在大语言模型(如GPT-4)中,token 是大语言模型一个基本的处理单元。理解token的概念对于理解自然语言处理(NLP)和语言模型的工作机制非常重要。也是为什么所有大语言模型的收费都是按照 token 数量来收费的。

什么是token?
Token 是语言模型处理中最小的基本单位,可以是一个字符、一个词、一个子词,甚至是一个标点符号。在语言模型的训练和推理过程中,文本会被拆分成若干个token,这些token组成了模型的输入。这也是为什么所有模型都有 word embedding 或者 token embedding 的过程,其过程就是把每个 token 进行编码,编码成模型能够认识的数字矩阵。模型是不认识单词或者汉字的,都是需要经过 embedding 的操作。
而 token 便是 embedding 的最小单元,假设每个汉字就是一个 token,那么“人工智能”就是四个 token,就需要四个数字进行 embedding 的操作。或者“人工”与“智能”2 个 token,那么就需要 2 个数字进行 embedding 的操作。

Tokenization(分词)
Tokenization 是将文本分割成token的过程。根据不同的模型和应用场景,分词的方式有所不同:
字符级别的tokenization:每个字符都是一个token。这种方法对于处理未知词汇或创造新词汇非常有用,但通常会导致序列长度增加。词级别的tokenization:每个词都是一个token。这种方法直观但在处理新词或未登录词(OOV,out-of-vocabulary)时可能会遇到问题。子词级别的tokenization:使用子词单元(subword units),例如BPE(Byte-Pair Encoding)或WordPiece。这种方法在字符和词之间找到了一种平衡,既能处理未知词汇又能保持较短的序列长度。
Tokenization的具体方法:
Byte-Pair Encoding (BPE),BPE是一种基于频率的分词方法,常用于子词级别的tokenization。其基本思想是:统计所有字符的频率。找出频率最高的字符对,并将其合并成一个新的token。重复以上步骤,直到达到预定的词汇表大小。这种方法可以有效减少词汇表的大小,同时保留较高的表达能力。
WordPiece,WordPiece是一种常用于模型如BERT的分词方法,类似于BPE。它通过最大化训练数据的似然来选择最合适的子词单元。
假设有一句话:"I love machine learning."
字符级别的tokenization:['I', ' ', 'l', 'o', 'v', 'e', ' ', 'm', 'a', 'c', 'h', 'i', 'n', 'e', ' ', 'l', 'e', 'a', 'r', 'n', 'i', 'n', 'g', '.']
词级别的tokenization:['I', 'love', 'machine', 'learning', '.']
子词级别的tokenization(例如BPE):['I', 'love', 'mach', 'ine', 'learning', '.']

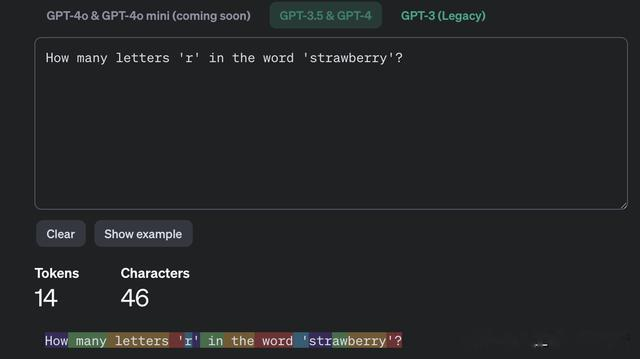
而 OpenAI 也公布了自己的 token 分词工具,可以直接在 OpenAI 的平台输入对应的文本,然后输出对应的分词规则与 token 数量。可以看到GPT系列的模型分词并不是每个单词就是一个 token,而是采用了子词级别的tokenization分词,比如 tokenized单词就是 2 个 token,因此大语言模型中的 token 并不是完全一个单词。而针对中文来讲,并也不完全是每个汉字就是一个 token,如下“一个”虽然是 2 个汉字,但是针对GPT就是一个 token。

而这个分词效果只是展示给人看的效果,而模型真正看到的是 embedding 后的数据。一个网友也是把每个 token 使用 emo 表情的方式来展现 token 长什么样子,而我们真正看到的就是一个个汉字或者单词,真正模型看到便是一个个数字。

而网友也是把每个 emo 表情赋予一个 token 数字,并使用代码来展示 token 长什么样子
!pip install tiktoken!pip install emojiimport tiktokenenc = tiktoken.encoding_for_model("gpt-4")print(enc.n_vocab) import emojiemojis = list(emoji.EMOJI_DATA.keys())import randomrandom.seed(15)random.shuffle(emojis)print(len(emoji.EMOJI_DATA))def text_to_tokens(text, max_per_row=10): ids = enc.encode(text) unique_tokens = set(ids) # map all tokens we see to a unique emoji id_to_emoji = {id: emoji for emoji, id in zip(emojis, unique_tokens)} # do the translatation lines = [] for i in range(0, len(ids), max_per_row): lines.append(''.join([id_to_emoji[id] for id in ids[i:i+max_per_row]])) out = '\n'.join(lines) return outtext = """Words vs TokensA word is most likely what you think it is - the most simple form or unit of language as understood by humans. In the sentence, “I like cats”, there are three words - “I”, “like”, and “cats.” We can think of words as the primary building blocks of language; the fundamental pieces of language that we are taught from a very young age.A token is a bit more complex. Tokenization is the process of converting pieces of language into bits of data that are usable for a program, and a tokenizer is an algorithm or function that performs this process, i.e., takes language and converts it into these usable bits of data. Thus, a token is a unit of text that is intentionally segmented for a large language model to process efficiently. These units can be words or any other subset of language - parts of words, combinations of words, or punctuation.There are a variety of different tokenizers out there which reflect a variety of trade offs. Well-known tokenizers include NLTK (Natural Language Toolkit), Spacy, BERT tokenizer and Keras. Whether or not to select one of these or a different tokenizer depends upon your specific use case. On average, there are roughly 0.75 words per token, but there can be meaningful differences among tokenizers."""print(text_to_tokens(text, max_per_row=15))
可以看到模型能够看到的 token 使用了 emo 来展示,而这里使用的是GPT-4的 token 分词数据,其模型有 10 万多个 token。
text = """How many letters 'r' in the word 'strawberry'?"""enc.encode(text)[4438, 1690, 12197, 364, 81, 6, 304, 279, 3492, 364, 496, 675, 15717, 71090]而模型其实真正看到的是每个 token 的数字。而这里需要注意的是每个标点符号也是一个 token
 https://platform.openai.com/tokenizerhttps://colab.research.google.com/drive/1SVS-ALf9ToN6I6WmJno5RQkZEHFhaykJ#scrollTo=75OlT3yhf9p5
https://platform.openai.com/tokenizerhttps://colab.research.google.com/drive/1SVS-ALf9ToN6I6WmJno5RQkZEHFhaykJ#scrollTo=75OlT3yhf9p5 