
全民智驾的元年到来,AI正成为车企竞争的新赛场。文丨智驾网 王欣编辑 | 雨来
全民智驾的元年到来,AI已成为车企竞争的新赛场。
3月5日,CVPR 2025成绩单出来了,其中,理想汽车上榜了4篇。
CVPR国际计算机视觉与模式识别会议是IEEE(电气和电子工程师协会)主办的一年一度的国际会议,被公认为计算机视觉领域的顶级会议之一,和ICCV、ECCV并称计算机视觉三大顶级会议,近年来也不断有自动驾驶领域的前沿研究获奖。
对于理想汽车的意义在于,这不仅是其首次以车企身份跻身全球顶级AI会议,更标志着其从“造车新势力”向真正发展为AI公司的战略转型有了一个阶段性的成果。
当天,理想汽车创始人、董事长、CEO李想在社交媒体上发文称:自从特斯拉的全自动驾驶(FSD)功能入华后,经过对比,理想AD Max V13的接管次数明显少于特斯拉FSD,表现更好。李想还提到,理想AD Max V13基于1000万条数据进行训练,并于2月27日全面推送,得到了用户的好评。

这次入选的四篇论文背后的署名作者是理想汽车副总裁、智驾负责人朗咸朋及其团队的多名工程师。在不久前的理想汽车AI Talk中,朗咸朋曾在直播中表示,预计2025年理想汽车能够实现L3级的智能驾驶。

此次入选的StreetCrafter、DrivingSphere、DriveDreamer4D与ReconDreamer四篇论文,主要是理想汽车在自动驾驶模拟仿真方向做的创新,同时直面回答自动驾驶研发的核心痛点难题:数据成本高企与极端场景覆盖不足。
下面我们分别解析这四篇论文:
01.
StreetCrafter:基于LiDAR与视频扩散模型的街景合成技术
StreetCrafter是作为理想汽车联合浙江大学、康奈尔大学提出的自动驾驶仿真技术,其核心目标是通过LiDAR点云与视频扩散模型的融合,解决传统方法(如NeRF、3D高斯散射)在视角偏离训练轨迹时渲染模糊或伪影的难题。

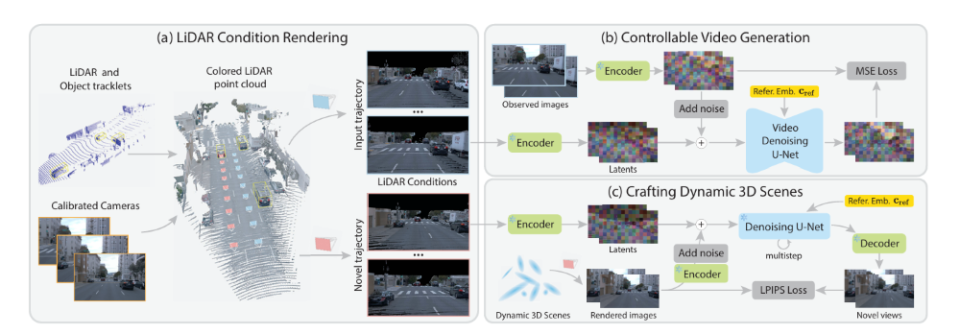
其核心技术包含两部分:
可控视频扩散模型:通过多帧LiDAR点云聚合生成全局点云,并渲染为像素级条件图像,作为扩散模型的输入。在推理阶段,根据新视角的相机轨迹生成高保真视频帧,支持实时渲染和场景编辑(如对象平移、替换和删除)。

动态3D高斯表示蒸馏:利用生成的新视角图像作为监督信号,优化3D高斯的几何与纹理,结合混合损失函数(L1、SSIM、LPIPS)和渐进优化策略,提升视角外推能力,同时保持80-113 FPS的实时渲染速度。
实验结果显示,在Waymo数据集上,StreetCrafter在3米视角偏移下的FID为71.40,显著优于Street Gaussians的93.38,且在复杂区域(如车道线和移动车辆)的细节清晰度更高。

StreetCrafter其应用价值在于降低自动驾驶训练对真实数据的依赖。例如,在训练车辆变道算法时,可通过调整相机轨迹生成多角度变道场景视频,模拟不同光照、天气条件下的数据,以及应对极端场景下的仿真测试。
在应对突发障碍物(如行人横穿、车辆逆行)时,利用场景编辑功能,在LiDAR点云中插入虚拟障碍物(如删除道路上的车辆并替换为行人),生成测试视频。例如,模拟行人突然闯入车道,验证系统紧急制动能力。
但局限性包括对LiDAR标注的高成本依赖(数据采集成本提升)、生成速度仅0.2FPS,以及对形变物体(如行人)的建模精度不足。
也许正是意识到这些不足,日前理想汽车宣布:今年推出的所有车型都将标配激光雷达传感器。
02.
DrivingSphere:生成式闭环仿真框架与4D高保真环境建模
DrivingSphere旨在构建一个支持动态闭环交互的4D(3D空间+时间)仿真环境,以克服传统开环仿真数据多样性不足、闭环仿真视觉保真度低的问题。
框架主要通过两大模块和一个机制,为智能体构建了高保真4D世界,评估自动驾驶算法。

动态环境组合(DEC模块):基于OccDreamer(3D占用扩散模型)生成静态场景,并结合“Actor Bank”动态管理交通参与者(如车辆、行人),通过语义相似性或随机采样选择参与者,实现城市场景的无限扩展。
该模块采用OccDreamer,一个基于鸟瞰图(BEV)和文本条件控制的3D占用扩散模型,用于生成静态场景。它通过VQ-VAE将3D占用数据压缩为潜在表示,并结合ControlNet分支注入BEV地图和文本提示,逐步生成城市级连续静态场景。

视觉场景合成(VSS模块):利用双路径条件编码(全局几何特征与局部语义图)和视频扩散模型(VideoDreamer),生成多视角时空一致的高保真视频,并通过ID感知编码绑定参与者外观与位置,解决外观漂移问题。

闭环反馈机制:通过Ego Agent(被测算法)与环境Agent(交通流引擎)的交互,实现“感知-决策-环境响应”的动态闭环测试,验证算法在复杂场景中的鲁棒性。
在实验与结果方面,DrivingSphere在视觉保真度评估中表现出色。
在nuScenes数据集上,DrivingSphere的OccDreamer模块生成的场景FID显著优于SemCity,视频生成结果在3D目标检测和BEV分割指标上超越MagicDrive与DriveArena。

总的来看,DrivingSphere其核心贡献在于将几何建模与生成式技术结合,但论文也指出,需进一步优化动态行为的复杂性(如极端场景覆盖不足)和计算成本。
03.
DriveDreamer4D:基于世界模型的4D驾驶场景重建与轨迹生成
DriveDreamer4D的目标是通过世界模型(World Model)增强4D驾驶场景重建的时空一致性与生成质量,解决传统传感器仿真方法(如NeRF、3DGS)在复杂动作(如变道、加速)下的局限性。
比如,现有传感器仿真技术(如NeRF、3D高斯散射)依赖与训练数据分布紧密匹配的条件,仅能渲染前向驾驶场景,难以处理复杂动作(如变道、急刹)导致的视角偏移或动态交互问题,常出现“鬼影”“拖影”等伪影。

亦或是开环仿真数据多样性不足,闭环仿真则面临视觉保真度低、动态交互不真实等挑战。
那么世界模型通过预测未来状态生成多样化驾驶视频,但其此前局限于二维输出,缺乏时空连贯性,无法满足4D场景重建需求。
DriveDreamer4D的核心架构分为两大部分:

新轨迹生成模块(NTGM):支持文本描述或自定义设计生成轨迹(如变道、加减速),并通过仿真环境(如CARLA)进行碰撞检测与安全性评估,生成控制信号以驱动视频合成。
正则化训练策略(CDTS):引入感知一致性损失,优化合成数据与真实数据的分布对齐,并通过误差反馈迭代提升轨迹生成质量。
实验表明,DriveDreamer4D在时空一致性和视觉真实性上优于PVG、S³Gaussian等基线模型。用户调研中,其在常规场景(如单车道变道)的生成效果获好评,但在跨车道等极端动作下仍存在重建失效问题。
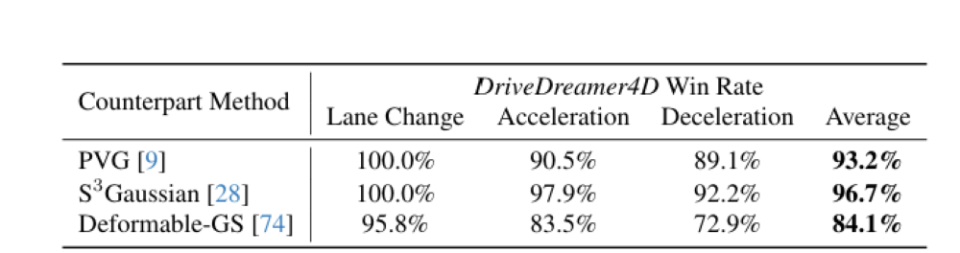
该研究的应用价值在于降低数据采集成本并增强算法鲁棒性,但需进一步结合时序建模与多模态输入(如高精地图)以提升复杂场景的适应性。
04.ReconDreamer:动态驾驶场景在线修复与渐进式数据更新
ReconDreamer聚焦于解决动态场景重建中大幅动作导致的伪影问题(如远景扭曲、车辆遮挡)。

针对这一类问题,ReconDreamer依然是利用世界模型的知识,通过在线修复(DriveRestore)和渐进数据更新策略( Progressive Data Update Strategy以下简称PDUS)两大手段,解决复杂动作的渲染质量问题。
在线修复技术(DriveRestorer):构建退化帧与正常帧的修复数据集,通过扩散模型去噪策略修复伪影,并采用脱敏策略优先处理问题严重区域(如天空与远景)。

渐进式数据更新策略(PDUS):分阶段生成更大跨度的轨迹数据(如1.5米→3米→6米),逐步扩展模型对复杂动作的适应能力,直至收敛。

ReconDreamer的创新点在于首次将世界模型与动态重建结合,实现了实时修复渲染缺陷,并通过渐进式训练策略解决了大动作渲染中的数据分布偏移问题。

这为自动驾驶闭环仿真提供了高保真传感器数据生成方案,支持复杂场景(如紧急变道和多车交互)的可靠测试。
当然局限性也包括,比如在线修复机制增加了训练时间,且目前仅在Waymo数据集上进行了验证,未来需要扩展至更多复杂环境(如雨天和夜间)。
定量分析结果显示,ReconDreamer在NTA-IoU(车辆检测框重合度)上相较于基线方法(如Street Gaussians和DriveDreamer4D)提升了24.87%,在NTL-IoU(车道线重合度)上提升了6.72%,同时FID(图像质量评估)降低了29.97%。用户研究表明,96.88%的用户认为ReconDreamer在大动作渲染中优于DriveDreamer4D。
定性分析结果显示,ReconDreamer有效消除了远景模糊和天空噪点,保持了车辆位置和形状的一致性,并确保车道线在大偏移下的平滑无断裂。

此外,消融实验结果表明,DriveRestorer的主干网络基于DriveDreamer-2的掩码版本效果最佳,而PDUS的步长设定为1.5米时性能最优,过大的步长会导致噪声累积。
