谷歌近期发布了一款名为 Learn About 的实验性 AI 工具,它与我们熟知的 Gemini、ChatGPT 等聊天机器人有着显著的不同,它更针对的是场景的应用,也就是偏向于教育领域的工具。
这款工具,是基于谷歌今年春季推出的 LearnLM AI 模型构建,旨在「基于教育研究,根据人们的学习方式量身定制」,所以,我们能看到的是,Learn About 在提供的答案内容丰富性更高,还融入了更多的视觉和交互元素,并以教育性的格式与视角呈现。
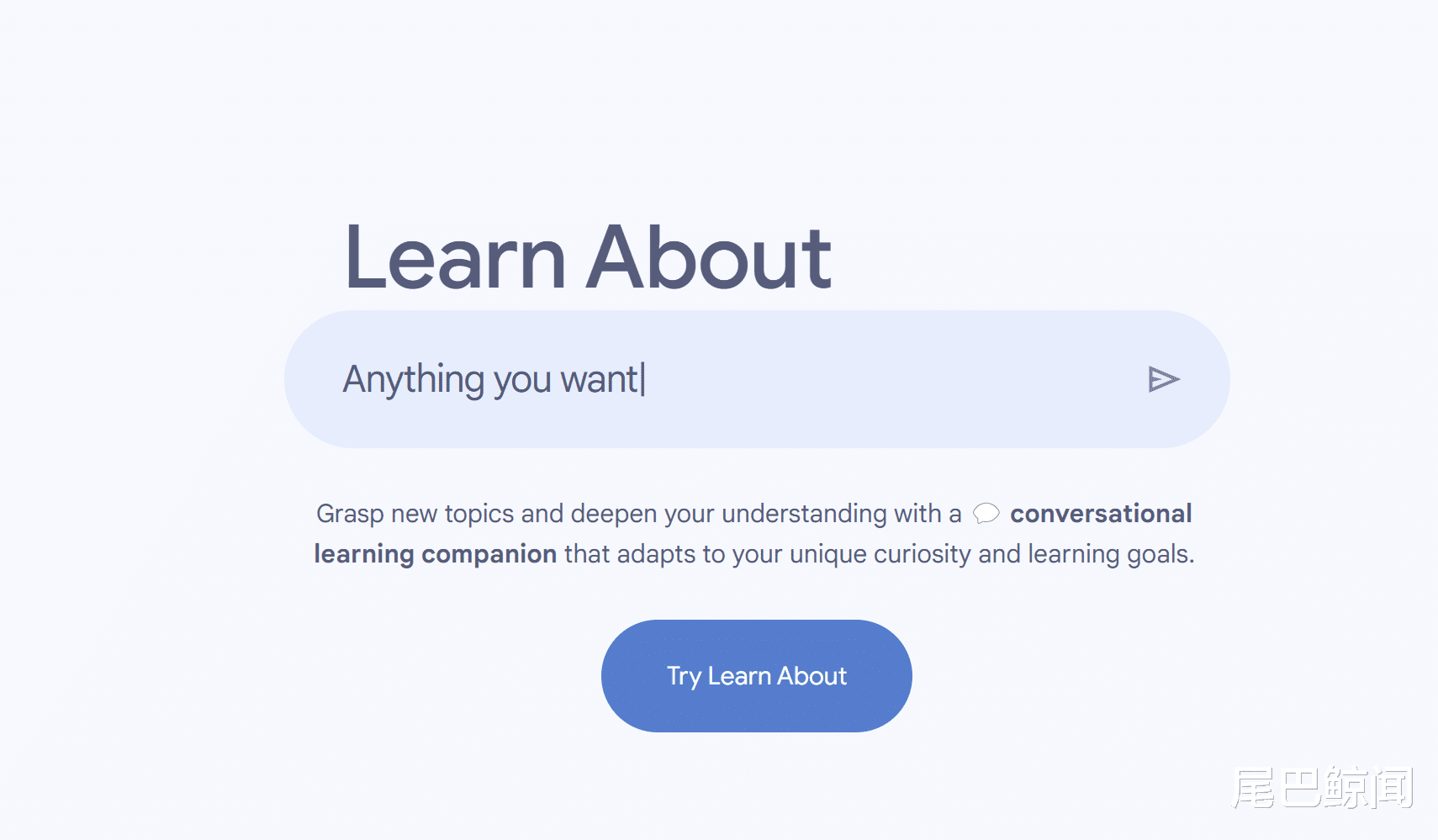
比如:在回答用户的问题时,Learn About 会先创建类似教科书的框架,为用户提供额外的上下文信息,像是「为什么它很重要」之类的说明,还会帮助用户「构建词汇」的单词定义框。


同时,它的侧边栏还会列出与主题相关的额外内容,供用户继续探索和学习。
阿里通义千问开源 Qwen2.5-Coder 全系列模型阿里通义千问宣布开源 Qwen2.5-Coder 全系列模型,官方宣称其代码能力已与 GPT-4 相当,其中,旗舰模型 Qwen2.5-Coder-32B-Instruct 被誉为目前 SOTA(State Of The Art,即最先进技术)的开源代码模型。
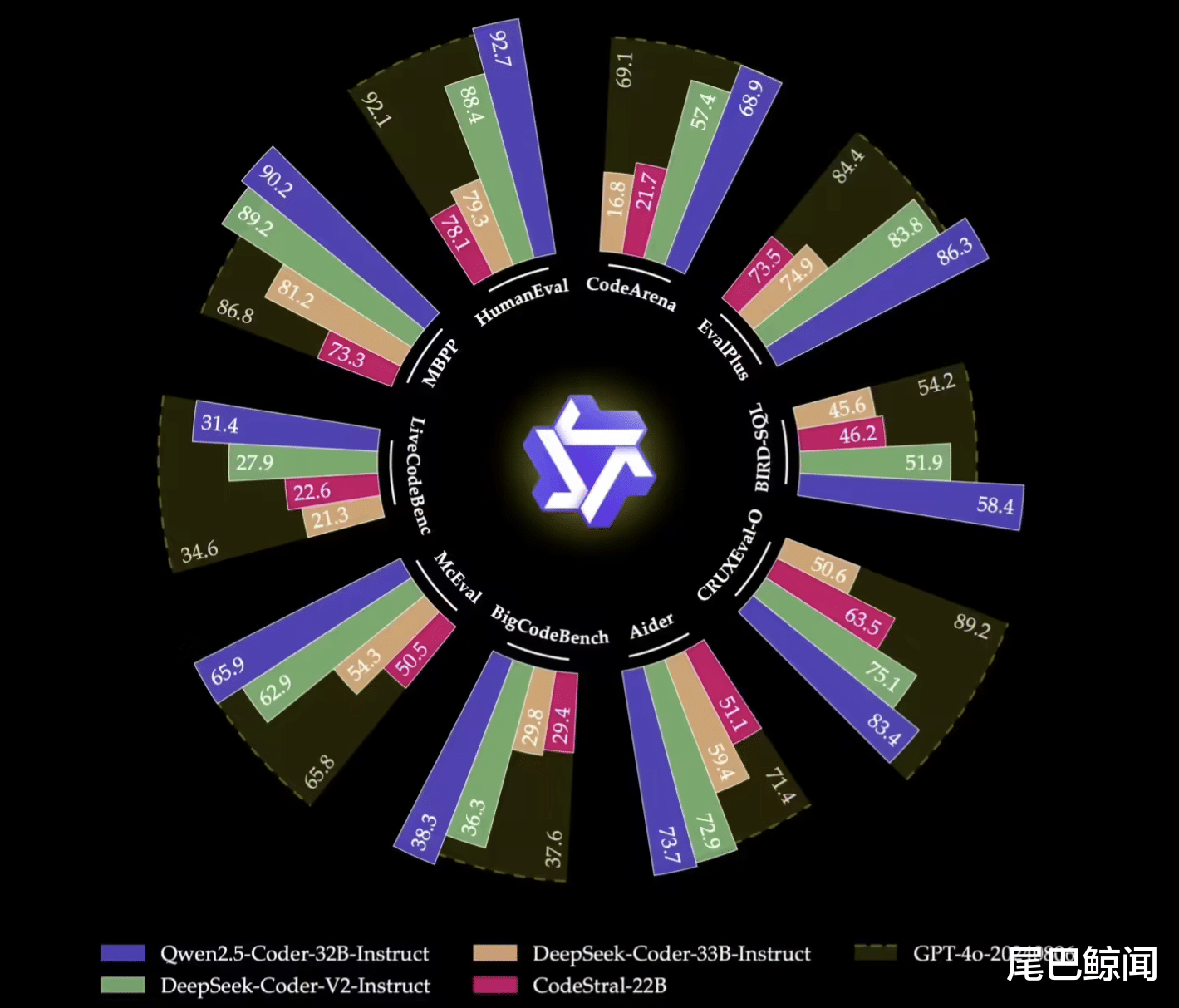
作为本次开源的亮点,Qwen2.5-Coder-32B-Instruct 在多个流行的代码生成基准测试(如 EvalPlus、LiveCodeBench、BigCodeBench)中都取得了开源模型中的最佳成绩。
而结果确实是可以比拟 GPT-4。
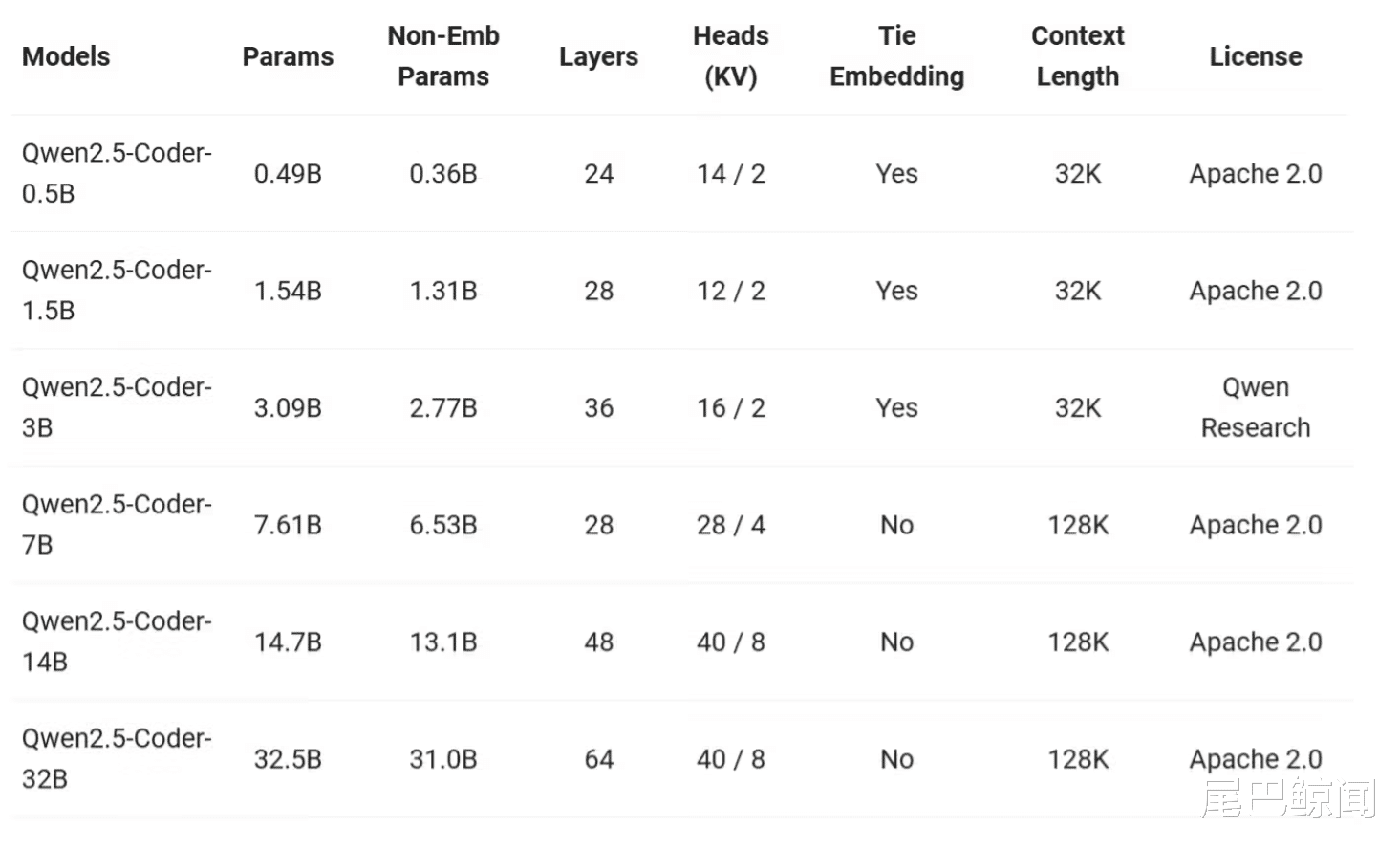
此前,阿里通义千问已经开源了 1.5B 和 7B 两个尺寸的模型。本次开源则是带来了 0.5B、3B、14B 和 32B 四个新尺寸,覆盖了主流的六个模型尺寸。
Qwen2.5-Coder 的 0.5B、1.5B、7B、14B 和 32B 模型均采用了 Apache 2.0 许可证,而 3B 模型则使用了 Research Only 许可。
基于Qwen2.5-Coder,AI编程性能和效率均实现大幅提升,入门的编程人员也可轻松生成网站、数据图表、简历、游戏等各类应用。
据了解,全球基于 Qwen 系列的二次开发的衍生模型数量,在 9 月底时就已经突破到 7.43 万,超越 Llama 系列衍生模型的 7.28 万,通义千问或在某一程度上已经成为全球最大的生成式语言模型族群。
