Copiloting the Copilots: Fusing Large Language Models with Completion Engines for Automated Program Repair
Yuxiang Wei1, Chunqiu Steven Xia1, Lingming Zhang1
1University of Illinois Urbana-Champaign, USA
引用
Yuxiang Wei, Chunqiu Steven Xia, Lingming Zhang. Copiloting the Copilots: Fusing Large Language Models with Completion Engines for Automated Program Repair[C]//Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2023: 172-184.
论文:https://dl.acm.org/doi/abs/10.1145/3611643.3616271
仓库:https://github.com/ise-uiuc/Repilot
摘要
大型语言模型(LLMs)在协助开发人员进行各种编码任务方面被证明是有帮助,并已直接应用于补丁合成。然而,大多数LLMs将程序视为令牌序列,忽视目标编程语言的基础语义约束。这导致生成大量静态无效的补丁,从而妨碍该技术的实用性。本文提出了一个Repilot框架,可通过在修复过程中合成更多有效的补丁来进一步协助AI“副驾驶”(即LLMs)。Repilot的关键思路是,许多LLMs通过自回归方法(即逐个令牌)产生输出,类似于人类编写程序,可以通过一个补全引擎得到明显提升和指导。Repilot通过LLM和补全引擎之间的交互,协同合成候选补丁,即1)修剪LLM建议的不可行令牌,2)根据补全引擎提供的建议主动补全令牌。通过实验验证了该框架的有效性,与基本LLM相比,Repilot能够在相同的生成预算下产生更多有效和正确的补丁。
1 引言
自动程序修复(APR)旨在通过自动合成给定错误代码补丁,减少开发人员手动修复错误的工作量。最先进的传统APR工具主要基于手工制作的修复模板,以匹配错误代码模式并应用相应的代码更改。尽管优于其他传统技术,但这些工具只能修复预设模板中的错误类型,无法推广到新的错误类型。随着深度学习(DL)技术的发展,研究人员基于神经机器翻译(NMT)架构构建了基于学习的APR工具。他们训练NMT模型,通过学习从开源提交中抓取的错误和修复代码对将错误代码翻译成正确代码。然而,这些工具的训练集可能在规模上受限,并且还包含不相关或嘈杂的提交。
LLMs不仅在许多自然语言处理任务上表现出色,而且被证明在协助开发人员完成各种编码任务方面是可靠的“copilots”。现代LLMs通常包括大量可用的开源代码存储库作为其训练数据集的一部分。研究人员最近将LLMs应用于自动程序修复(APR):不是将错误代码翻译成正确代码,而是使用LLMs从周围环境中合成正确的修补程序。AlphaRepair将APR问题重新表述为一个填空任务:它首先用掩码标记替换错误代码片段,然后在给定周围环境的情况下使用CodeBERT填充正确的代码。
虽然先前的LLM用于APR技术实现了最先进的错误修复性能,但以黑盒方式使用LLMs,即底层LLM根据令牌分布生成程序,而无需对代码进行结构或语义理解。为了突显当前LLMs用于APR工具的局限性,在图1中本文展示3种LLM可能生成错误修补程序的情景。1 生成不可行的令牌。在图1.1中,LLM生成String来完成asString方法的概率很高(>90%)。然而,asString不是对象t的有效字段访问,也不是当前错误方法的范围的一部分。在这种情况下,使用asString生成的修补程序永远不会正确,因为它无法编译。通过直接使用模型概率,LLMs可能会使用无效令牌生成许多修补程序,并降低生成正确修补程序的可能性(0.2%)。2 难以生成稀有令牌。LLMs通常无法一步生成完整的标识符名称,因为它使用子词令牌化将不常见的单词分解为更小的子词。这些不常见的单词在代码中表现为稀有的标识符,其中标识符名称是多个单词的驼峰式或下划线组合(例如,在图1.2中的asEndTag)。因此,LLMs需要逐步生成这些标识符,不仅需要多次迭代,还需要每一步的准确输出。由于先前的方法是基于概率进行抽样,修复错误的稀有令牌的补全可能性极低。3 不明确考虑类型。除了可能生成超出范围的标识符外,LLMs还无法访问各种类型信息,这些信息给出了对有效标识符的提示。在图1.3中,asEndTag()的返回类型是EndTag,其定义在LLM的直接上下文中没有明确给出。因此,LLMs不知道EndTag的正确成员字段,并且可能生成包含不符合所需类型的标识符的无效修补程序。相反,补全引擎可以完全访问项目,并且可以通过对程序的抽象语法树进行静态分析轻松找出asEndTag()的返回类型。通过将代码视为文本令牌的序列,重要的类型信息未被编码。

图1:现有基于LLM的APR技术的局限性
为解决上述限制,本文提出Repilot,一个通过将LLMs与补全引擎融合来进一步辅助AI“共同开发者”(即LLMs)的框架,以合成更多有效的修补程序。补全引擎可以以容错的方式解析不完整的程序并推理语义。本文关键洞见是将LLM自回归令牌生成类比为人类开发者编写代码,其中补全引擎可以提供实时更新以检查人类/LLMs编写的部分代码是否有效。Repilot首先使用LLM提供生成修补程序中下一个令牌的概率,然后查询补全引擎以通过动态将无效令牌的概率归零来修改概率列表。然后,我们可以从新的概率列表中进行抽样以选择下一个令牌。此外,认识到补全引擎能够提供建议补全的能力,我们在只有一个可能的标识符后缀可以补全上下文时使用此功能。这不仅允许Repilot生成具有有效的稀有和长标识符的修补程序,还减少了需要迭代生成长标识符名称的LLMs的工作量。
例如,Repilot根据补全引擎的判断直接剪除图1.1中的String和Name令牌,因为它们在补全引擎看来是不可行的。在图1.2中,补全引擎识别到asEndTag是前缀asEnd的唯一有效延续,因此Repilot直接补全此令牌,而不需要查询LLM。为了应对补全引擎的时间成本,本文实现了几种优化技术来尽量减少开销。Repilot直接适用于通用编程语言,同时引入了最小的开销,并且可以在不查询LLM的情况下通过补全引擎主动补全当前生成。
为了展示Repilot的通用性,本文使用两个具有不同架构和规模的LLMs实例化Repilot:CodeT5-large,一个具有7.7亿参数的编码器-解码器LLM,以及InCoder-6.7B,一个仅有67亿参数的解码器LLM,两者都能够从前缀和后缀上下文进行代码填充。本文还基于Eclipse JDT Language Server实现Repilot的Java补全引擎,通过一致的语言服务器协议提供各种基于语义的分析。本文在广泛研究的Defects4J 1.2和2.0数据集的子集上评估了Repilot,并在正确修复的数量和编译成功率方面展示了最先进的结果——生成的修补程序中可以成功编译的百分比。此外,虽然这项工作仅评估了Repilot在APR的应用,但相信整体框架可以轻松应用于其他代码生成任务,包括代码补全、程序合成和测试生成。贡献如下:
方向。本研究开辟了一个新的方向,将LLMs与补全引擎融合,以实现更强大的自动程序修复及更多其他应用。与先前的技术相比,后者要么进行后处理来修复无效生成,要么使用简单的静态方法来近似这些有效令牌,本方法利用强大的补全引擎直接为部分程序提供准确的反馈,以避免生成无效令牌。技术。本文实现了Repilot,一种LLMs用于自动程序修复的方法,该方法使用了CodeT5和InCoder模型,以及我们修改过的Eclipse JDT Language Server作为补全引擎,执行填空式修复。Repilot使用补全引擎系统地剪除LLMs生成的无效令牌,并在给定当前前缀的情况下直接补全代码。此外,本研究实现了优化以显著减少Repilot的开销。工具开源发布在:https://github.com/ise-uiuc/Repilot。研究。本文将Repilot与Defects4J 1.2和2.0上的最先进的自动程序修复工具进行比较。Repilot能够分别修复66个Defects4J 1.2的单个块错误和50个Defects4J 2.0的单行错误,比先前的最佳基准线在两个数据集上的修复数量多30个。进一步的评估表明,Repilot能够持续提高生成修补程序的有效性和正确性,并且开销有限(CodeT5为7%,InCoder可以忽略不计)。2 技术介绍
与最近大多数基于深度学习的自动程序修复工具一样,Repilot专注于修复单个代码块错误,其中修补程序是通过在完美的故障定位下更改连续的代码部分而获得的。Repilot可以通过一次性替换所有代码块位置,并使用LLM生成替换代码块的分开填充令牌来扩展为多代码块错误。受益于LLM时代,如图2所示,在本文中,我们将修复问题视为填空任务,其中修补程序首先通过用掩码跨度令牌(SPAN)替换有错误的代码块,然后使用LLM从周围代码上下文中直接合成修复后的代码块以替换跨度令牌。

图2:克隆式程序修复
图3显示了Repilot合成作为原始有错误程序的修复代码块的概述。生成循环包括一个不断更新的循环,其中的令牌是由语言模型的补全引擎之间的协同生成的。循环从将当前生成作为输入应用于语言模型开始(1),语言模型返回一个从建议的下一个令牌到其概率的映射的搜索空间。然后,Repilot进入一个令牌选择阶段,该阶段重复从搜索空间中抽样一个令牌,搜索其可行性,并修剪搜索空间,直到接受一个令牌。每次抽样令牌时,Repilot首先检查是否命中了记忆(2),该记忆存储已知的可行或不可行的令牌。不可行令牌的记忆包括使用在第4.3节中讨论的前缀数据结构(Trie)。当令牌命中记忆且不可行时,搜索空间将通过将该令牌的概率设置为零来修剪(3),并且下一次抽样将在更新后的搜索空间上运行。这样,在令牌选择阶段不会再次抽样相同的令牌。如果令牌未命中记忆,则在补全引擎的指导下修剪搜索空间(4),我们将在第4.2节详细说明。假设抽样的令牌被补全引擎拒绝,Repilot会将其概率归零。否则,它被接受,此令牌选择过程终止。记忆在两种情况下都会得到更新(5)。令牌被接受后(6),我们进一步利用补全引擎,试图主动补全令牌(7)。主动补全,如第4.4节所讨论的,可能会产生更多的令牌,也可能不会对接受的令牌做任何添加。最后,Repilot将所有新生成的令牌追加到当前生成中,并开始一个新的循环,直到生成完整的修补程序。当模型生成特殊的结束令牌时,循环停止。

图3:Repilot整体框架
2.3 补全引导的搜索空间剪枝
本节将解释Repilot如何利用补全引擎来修剪LLM的搜索空间的核心思想。

算法2深入解释了补全引擎如何帮助修剪模型的搜索空间。函数GuidedPrune将补全引擎CE、当前程序prog、当前插入符号位置插入符号和模型给出的概率图标记作为输入,并生成下一个标记作为程序prog在插入符号位置的延续。第9行的修剪是通过将进入概率图标记的下一个标记的概率设置为零来完成的。这一行使用的符号随后定义。假设

是任意函数,并且,

是同一类型的偏函数,这意味着域X中只有输入的子集与范围Y中的输出相关联。我们将使用 a 赋值改变 f 中输入的输出值的操作定义为

2.2 快速搜索记忆法
算法2(GuidedPrune)涉及一个试验和修剪操作的循环,在某些情况下会减慢修复任务。为加快其搜索过程,本文应用几种记忆技术来减少调用补全引擎进行分析的频率。
存储被拒绝的令牌。要在实践中修复一个错误,需要生成大量的样本,这意味着相同的程序prog’和caret’(第4行到第5行)可能会在算法2中重复出现(Guid-edPrene)。因此,我们可以通过将第9行修剪的所有标记存储在变量中来记住它们从程序prog和插入符号位置插入符号映射到一组被拒绝的标记。
记忆已接受的令牌。除了被拒绝的令牌,我们还可以在变量中记住以前被接受的令牌,以避免在第7行到第8行查询补全引擎所产生的开销。
构建被拒绝令牌的前缀树。语言模型的词汇表中的许多标记通常是另一个的前缀。很明显,如果一个令牌被拒绝,这意味着在令牌之后不能形成任何可能的延续来获得静态有效的程序,那么任何共享这种前缀的令牌都应该被拒绝。出于这个原因,我们构建并不断更新给定prog和插入符号的所有被拒绝令牌的前缀树或Trie,并检查Trie中的任何令牌是否是算法2中第3行之后的下一个令牌的前缀。如果是这种情况,Repilot直接跳到下一次迭代,避免了进一步的分析。
2.3 主动补全
补全引擎不仅能够确定模型建议的下一个可能代币的可行性,如2.1所示,而且可以在不查询模型的情况下主动建议当前程序的潜在延续,类似开发人员从自动补全中受益。如下算法详细描述了主动补全。函数ActivelyComplete接受三个输入:补全引擎CE、当前程序prog和当前插入符号位置插入符号,并输出一系列补全标记作为prog在插入符号处的延续。

3 实验评估
3.1 实验设置
研究问题。本文中对一下研究问题进行评估:
RQ1:Repilot的漏洞修复能力与最先进的APR技术相比如何?
RQ2:Repilot在提高补丁生成的编译率方面有多有效?
RQ3:Repilot的所有组成部分是否对其有效性做出了积极贡献?
RQ4:Repilot能概括到bug和模型的不同主题吗?
评估数据集。本文使用了Hugging Face上获取的CodeT5-large和InCoder-6.7B模型的Python实现。在Python中构建了一个包含5K行代码的生成管道,并在Java中实现了Eclipse JDT Language Server的修改版本,额外添加了1.5K行代码,该版本作为Repilot框架的严格补全引擎默认生成使用了顶部p核心采样,其中p=1.0,温度=1.0,最大令牌数=50,每个bug样本5000次,以便与先前工作进行公平比较。由于APR的成本较高,在消融研究和通用性评估中每个bug样本500次。并遵循先前的工作,将每个bug的生成和验证超时设置为5小时。同时使用了Defects4J这一广受欢迎的修复基准进行评估。Defects4J是一个手工策划的Java数据集,其中包含了源项目的有错误和修复版本对,以及开发者用于验证的测试套件。总体而言,本文考虑了来自Defects4J 1.2的138个单代码块错误和来自Defects4J 2.0的135个单代码块错误。
对比方法。本文将Repilot与传统的、基于NMT的以及LLM用于APR工具的最先进基线进行比较。本研究评估AlphaRepair作为LLM用于APR方法的最佳表现。对于基于NMT的方法,本文选择了6种最近的工具RewardRepair、Recoder、CURE、CoCoNuT、DL Fix和SequenceR,它们基于NMT架构。此外,本研究还比较了12种传统的APR工具:PraPR、TBar、AVATAR、SimFix、FixMiner、CapGen、JAID、SketchFix、NOPOL、jGenProg、jMutRepair和jKali。总之,本研究包括19种APR基线,并在Defects4J 1.2和2.0上与Repilot进行比较。
评估指标。评估方法Repilot性能时使用了如下三个常见指标:可信修补程序是指通过了所有测试用例但可能违反了真实用户意图的修补程序;正确修补程序是指在语义上等同于开发者修补程序的修补程序。遵循常见的自动程序修复实践,我们通过手动检查每个可信修补程序来确定语义等效性;修补程序编译率也在许多基于深度学习的自动程序修复工作中使用,它表示在所有生成的修补程序中可编译修补程序的百分比。
RQ1 与现有工具的比较
实验设计。在RQ1和RQ2中,我们采用了先前的填空式自动程序修复方法,并利用修复模板进行评估。与其完全替换整行有错误的代码不同,这些模板系统地保留了部分有错误的代码,以减少LLM需要生成的代码量。但在RQ3和RQ4中,我们没有使用任何修复模板,而是选择了较少的样本数量,并专注于不同实验配置的影响。
在Defects4J 1.2上,我们首先将Repilot与最先进的自动程序修复工具进行比较。Repilot在填空式评估中取得了66个正确修复的bug,表现优异。此外,Repilot能够修复其他自动程序修复工具未能修复的7个bug。图4展示了一个唯一的bug(Closure-133)的例子,只有Repilot能够修复。该bug通过添加新的赋值语句来修复,这对其他工具而言很难生成,但Repilot通过主动补全的方式成功生成了修补程序。

图4: Repilot 对 Defects4J 1.2 的独特错误修复
在Defects4J 2.0上,本文使用先前的填空式自动程序修复方法,利用修复模板,以减少LLM需要生成的代码量。Repilot在这个数据集上表现出色,修复了50个错误,比次优基线多出16个。这表明Repilot不仅可以适用于两个版本的Defects4J数据集,还展示了修复模板提升LLM-based APR工具性能的能力。

图5: Repilot 对 Defects4J 2.0 的独特错误修复
图5展示了Defects4J 2.0中只有Repilot能够修复的一个特殊bug。Repilot通过分析部分程序并实现复杂的类型传播,成功修复了这个bug,这对于先前基于LLM和NMT的APR工具来说可能是困难的。
RQ2 变异率分析
本文对Repilot生成的修补程序与先前基于学习的APR技术进行了编译率评估。表1显示在Defects4J 1.2数据集上修补程序的可编译百分比。与先前工具相比,Repilot在生成的修补程序的可编译百分比显著提高。基于LLM的APR工具(Repilot和AlphaRepair)能够维持其编译率,而基于NMT的工具(CoCoNuT和CURE)的编译率随着生成的修补程序数量的增加而急剧下降。这显示了LLM生成大量合理修补程序的能力。在生成1000个修补程序时,Repilot能够维持近60%的编译百分比,而先前的方法则仅略高于30%。
表1: 在 Defects4J 1.2 上与现有 APR 工具在编译率方面的比较。-"表示无数据。

与CURE相比,Repilot利用强大的补全引擎跟踪当前上下文,以获得更准确的剪枝步骤,而CURE通过静态分析获得有效标识符的过度估计,并用于修剪NMT模型生成的无效标记。此外,与RewardRepair相比,Repilot直接使用LLM结合补全引擎,避免了训练新模型的高成本,后者通过惩罚不能编译的修补程序来提高编译率。此外,Repilot利用补全引擎的主动补全能力直接生成这些罕见的标识符,进一步提高了编译率。因此,Repilot能够在所有四种不同设置中实现最高百分比的可编译修补程序。
RQ3 消融研究
表2显示在Defects4J 1.2单个块错误上的四个变体中,每个修补程序的生成时间(每个修补程序的秒数)、可编译和可行修补程序在所有唯一生成的修补程序中所占的百分比、可行修补程序的数量以及正确修补程序的数量。仅使用基础LLM进行APR(Repilot∅),Repilot实现了最低的编译率为43.2%。通过添加由补全引擎提供的修剪,我们可以显著提高编译率至60.7%,可行修补程序的数量从56增加到62,正确修补程序的数量从37增加到41。通过添加主动补全技术,本研究实现了完整的Repilot,进一步提高了编译率至63.4%,可行百分比为5.21%,可行修补程序最多为63个,正确修补程序最多为42个。
表2: Repilot的组件贡献

结果。观察修补程序生成时间,从Repilot∅开始,通过补全引擎进行修剪会导致超过25%的额外开销。然而,通过使用记忆化(Repilotp),可以显著减少这一开销,通过避免在知道标识符无效时查询补全引擎,使得开销约为10%。此外,主动补全可以进一步将开销降低至7%,因为我们不必为生成的每个步骤都对LLM进行抽样,而是可以主动补全一个标识符。因此,所有组件都对Repilot的整体有效性有贡献。相比直接使用LLM进行修补程序合成,Repilot可以持续提高编译和可行率,以及生成更多的可行/正确修补程序,同时产生的额外开销很小。
RQ4 可推广性
为展示Repilot在不同bug类型和模型上的泛化能力,本文进一步使用CodeT5在Defects4J 2.0的所有单块错误上评估Repilot。同时还使用更大的InCoder-6.7B模型实例化和评估Repilot。与RQ3相同,由于APR的高成本,本文在RQ4中也进行500次采样。表格3显示了基线Repilot∅和完整的Repilot方法在不同bug类型和模型上的比较。本研究考虑了与RQ3相同的一组Defects4J 1.2单块错误以及额外的一组Defects4J 2.0单块错误。
表3:Repilot 在错误主体和模型之间的通用性
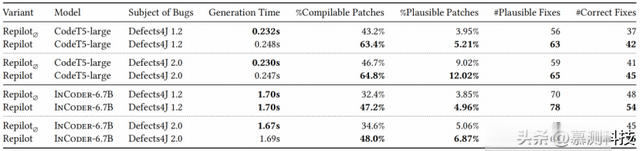
结果。经过调查,Repilot与CodeT5在Defects4J 1.2上超越了基线,正如RQ3所示。此外,在Defects4J 2.0上,它还可以获得更多的可编译和可行修补程序,以及更多的可行和正确修补程序,增加了18.1个百分点(pp)的编译率和3.0个百分点(pp),以及6个更多的可行修复和4个更多的正确修复,带来了7.4%的额外开销。与此同时,当Repilot使用InCoder实例化时,它在Defects4J 1.2和Defects4J 2.0上产生的可编译和可行修补程序更多,以及更多的可行和正确修复,超过了基线InCoder。最终,在Defects4J 1.2上增加了6个正确修复,在Defects4J 2.0上增加了1个。将Repilot与InCoder和CodeT5进行比较的一个主要区别是,当Repilot配备InCoder时,比CodeT5更大的模型会带来可忽略的开销。这是因为与使用较大模型的自回归抽样的高成本相比,通过查询补全引擎所增加的额外成本要小得多,因此在较大模型上应用Repilot的开销变得微不足道。此外,与CodeT5相比,不论是否与Repilot一起应用,较大的InCoder模型都可以在Defects4J 1.2和2.0上持续修复更多的错误,进一步证实了较大的LLM通常在APR中表现更好的先前发现。总的来说,实验结果表明Repilot能够泛化到不同的bug集(包括Defects4J 1.2和2.0中的单块错误)以及更大的LLM(InCoder)。
转述:石孟雨
