自回归语言模型的英文 Autoregressive Language Models,简写为 AR-LM 。自回归语言模型是当前大模型预训练的核心技术之一,其核心思想是通过序列中前面的词预测下一个词,逐步生成完整文本。
1. 自回归语言模型的核心原理

自回归语言模型的核心原理围绕序列概率建模展开,其核心是通过链式法则分解文本序列的概率分布,并基于前文逐词预测后续内容。本文将从数学基础、建模逻辑、训练目标到实现细节的逐步解析。
1.1 数学基础:链式法则与条件概率


自回归模型的本质是对序列的联合概率分布进行建模。假设一个文本序列为
x=(x1,x2,...,xT),根据概率链式法则,其联合概率可分解为:
p(x)=p(x1)⋅p(x2∣x1)⋅p(x3∣x1,x2)⋯p(xT∣x<T)
即:

关键特性:每个位置 xt 的概率仅依赖于前文 x<t,而非整个序列。
单向性:建模时只能利用左侧(或右侧,但通常为左到右)的上下文信息。
1.2 建模逻辑:逐词生成与条件依赖

自回归模型的核心任务是预测序列中每个位置的词,其过程可分解为:
输入表示:
将前文 x<t 转换为向量(如此嵌入 + 位置编码)。
条件概率建模:
基于前文计算下一个词的概率分布 p(xt∣x<t)。
生成策略:
从概率分布中采样(如贪心搜索、随机采样)得到 xt,并迭代生成整个序列。
生成过程示例(以句子 "I love NLP" 为例):
初始输入:<START> → 预测第一个词 "I"。
输入:<START> I → 预测第二个词 "love"。
输入:<START> I love → 预测第三个词 "NLP"。
终止条件:生成 <END> 标记或达到最大长度。
1.3 训练目标:最大似然估计(MLE)

模型通过最大化训练数据的对数似然来学习参数:

损失函数:
对每个位置的预测结果计算交叉熵损失(Cross-Entropy Loss),
整体损失为所有位置的平均。
Teacher Forcing:
训练时使用真实前文作为输入,避免错误累积(与推理时用模型自身生成的前文不同)。
1.4 模型架构:Decoder-Only Transformer
自回归模型通常基于Transformer的Decoder结构实现,核心设计包括:
1.4.1 掩码自注意力(Masked Self-Attention)

目的:确保每个位置仅关注前文,避免未来信息泄露。
实现方式:
在注意力权重矩阵中,使用下三角掩码矩阵(元素为0或负无穷),
使第 t 个位置只能看到前 t−1个位置的词。
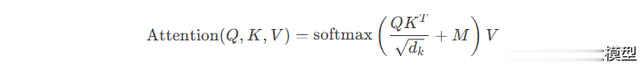
其中掩码矩阵 MM 的下三角部分为0,上三角部分为负无穷。
1.4.2 位置编码(Positional Encoding)
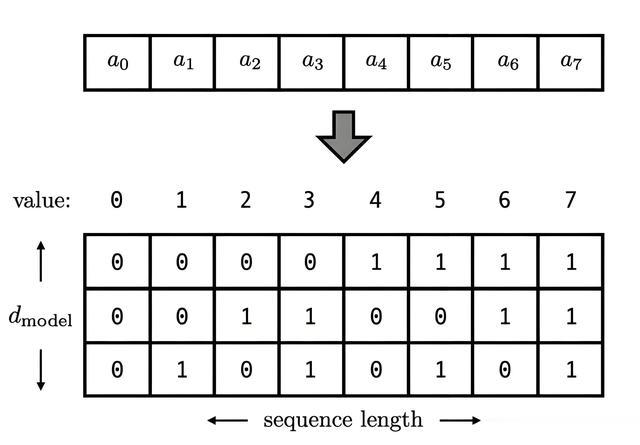
作用:为模型提供序列中词的位置信息。
实现方式:
绝对位置编码:如正弦/余弦函数(原始Transformer)。
相对位置编码:如旋转位置编码(RoPE,用于LLaMA、GPT-3),通过旋转矩阵引入位置差异。
隐式位置编码:通过注意力机制中的相对位置偏置(如T5)。
1.4.3 前馈网络(FFN)与残差连接

FFN层:对每个位置的隐藏状态进行非线性变换。
残差连接:缓解梯度消失,支持深层模型训练。
数学形式:模型基于链式法则分解序列概率为条件概率的乘积:

每个时间步预测 xtxt 时,仅依赖前文 x<tx<t(如从左到右的单向建模)。
训练目标:
最大化序列的似然函数,等价于最小化交叉熵损失。
每个位置的损失为预测词与真实标签的交叉熵,整体损失为各位置损失的均值或总和
自回归语言模型是一种通过 预测序列中下一个词 来学习语言表示的模型。其核心思想是:
即根据前文(上文)的单词,预测当前词的概率分布。
2. 自回归模型的生成特性
2.1 局部依赖与全局依赖
局部依赖:模型更关注前文中近距离的词(如最近几个词)。
全局依赖:通过多层自注意力机制,模型可捕捉长程依赖关系(如段落级逻辑)。
2.2 生成连贯性
优点:逐词生成时,每个词的选择严格依赖前文,保证逻辑连贯。
缺点:一旦生成错误词,后续生成可能偏离正确路径(错误累积)。
2.3 温度参数(Temperature)
作用:控制生成多样性,通过调整 softmax 前的 logits:

3. 自回归语言模型的典型应用
3.1 生成类任务
文本生成:
GPT-3、GPT-4:生成文章、代码、对话等。GLM-130B:支持多语言生成和复杂任务(如代码解释)。
对话系统:
ChatGLM-6B:通过自回归生成高质量对话回复。
3.2 序列到序列任务
机器翻译:
将源语言文本生成为目标语言(如英译中)。
文本摘要:
生成简洁的文本摘要(需结合编码器-解码器结构)。
3.3 代码生成与理解
模型:
OpenAI的CodeGen、GLM系列:通过预训练学习代码语法和语义。
优势:
自回归模型能生成连贯的代码片段,但需结合数据增强(如GitHub代码库)。
