是否对 LLMs(大型语言模型)感到好奇并想要了解更多?立即查看完整指南!
大型语言模型(LLMs)简介谁没听说过 ChatGPT?即使你没有亲自使用过,也一定从朋友或熟人那里听说过。ChatGPT 以自然对话能力和执行任务的强大功能,成为人工智能领域的一项重大突破。在深入探讨之前,我们先来回答一个关键问题:
什么是 LLMs?大型语言模型(LLMs) 是人工智能的一项重要进步,能够预测和生成类似人类的文本。之所以称为“大型”,是因为它们的体积通常达到数 GB 级别,并且包含数十亿个参数,这些参数帮助它们理解和生成语言。
LLMs 通过学习语言的结构、语法和含义,可以执行诸如回答问题、摘要内容,甚至撰写创意故事等任务。它们在大量文本数据(如书籍、网站等)上进行训练,以学习各种语言模式和上下文。这一过程需要强大的计算能力,因此 LLMs 的开发成本极高。
在本文中,我将详细介绍 LLMs 的工作原理,并指导你如何轻松入门。
LLMs 如何工作?LLMs 主要依靠深度学习技术,特别是神经网络来处理和理解语言。我们可以将其工作原理拆解为以下几个步骤:
1. Transformer 架构目前最流行的 LLM,如 OpenAI 的 GPT(生成式预训练变换器)系列,都采用 Transformer 架构 来处理大规模数据集。Transformer 通过并行处理数据,并利用注意力机制捕捉单词之间的依赖关系。
Transformer 的核心组成部分包括:
自注意力机制(Self-Attention Mechanism)该机制允许模型在处理输入时关注与当前单词相关的内容。示例:在句子 “The girl found her book on the table.” 中,模型能够计算出 “her” 与 “girl” 之间的关系比 “her” 和 “book” 更强,从而正确理解句子含义。位置编码(Positional Encoding)由于 Transformer 采用并行处理,它需要额外的信息来理解单词在句子中的顺序。示例:在句子 “He read the book before going to bed.” 中,位置编码帮助模型识别 “before” 这个词,确保模型理解事件的时间顺序。前馈神经网络(Feedforward Neural Networks)在注意力机制之后,数据会通过全连接层进行转换,以提取输入数据的模式。示例:在句子 “The teacher explained the lesson clearly.” 中,神经网络可以识别 “teacher” 这个词与 “explained” 之间的关系,并理解 “lesson” 是被解释的对象。下图对Transformer的工作原理进行了简化说明
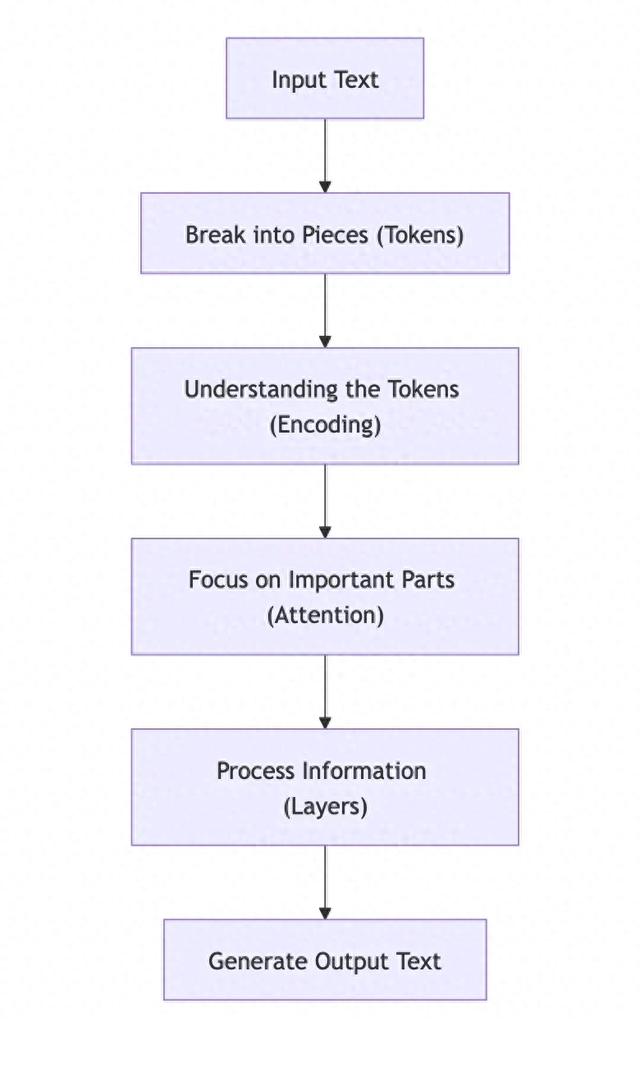
这些组件使 Transformer 能够理解单词、短语及其上下文,从而生成高度连贯的文本。
2. LLMs 的训练过程LLMs 的训练分为两个阶段:预训练(Pre-training) 和 微调(Fine-tuning)。
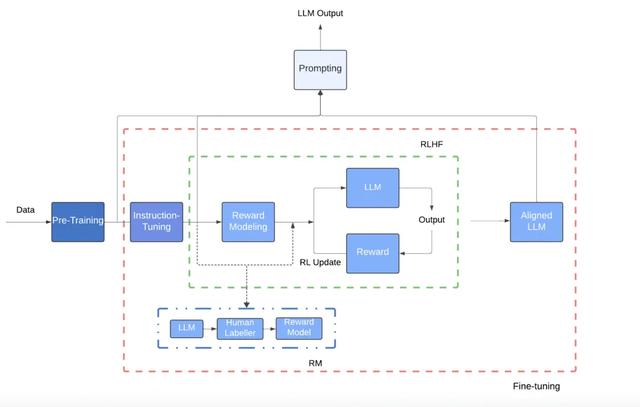 A. 预训练(Pre-training)
A. 预训练(Pre-training)在此阶段,模型会在通用文本数据上进行训练,以学习语言模式和结构。
分词(Tokenization)预训练首先将文本拆分为更小的单元(Token),这些可以是单词、子单词,甚至是单个字符。示例:句子 “I want to swim.” 可能会被拆分为 [“I”, “want”, “to”, “swim”]。掩码语言模型(Masked Language Modeling, MLM)在训练过程中,部分 Token 会被隐藏,模型需要根据上下文进行预测,以学习语言结构和含义。示例:对于句子 “The ___ is blue.”,模型可能会预测 “sky” 作为最佳填充词,从而学会推断缺失信息。下一个 Token 预测(Next-Token Prediction)模型学习如何预测句子中的下一个 Token,以便生成流畅的文本。示例:输入 “The sky is”,模型可能预测 “blue” 作为最可能的下一个单词。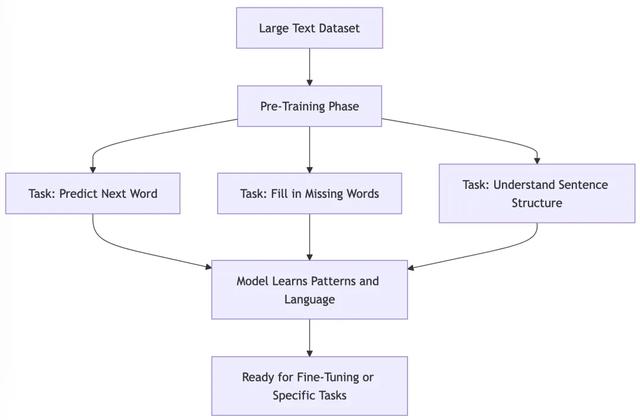
在这一阶段,模型对语言有了广泛的理解,但还缺乏特定任务的知识。
B. 微调(Fine-tuning)在预训练之后,模型虽然理解语言,但无法执行特定任务,因此需要进行微调,以提高准确性并使其符合人类的期望。
示例:
针对健身数据进行微调的模型可以提供个性化的健身计划。针对客户支持数据训练的模型可以处理帮助中心的查询。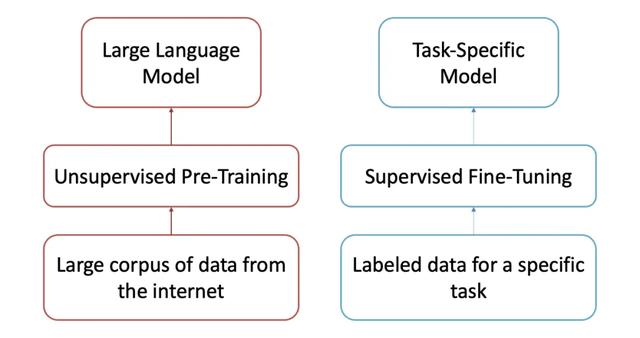 C. 人类反馈强化学习(Reinforcement Learning with Human Feedback, RLHF)
C. 人类反馈强化学习(Reinforcement Learning with Human Feedback, RLHF)微调后的模型会进一步通过 RLHF 进行优化,以生成更符合人类需求的回复。
奖励建模(Reward Modeling):训练一个奖励模型,以人类标注的方式评估 LLM 的回答质量,如有用性、诚实性等。强化学习(Reinforcement Learning):利用奖励模型优化 LLM,使其优先生成更符合人类偏好的回答。3. 提示工程(Prompting)在 LLMs 中,提示(Prompting) 指的是用户向模型输入的文本,用于引导其生成所需的输出。不同的提示方式会影响模型的回答质量。
零样本提示(Zero-Shot Prompting)直接让模型执行任务,无需示例。示例:"Explain how photosynthesis works."少样本提示(Few-Shot Prompting)提供几个示例,帮助模型理解任务。示例:"Translate English to French: 'Hello' -> 'Bonjour'. 'Goodbye' -> 'Au revoir'. 'Please' -> ?"指令提示(Instruction Prompting)给予明确指令,让模型执行特定任务。示例:"Write a letter to a friend inviting them to your birthday party."LLMs 的优势与应用LLMs 具备强大的自然语言理解、逻辑推理、多任务处理能力,并可持续学习和适应。其应用领域包括:
内容创作(文章、博客、社交媒体帖子)虚拟助手(如 Siri、Alexa)搜索引擎(提升查询理解能力)数据分析(帮助决策)代码开发(编写代码、测试用例、修复 Bug)科学研究(总结研究论文、生成假设)LLMs 的局限性尽管 LLMs 功能强大,但仍存在一些问题:
幻觉与错误信息(可能生成看似合理但实际错误的内容)上下文理解局限(长文本中的上下文跟踪能力有限)隐私问题(可能无意间泄露敏感信息)计算成本高(训练和部署需要大量算力)数据偏见(可能反映训练数据中的刻板印象)总结本文详细介绍了 LLMs 的概念、工作原理、应用以及挑战。到 2025 年,LLMs 将更加深入日常生活,并不断改进其局限性。如果你对 LLMs 感兴趣,现在正是最佳学习时机!

