文/黄海峰的通信生活
2月10日-11日,巴黎AI行动峰会在法国巴黎的大皇宫举行,全球共有100多位国家领导人和科技巨头代表参加,如国务院副总理张国清、美国副总统詹姆斯·戴维·万斯、阿里董事长蔡崇信、“AI教母”李飞飞等,业界大佬齐聚于此,旨在加强国际社会在人工智能领域的合作与治理,并共同探讨人工智能的应用和其带来的重大挑战。

说到AI大模型,最近大火的DeepSeek可谓赚足了眼球。DeepSeek的流量已经超越谷歌Gemini,还登陆了App Store免费应用榜首,连DeepSeek假冒网站都已超过2000个。在上述热度下,虽然DeepSeek的创始人梁文峰受到巴黎AI峰会邀请但未出席,但DeepSeek依然成为本次峰会讨论的焦点。
我们关心的是,各国如何看待DeepSeek?DeepSeek的出现,将给全球AI格局带来怎样的影响?备受追捧的DeepSeek究竟有何不同?本文来深入探讨下。
巴黎AI峰会热议DeepSeek
首先,DeepSeek的崛起在美国引发了广泛的焦虑。美国总统特朗普将其视为对美国相关产业的警示,而副总统万斯则在演讲中强调“美国优先”,宣称美国是人工智能领域的领导者。这种立场无疑凸显了美国在全球AI格局中的保守态度。
与此同时,峰会期间,包括法国、中国、印度及欧盟在内的60个国家和国际组织共同签署了一份旨在推动包容、可持续人工智能发展的声明。然而,美国和英国却拒绝加入这一行列,英国以“不符合国家利益”为由拒绝签署,而美国则未给出直接解释。
但从客观上来讲,DeepSeek的崛起无疑为全球AI领域带来了新的活力。
例如,DeepSeek所展现出的卓越工程设计与创新能力,赢得了谷歌DeepMind CEO、诺贝尔奖得主哈萨比斯的公开赞誉。他指出,DeepSeek不仅代表了技术层面的重大突破,更在地缘政治领域产生了深远的影响。
法国总统马克龙在峰会上强调了技术中立性的重要性,呼吁各国根据技术对主权的潜在影响来评估技术,而非单纯依据其来源国。这一立场与美国的霸权心态形成了鲜明对比,进一步凸显了DeepSeek在全球AI格局中的独特地位和价值。
此外,加纳AI战略专家Rashida Musa从DeepSeek的成功中汲取了灵感,认为这为非洲国家提供了宝贵的启示,她期待非洲的年轻人能够超越商业成功的局限,更加注重创造力、激情和影响力,为非洲的AI发展注入新的活力。
从上述种种发言可以看出,自ChatGPT两年前横空出世以来,美国在AI领域的霸主地位一直备受瞩目。而DeepSeek的异军突起,这股来自东方的神秘力量,给全球AI界带来亿点点震撼。
在DeepSeek的强大实力鼓舞下,法国与欧洲诸国似乎看到了超越传统中美竞争框架的第三条道路的可能性。同时广大的全球南方国家如印度等,也意识到参与这场AI革命的紧迫性,从而在全球AI版图中占据一席之地。
DeepSeek带给世界的亿点点震撼
当今世界AI技术的发展风起云涌,率先取得进步的AI大国纷纷加码产业发展。
例如,美国政府不久前启动了星际之门项目,这是由OpenAI、甲骨文和软银联合成立合资企业Stargate Project,计划未来四年投资高达3.64万亿元用于建设AI相关基础设施。
为了应对美国的星际之门,法国私营部门未来几年对AI领域的投资总额将达到8225亿元,包括加拿大投资公司Brookfield Asset Management向法国AI项目投资的1487亿元以开发数据中心和AI基础设施,以及来自阿拉伯联合酋长国的融资可能达到3716亿元。
与此同时,中国也是全球AI版图重要力量。根据赛迪顾问报告显示,中国人工智能产业在未来10年将呈现出显著的增长趋势,从2025年到2035年,中国人工智能产业规模预计将从3985亿元增长至17295亿元,复合年增长率为15.6%。
近日爆火的DeepSeek只是中国AI大模型的代表之一。同时,月之暗面公司的Kimi k1.5模型,其性能可与OpenAI o1媲美,其公司估值达到33亿美元;阿里旗下的通义千问旗舰版模型Qwen2.5-Max,其性能据称超过DeepSeek-V3;华为通过昇腾系列芯片布局云端与边缘计算市场,结合华为云、鲲鹏服务器等生态,构建起完整的AI计算解决方案。
不仅如此,东南亚地区拥有6.7亿人口和多元文化优势,东南亚各国基于自身特色制定了独具优势的AI发展路径。例如,新加坡发布了国家人工智能战略2.0(NAIS 2.0),明确未来三到五年内提升经济和社会潜力的目标;马来西亚发布了国家AI治理与伦理指南(AIGE),并成立国家人工智能办公室;印尼制定2020~2045年人工智能国家战略蓝图。
DeepSeek为何这么厉害?
看到DeepSeek这匹从中国杭州杀出的黑马,在AI界引起的轩然大波,让中国从“追赶者”,一跃成为“规则改写者”。你是否也好奇,DeepSeek究竟有何不同?
历经一年多的迭代,DeepSeek已经发布了五个版本,分别是2023年11月发布的DeepSeek V1,2024年5月份发布的DeepSeek V2,2024年11月发布的DeepSeek R1-Lite,2024年12月发布的DeepSeek V3,以及2025年1月发布的DeepSeek R1,一夜爆火。
DeepSeek R1性能如何?据DeepSeek官方文档显示,DeepSeek R1在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。同时,通过DeepSeek-R1的输出,DeepSeek蒸馏6个小模型开源给社区,其中32B和70B模型可对标 OpenAI o1-mini。

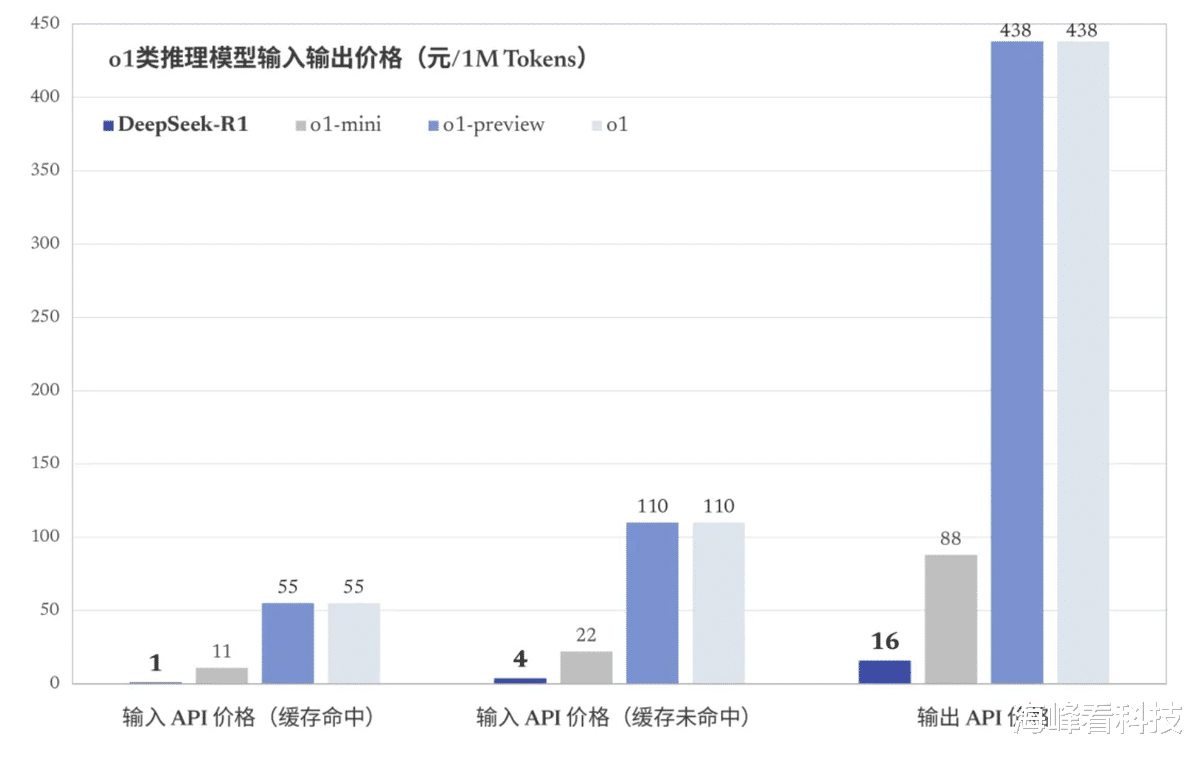
在定价方面,DeepSeek也很“吓人”。DeepSeek-R1 API服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出tokens 16元。与此相比,Open AI推出的o1的服务定价为每百万输入 tokens 55元(缓存命中)/55元(缓存未命中),每百万输出tokens 438元,相差悬殊非常大。
据天津大学熊德意教授介绍,DeepSeekV2-V3及R1在模型架构上选择稀疏MoE模型而非稠密模型,并进行和积累了大量技术创新,包括MLA、FP8训练、MoEAII-tO-AIl通信瓶颈解决、MTP等,虽然这些技术并不是所有都是原始创新,但是能够进行如此多大模型架构底层创新的实验室,在全世界可能也只有少数几个。
此外,DeepSeek所有模型架构上的创新均是围绕“降本增效”,即在基本不损害性能前提下,尽可能通过算法挖掘和提升硬件训练和解码效率。同时,美国采取芯片禁令(全球三级管控)策略维持自己的AI领导地位,DeepSeek算法绕过了美国的算力护城河。
比起DeepSeek掀翻了算力价格战的牌桌,以及其高调开源发布,让一众美国闭源大模型难以招架,DeepSeek出现更深远的意义在于,刷新了我们长久以来的认知。
那便是让美国乃至世界知道,中国在AI科技创新上不再是跟随者,而是以破局者之姿,重构中国在全球的AI话语权。甚至北京大学教授饶毅称,DeepSeek是鸦片战争以来,中国对人类最大的科技震撼。不仅如此,德意志银行更是将DeepSeek视为中国“超越世界其他国家”的“斯普特尼克时刻”。
真正的AI革命,从不会在聚光灯下诞生,而是在那些敢于重写规则的实验室里悄然生长。当塞纳河畔的AI精英们仍在争论技术主权边界,杭州西溪湿地的DeepSeek研究院里,工程师们正调试着下一代MoE架构的万亿参数模型,一个全新时代正在悄然而至。
