AI大模型风口正盛,繁荣之下却暗藏隐忧。
高质量文本数据是大模型赖以学习的核心原料,在很大程度上影响着大模型的能力水平,因此,训练数据匮乏始终是厂商心中挥之不去的阴影。
近日,《经济学人》杂志发布了一篇题为《AI公司很快将耗尽大部分互联网数据》(AI firms will soon exhaust most of the internet’s data)的文章,随即引发舆论的广泛关注。文章援引研究公司Epoch AI的预测,指出互联网上可用的高质量文本数据或将在2028年耗尽,这一现象被称为“数据墙”,可能成为减缓人工智能进展的最大问题。

《经济学人》的报道文章截图
01
训练数据有多重要?
无独有偶,《自然》7月24日发表的一篇论文指出,用人工智能(AI)生成的数据集训练未来几代机器学习模型可能会污染它们的输出,这个概念被称为“模型崩溃”(model collapse)。该研究显示,原始内容会在数代内变成不相干的胡言乱语,显示出使用可靠数据训练AI模型的重要性。
总而言之,言而总之,AI训练中的AI有越练越傻的迹象。
想要明确这一预测,对AI大模型的发展意味着什么,首先需要了解大模型训练和推理的模式。
AI大模型的运作原理可以类比人类的学习过程,刚出生的婴儿虽然不会说话,但已开始感受周围环境,并接收环境中的人类语言输入,包括但不限于大人的交谈、音乐旋律、视频声音等等,这正像是AI大模型的初始训练,即利用海量数据的输入学习人类自然语言的规律和模式。
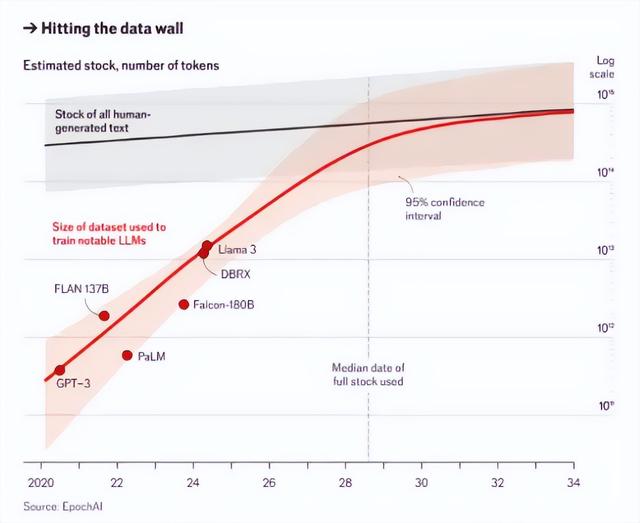
Epoch AI的数据预测
随着输入的语料不断丰富,对周围环境的了解逐渐加深,婴儿开始模仿大人发出自己的声音,用简单的词汇和短句尝试自我表达,这一过程就像是AI大模型被投喂海量数据后,逐渐构建出具有理解和预测能力的模型,不过这时的理解和预测能力还比较初级。
接下来,婴儿在成长过程中不断加深对人类语言的学习,更能理解输入内容的意义,也会随着理解能力的提升优化自己的输出,使表达更加流畅精准,并且开始形成自我意识,与外界展开自主对话。这一过程就像是AI大模型在初级版本上的更新迭代,开始具备一定的推理能力和分析能力。而目前大模型在基础问答、语音识别等领域的应用,正像是婴儿在成长过程中尝试解决一些简单问题。
高质量文本数据濒临耗尽,意味着婴儿在成长过程中向外学习的机会骤缩,那么解决问题的能力就会停滞不前。大模型的迭代也是一样的道理,输入的内容有限,模型的推理和分析能力得不到有效优化,在场景中的应用效果也就难以提高。
诚然,调整大模型的参数也能获得一定优化效果,但在底层技术尚未拉开差距的阶段,训练语料始终是影响大模型性能和质量的关键要素,甚至直接关系到模型准确度的呈现。更何况,比起投喂高质量文本数据的方法,增加模型参数需要耗费极高成本,投入产出比过低。
中信智库专家委员会主任、中信建投证券研究所所长武超曾在2023世界人工智能大会上指出,“未来一个模型的好坏,20%由算法决定,80%由数据质量决定。接下来高质量的数据将是提升模型性能的关键。”
02
训练数据之渴
为何可供训练的高质量文本数据如此匮乏?
回答这个问题之前,首先应该对“训练大模型需要多少数据才够”这一问题有一个具象化了解。通常,这取决于大模型的规模,还有所承担的项目需求,尤其是项目的复杂性、预算、质量要求,以及特定项目的标注和注释需求等等。
新锐科创企业Shaip指出,从经验层面来讲,要开发一个高效的 AI 模型,所需的训练数据集的数量应该是每个模型参数的十倍,也称为自由度。“10”倍规则旨在限制可变性并增加数据的多样性。而如果想要开发高质量模型,创建一个足以与人类相媲美的深度学习算法,每个类别需要有 5000 个标记图像,如果要开发异常复杂的模型,则至少需要10万个带标签的项目。

海量数据需求只是一方面,另一方面在于各行业数据的开发程度极为有限。目前,我国大量专业领域的数据信息都处于相对封闭的状态,接触一些重要资料需要内部权限,即便公开也无法带离特定场所查阅,只能在数据库和图书馆等地点翻看,更遑论进行相关数据传输。
此外,除了领域盲区,可接触到的高质量行业数据分布也较为零散,缺乏集合性,想要作为训练数据使用,需要前期投入大量精力进行数据清洗和数据整合。
通用的行业资料尚且如此,一些落地垂直场景的大模型,获取特定领域的专业数据则更为困难。IBM 首席执行官 Arvind Krishna曾指出,几乎 AI 项目中 80% 的工作是关于收集、清理和准备数据。他还认为,企业放弃他们的人工智能业务是因为他们无法跟上收集有价值的培训数据所需的成本、工作和时间。
专业数据的开发有限,另一边,个人用户的数据安全也一直身处争议的旋涡。去年3月,微软向Windows10用户大量推送更新消息,并伴随“强制弹窗”,页面提示“你的数据将在你所在的国家或地区之外进行处理”,且没有“取消”选项,只能点击“下一步”这一个按钮,否则无法进入系统桌面。此举引发大量用户对隐私数据泄露的担忧。
随后,微软在回应中表示用户更新使用Windows11后,会将数据传出中国,理由是微软的软件注册中心在美国,ChatGPT整合到bing搜索和Edge浏览器中也需要美国数据中心的支持,所以数据可能传送到中国之外。

微软针对用户泄露隐私质疑的回应声明
大众对个人隐私数据的保守,与对AI大模型场景应用的需求相斥,连带着供给端的厂商们也在利用用户数据训练优化AI服务,以及保护隐私确保用户留存之间反复战略摇摆。由此牵涉出的版权问题,更是将人工智能的伦理争议推上风口浪尖。
早些时候,OpenAI曾因AI语音项目中的声音涉嫌侵权,收到好莱坞明星斯嘉丽·约翰逊发出的律师函,OpenAI随即暂停使用该款语音。近日,吸取教训的Meta豪掷数百万美元与好莱坞影星洽谈AI语音项目的授权,试图挽救AI行业饱受诟病的版权问题。据财联社报道,由于双方无法就演员声音的使用条款达成一致,Meta和一些演员代表之间的谈判已经历多次中断和重启,演员代表正在寻求更严格的限制,以维护自身权益。

OpenAI宣布暂停使用“Sky”的声音
03
倒计时中寻找未来
面对训练原料即将告罄的处境,不少业内人士纷纷找寻替代性解法,使用AI合成数据是目前讨论热度最大的选择。
阿里研究院指出,合成数据解决了部分类型的真实世界数据难以观测的问题,拓展了训练数据的多样性,并且可与真实世界的配合使用提高模型的安全性和可靠性。更重要的是,合成数据可以替代个人特征数据,有助于用户隐私保护,解决数据获取合规性的问题。
对看重效率、商业化前景与风险的厂商们而言,这的确是替代方案中还算不错的选择。目前,我国已通过谋划建设数据训练基地、出台相关扶持政策等举措,开始鼓励和引导合成数据产业的发展,尽可能帮助高质量数据的增量扩容。

有观点认为,AI合成数据有其使用价值,但前提是需要对数据进行严格过滤,或是使用多样化数据源,这不仅对厂商们的数据清洗能力提出了更高要求,也对数据获取渠道展现更大的“胃口”。这意味着,在AI寻找未来的过程中,势必还将面临更严峻的版权问题和伦理争议。
不久前“9.11和9.9哪个大”的数学题难倒一众AI大模型的新闻还历历在目,不稳定的数学能力其实是目前大模型行业的一个缩影。在最理想的产业图景中,AI产出与人类创作本应相得益彰,但数据危机的警钟已响,直面新旧业态、新旧观念的摩擦,成为人们支持新技术发展不得不做出的选择。
