
文|大核有料
编辑|大核有料
基于视觉的同步定位与建图技术已广泛应用于机器人导航、场景构建和虚拟现实(virtualreality,VR)技术等领域。
随着应用环境的复杂化,人类对移动机器人的自主性提出更高要求,并希望移动机器人能够在初始未知的复杂环境中执行任务,例如能够与人类、车辆及其环境进行安全有效地交互。

因此如何实现机器人自主移动成为了亟待解决的问题。在实现自主化的过程中,需要解决三个问题:“我在哪”,“我周围的环境是什么样的”和“我该怎么去想去的地方”,这三个问题分别对应着移动机器人的建图,定位和路径规划问题。
同步定位与建图(simultaneouslocalizationandmapping,SLAM)技术能够同时解决移动机器人的建图与定位需求,成为当前移动机器人自主导航的主流解决方案。
本文将先介绍视觉SLAM的基本框架以及数学表述,之后从传统视觉SLAM方法和基于深度学习的视觉SLAM两个方面进行分类介绍,最后对视觉SLAM研究热点和未来的发展趋势进行了讨论,为该技术在移动机器人自主导航中的应用提供参考。
«——【·视觉SLAM基本原理·】——»
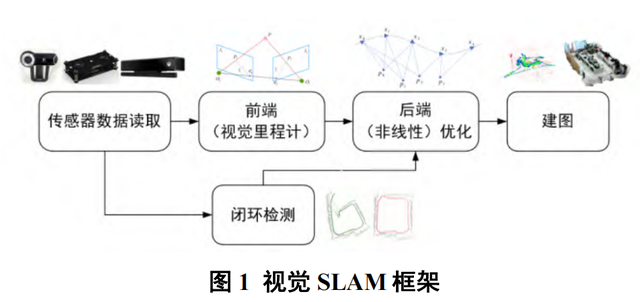
视觉SLAM框架:通常来说,视觉SLAM框架需要包括以下几个部分:传感器信息读取,前端,后端,地图构建以及闭环检测。

在视觉SLAM中,传感器信息读取即为相机图像的读取和预处理,在多传感器融合的SLAM当中,还会涉及惯性测量单元,激光雷达,轮式编码器的数据的读取,以及不同传感器之间的数据同步。
视觉SLAM的前端,也称为视觉里程计(visualodometry,VO),负责处理前一步骤的输入图像,在不同时间估计相机的位置和姿态,它还负责确定相邻图像之间的相机运动,以获取局部地图信息。

后端也称为非线性优化,能够接收由视觉里程计返回的不同时刻下的相机位姿参数,之后对其进行优化,此外它还接收闭环检测信息并执行全局优化,以获得全局一致的轨迹和地图。
闭环检测线程用于确定移动机器人是否经过了先前访问过的位置,如果确定,则建立一个闭环,并将信息传递给后端进行进一步处理。
最终,建图线程基于前面阶段估计的相机轨迹,以及不同时刻的局部地图,生成完整的全局地图。视觉SLAM的框架如图1所示。
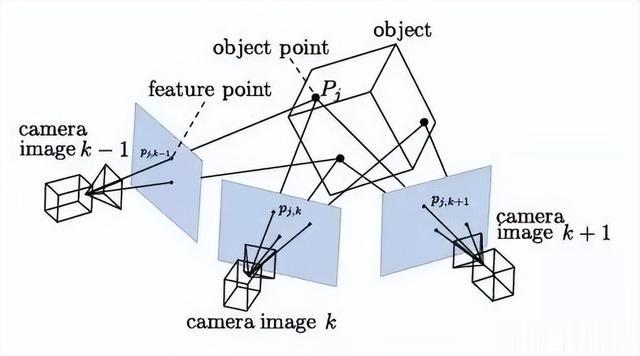
视觉SLAM数学表述:在移动机器人携带相机在未知环境中运动时,由于相机是在某些时刻采集数据的,记录机器人每一时刻的位置为x1,x2,…,xk,这些位置构成了机器人的运动轨迹。
在SLAM中假设地图是由多个路标点组成的,在机器人移动过程中会观测到部分路标点,假设路标点由y1,y2,…,yj来表示,那么SLAM中的运动方程可表示为:
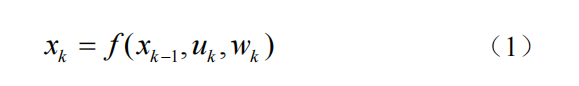
其中uk是相机数据的输入,wk是运动过程中加入的噪声。这里通过指代一个抽象的一般函数f来描述这个过程,使得整个函数可以代表单目,双目,或是深度相机输入,成为一个通用的方程。
与运动方程相对应,SLAM的表述还需要一个观测方程:
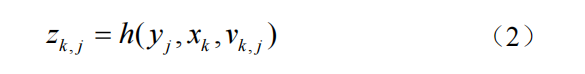
与公式(1)中的f相同,假设一个抽象的函数h来描述这个关系。此方程中表示移动机器人在xk位置上看到某路标点yj时,产生了观测数据zk,j,其中vk,j是观测过程中的噪声。
根据以上运动方程和观测方程,在已知机器人相机数据的输入u,以及观测数据z时,可以求解x和y,其中x对应着定位问题,y对应着建图问题。由此SLAM建模成为状态估计问题。

«——【·传统视觉SLAM方法·】——»
纯视觉SLAM:纯视觉SLAM通过连续的相机帧跟踪关键点的移动,从而推测相机的位置。可分为基于特征点法的视觉SLAM、基于直接法的视觉SLAM和基于深度信息的视觉SLAM。
基于特征点法的视觉:SLAM基于特征点法的视觉SLAM使用相机采集的图像数据,从中提取出特征点,通过这些特征点来实现相机帧与帧之间的位姿估计。
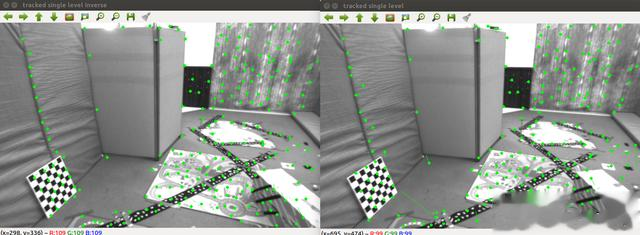
在这种方法中,相机会在运动中不断地捕捉到场景中的特征点,例如角点、边缘、纹理等,这些特征点会被用来恢复相机的位姿和构建场景的地图。
单目SLAM方法,称为MonoSLAM,它是第一个能够实时运行的单目视觉SLAM系统,它提取图像中特征点,并通过特征匹配来确定相机的位姿,以相机的当前状态和所有路标点为状态量,更新其均值和协方差,并使用扩展卡尔曼滤波器来进行位姿和地图的更新。
PTAM算法是一种基于单目相机的SLAM方法,首次通过并行跟踪和地图构建两个线程实现SLAM系统的实时性,也是第一个使用非线性优化,而不是使用传统的滤波器作为后端的SLAM方案。
在跟踪线程中,对图像提取FAST(featuresfromacceleratedsegmenttest)角点,使用相机的运动预测来跟踪特征点,并使用基于重投影误差的优化来提高跟踪精度。
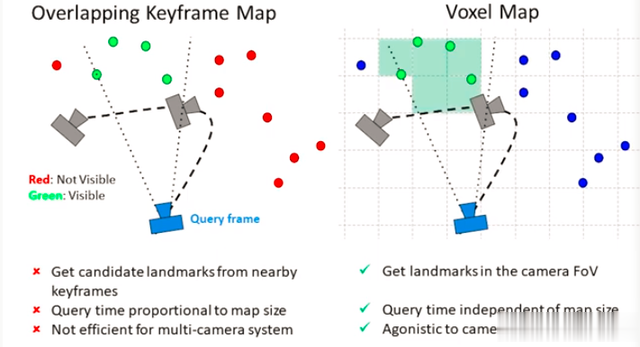
在地图构建线程中,PTAM使用新的特征点来更新地图,并使用基于均值漂移的聚类算法来对特征点进行分类和合并,但是PTAM没有闭环检测,远距离会出现尺度漂移,因此只能局限于小的场景使用。
ORB-SLAM算法相较于PTAM,还增加了闭环检测线程。ORB-SLAM利用ORB(orientedfastandrotatedbrief)特征点及其描述子来检测和跟踪图像中的特征点,并利用这些特征点进行相机姿态和地图点的估计,得益于ORB-SLAM的闭环检测,算法的累计误差得以有效解决。

ORB-SLAM的基础上提出的ORB-SLAM2,增加了双目和深度(redgreenbluedepth,RGB-D)相机的接口,可以更加灵活地运用于不同的场景。
在前者基础上增加了全局束调整(bundleadjustment,BA)线程,此线程可以通过最小化重投影误差来提高定位的精度和鲁棒性。
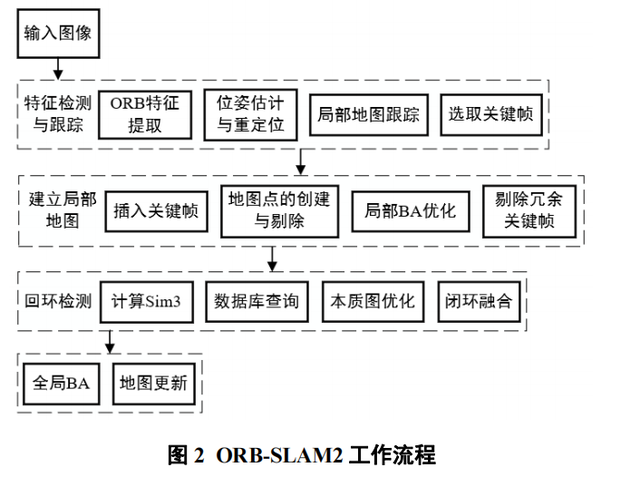
ORB-SLAM2的定位模式能够在环境没有剧烈变化的前提下,在轻量级地图中长期运行。ORB-SLAM2的工作流程如图2所示。
近几年基于特征点法的视觉SLAM主要针对前端特征结构进行改进,如2021年有学者提出使用参数化的方式来表示线特征,将地面上的线条限制在正确的解空间内,避免了冗余参数增加对地面线条的不确定性。
通过提取直线与平面特征并进行混合关联,解决相机位姿估计时的退化问题,同时,简化跟踪特征,直接依据图像像素信息估计运动的直接法得到广泛研究。
基于直接法的视觉:SLAM基于直接法的视觉SLAM使用基于光度误差的方法来进行像素匹配和位姿估计,即通过比较不同图像之间的像素值,来计算相机的位姿和场景的三维几何信息,避免了对于特征点提取和匹配的依赖,使算法更加鲁棒和精确。
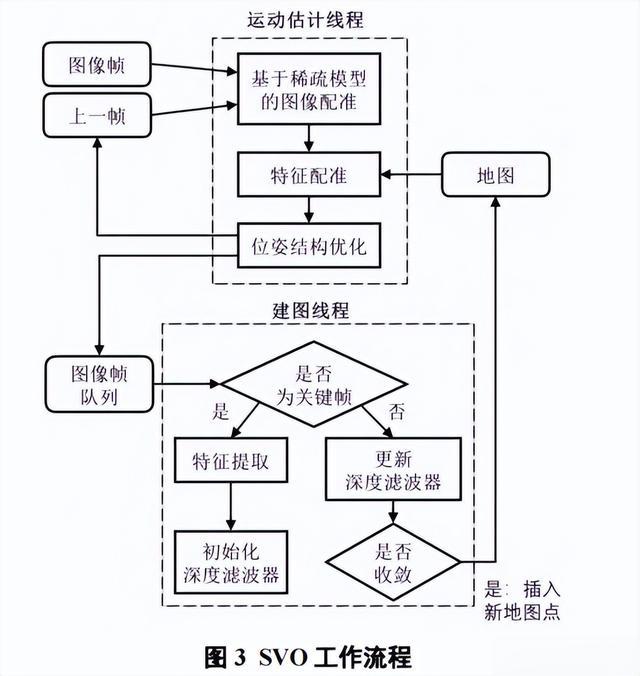
半直接单目视觉里程计(semi-directmonocularvisualodometry,SVO)算法,在实现过程中,混合使用了特征点和直接法,通过使用直接法跟踪梯度较大的图像区域,使用特征点法优化地图点和相机位姿。
SVO另一特点是实现了一种基于概率的鲁棒深度估计算法,使得系统在纹理较弱的区域也能正常运行。SVO的工作流程如图3所示。
基于深度信息的视觉SLAM:2010年微软发布Kinect相机,基于RGB-D数据的SLAM开始引起研究者的关注。
深度相机由单目彩色相机和深度相机组成,使得SLAM系统能够通过低成本硬件直接获取实时深度信息,从而降低了SLAM初始化的复杂性,并同时保证较好的准确性。
大多数基于RGB-D的系统利用迭代最近点(iterativeclosestpoint,ICP)算法定位传感器,融合深度图以获得整个地图的重建。
视觉惯性SLAM:视觉SLAM中,仅用相机虽然可以很好地完成闭环检测和定位,但是在运动过快时容易产生运动模糊,而惯性测量单元(inertialmeasurementunit,IMU)对于短时间的快速运动,能够提供一些较好的估计,不过它不能实现闭环检测,且很容易产生漂移现象。
视觉惯性SLAM通过同时使用摄像头和惯性传感器的数据,可以提高机器人在动态环境下定位和地图构建的鲁棒性。
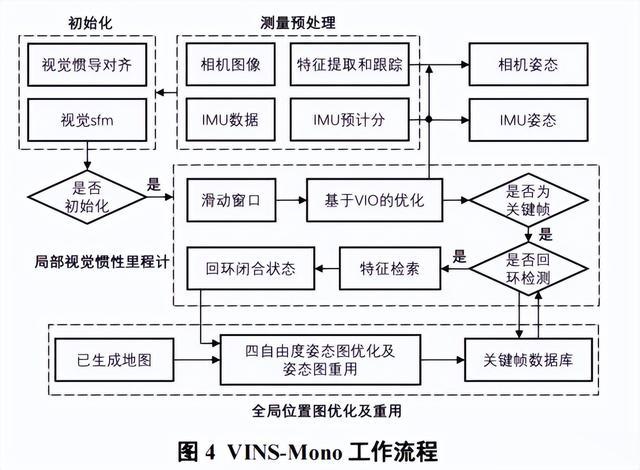
VINS-Mono是一种基于单目相机和IMU的视觉惯性里程计算法,该算法通过引入预计分算法和纯视觉信息构建运动约束方程组,从而初步估计系统的速度、相机的尺度信息以及重力向量。
VINS-Mono将相机和IMU的测量数据通过一种紧耦合的非线性优化进行同步,并通过基于特征点的方法进行图像处理。
之后VINS-Mono通过联合优化相机姿态、地图点位置和IMU姿态等变量来提高状态估计的精度和鲁棒性。VINS-Mono的工作流程如图4所示。
在VINS-Mono基础上,有学者提出了一种3D-2D线特征联系的单目SLAM,实现了更好的相机运动估计。
在VINS-Mono基础上,针对动态场景,使用基于深度神经网络(deepneuralnetwork,DNN)的物体检测方法来检测潜在的移动物体,以掩盖其上的任何特征点,获得了更好的全局准确性。
«——【·基于深度学习的视觉SLAM·】——»
深度学习在计算机视觉领域引发了革命性的变革。卷积神经网络(convolutionalneuralnetwork,CNN)的出现使图像分类、物体检测、人脸识别等任务取得了巨大成功。
研究者开始将深度学习引入视觉SLAM,特别是卷积神经网络和循环神经网络(recurrentneuralnetwork,RNN),被用来从相机传感器数据中提取特征、进行图像匹配、深度估计以及语义分割等任务。
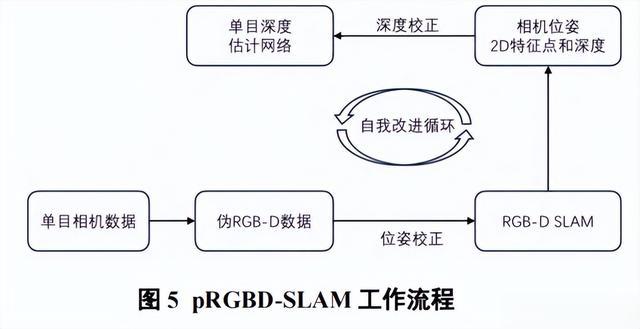
pRGBD-SLAM算法提出了一种基于窄宽基线的联合自改进框架,将单目SLAM加入卷积神经网络,用于单目深度预测中。
一方面利用CNN预测的深度来执行基于伪RGB-D特征的SLAM。另一方面,通过为改进深度预测网络而提出新的宽基线损失,将BA的三维场景结构和相机姿态注入深度网络,从而在下一次迭代中继续为更好的位姿和三维结构提供良好的初值。
pRGBDSLAM的工作流程如图5所示。
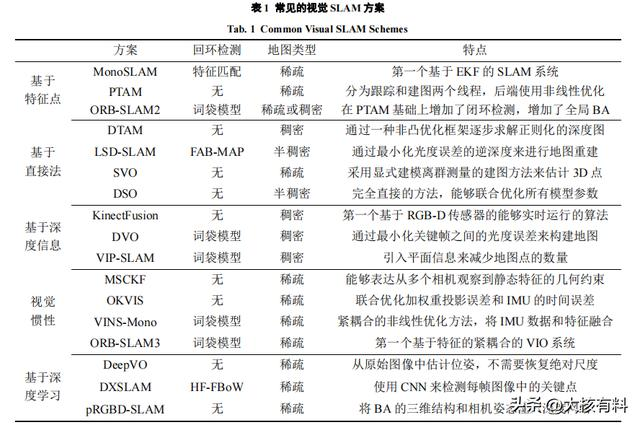
针对视觉SLAM方案,从回环检测、地图类型以及方案的特点做总结,见表1。
«——【·结语·】——»
本文首先概述了视觉SLAM技术的基本原理,包括传感器信息读取,前端,后端,地图构建以及闭环检测,之后介绍了视觉SLAM的数学表述。
从传统视觉SLAM方法和基于深度学习的视觉SLAM两个方面进行分类介绍,其中把传统视觉SLAM分为纯视觉SLAM和视觉惯性SLAM,并对每个类型中的主流算法进行介绍,针对一些算法中存在的不足,介绍了其他研究者对其后续的改进工作。
随着SLAM的应用场景不断变化,动态环境场景也日益增多。深度学习技术在计算机视觉领域取得了巨大的突破,包括物体检测、语义分割等,将深度学习与视觉SLAM结合能够帮助SLAM适应动态环境,提供更丰富的场景理解能力。
同时进行多传感器融合可以提高SLAM系统的稳定性和鲁棒性,如结合IMU、激光雷达等,视觉SLAM更多地与其他传感器进行集成,实现对实时性和准确性的平衡。
视觉SLAM系统与深度学习、多传感器融合等技术的结合,在移动机器人中,能更精确地实现自主导航。
