程序。 遵循安装向导的指示进行安装。步骤 3:启动 Ollama安装完成后,可以通过“开始”菜单中的 Ollama 图标启动 Ollama。运行后,Ollama 会在任务栏托盘中驻留一个图标。
遵循安装向导的指示进行安装。步骤 3:启动 Ollama安装完成后,可以通过“开始”菜单中的 Ollama 图标启动 Ollama。运行后,Ollama 会在任务栏托盘中驻留一个图标。 步骤 4:获取模型右键点击任务栏图标,选择“View log”打开命令行窗口。执行命令来运行 Ollama,并从模型库中获取开源 AI 模型。Ollama 提供了一系列命令,用于管理、部署和运行大型语言模型。以下是一些常用的 Ollama 命令: 查看版本:ollama -v 查看已安装的模型:ollama list 删除指定模型:ollama rm [modelname] 运行模型:ollama run [modelname] 拉取模型:ollama pull [modelname] 推送模型到仓库:ollama push [modelname] 复制模型:ollama cp [srcmodel] [destmodel] 创建模型:ollama create [modelname] -f [Modelfile] 查看模型信息:ollama show [modelname] 启动 Ollama 服务:ollama serve 构建和运行本地版本:ollama build 后跟具体的构建命令步骤 5:运行模型使用命令行工具来运行特定的模型。例如,运行 Llama 3 模型,可以使用命令 ollama run llama3。如果下载过会直接运行对话方式,否则会进入下载。这里模型可以在官网中的Model下找你要的模型
步骤 4:获取模型右键点击任务栏图标,选择“View log”打开命令行窗口。执行命令来运行 Ollama,并从模型库中获取开源 AI 模型。Ollama 提供了一系列命令,用于管理、部署和运行大型语言模型。以下是一些常用的 Ollama 命令: 查看版本:ollama -v 查看已安装的模型:ollama list 删除指定模型:ollama rm [modelname] 运行模型:ollama run [modelname] 拉取模型:ollama pull [modelname] 推送模型到仓库:ollama push [modelname] 复制模型:ollama cp [srcmodel] [destmodel] 创建模型:ollama create [modelname] -f [Modelfile] 查看模型信息:ollama show [modelname] 启动 Ollama 服务:ollama serve 构建和运行本地版本:ollama build 后跟具体的构建命令步骤 5:运行模型使用命令行工具来运行特定的模型。例如,运行 Llama 3 模型,可以使用命令 ollama run llama3。如果下载过会直接运行对话方式,否则会进入下载。这里模型可以在官网中的Model下找你要的模型 点击每个模型,有具体的说明
点击每个模型,有具体的说明 ollama run llama3
ollama run llama3直接使用 run 命令 + 模型名字就可以运行模型。如果之前没有下载过,那么会自动下载。下载完毕之后可以在终端中直接进行对话 llama3模型了。

这里下载比较慢,我这边平均3M每秒。
步骤 5:试一下安装的模型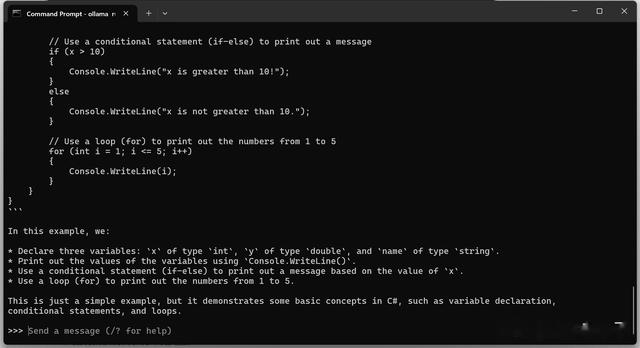
我们可以再下载一个千问模型,中文支持会更好一些
 ollama run qwen:7b模型选择
ollama run qwen:7b模型选择下载的模型并不是越大越好,选择模型时需要考虑以下几个因素:
任务需求:不同的任务可能需要不同大小和类型的模型。例如,一些任务可能需要特定领域的小型模型,而其他任务可能需要大型的通用模型来提供更广泛的知识。资源限制:大型模型需要更多的计算资源和内存。如果用户的硬件资源有限,运行大型模型可能会导致性能问题,甚至无法运行。响应时间:大型模型通常需要更多的时间来生成响应,这可能影响需要快速反馈的应用场景。能耗:大型模型在运行时会消耗更多的电力,这可能对移动设备或需要考虑能效的场景不利。成本:如果在使用云服务或高性能计算资源时,大型模型会增加计算成本。运行7B参数的模型至少需要8GB的RAM,运行13B参数的模型需要16GB RAM,而运行33B参数的模型则需要32GB RAM。
步骤 6:修改下载模型的路径默认Models路径在
C:\Users\用户名\.ollama如果需要使用不同的目录,则需设置环境变量OLLAMA_MODELS, 把它设置为所选目录。
在 Windows 上设置环境变量 在 Windows 上,Ollama 会继承你的用户和系统环境变量。
首先通过点击任务栏中的 Ollama 图标来退出 Ollama。从控制面板编辑系统环境变量。 为你的用户账户编辑或创建新的变量,例如 OLLAMA_HOST、OLLAMA_MODELS 等。
为你的用户账户编辑或创建新的变量,例如 OLLAMA_HOST、OLLAMA_MODELS 等。 点击 OK/应用 来保存设置。
点击 OK/应用 来保存设置。 在新的终端窗口运行 ollama。
在新的终端窗口运行 ollama。详细的FAQ可以查看以下地址
https://github.com/ollama/ollama/blob/main/docs/faq.md
步骤 7:自定义模型(可选)如果需要自定义模型,可以创建一个 Modelfile 来定义模型参数和系统消息。使用 ollama create 命令根据 Modelfile 创建新模型。使用 ollama run 命令运行自定义模型。步骤 8:使用 REST API(可选)Ollama 提供了 REST API,可以通过 HTTP 请求与 Ollama 交互,实现更高级的功能和集成。general api调用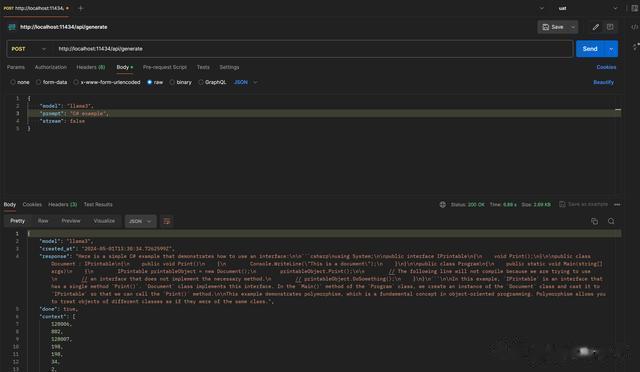 chat api调用
chat api调用 curl -X POST -H "Content-Type: application/json" -d "{ \"model\": \"llama3\", \"prompt\": \"Why is the sky blue?\" }" http://localhost:11434/api/generate
curl -X POST -H "Content-Type: application/json" -d "{ \"model\": \"llama3\", \"prompt\": \"Why is the sky blue?\" }" http://localhost:11434/api/generate 步骤 9:构建和运行本地版本(高级用户,可选)对于想要深入研究或自定义 Ollama 功能的开发者,可以从源代码开始构建。使用命令安装必要的依赖,如 cmake 和 go。构建二进制文件,并运行本地构建的 Ollama。
步骤 9:构建和运行本地版本(高级用户,可选)对于想要深入研究或自定义 Ollama 功能的开发者,可以从源代码开始构建。使用命令安装必要的依赖,如 cmake 和 go。构建二进制文件,并运行本地构建的 Ollama。对于想要从源代码构建 Ollama 的开发者,可以访问 Ollama 的 GitHub 仓库来获取源代码。源代码的下载地址是:
https://github.com/ollama/ollama
从这里,你可以克隆仓库或者下载源代码的压缩包。使用 Git 克隆仓库的命令如下:
git clone https://github.com/ollama/ollama.git
这样,你就可以获得 Ollama 的最新源代码,并根据自己的需要进行构建和定制。
注意事项:确保你的 Windows 系统满足运行大型语言模型的硬件要求,如足够的 RAM。Windows 版本可能处于预览阶段,可能不如其他平台稳定,但提供了大部分核心功能。在使用 Docker 部署时,需要确保 Docker 已经安装在你的 Windows 系统上。