
你有没有想过能用一台电脑生成逼真的视频?
朋友们聚在一起时,这样的问题常常引发热烈讨论。
我们总是对技术的进步充满好奇,尤其是那些看似遥不可及却突然变得触手可及的技术。
最近,有一个项目正悄然改变视频生成的游戏规则——Open-Sora 2.0。
Open-Sora 2.0的亮点之一就是它的高质量视频生成能力。
观看它的Demo,你会被其视觉效果所震撼。
不仅视频画质出色,动作幅度还可以根据需求设定。
想让人物在视频里做一个更加细致的动作?
没问题,Open-Sora 2.0都能办到。

它能生成流畅的24 FPS视频,无论是乡村景色还是自然风光,都是一如既往的细腻与流畅。
在这样的视频生成效果面前,我们不得不感叹技术的进步。
开源革命:Open-Sora 2.0大揭秘说到Open-Sora 2.0的发布,这背后还有一个低成本高效能的故事。
显然,视频生成模型的发展通常需要高昂的投入。
举例来说,Meta的模型训练用了6000多张GPU卡片,耗资百万美元,而Open-Sora 2.0却仅用20万美元(224张GPU),成功训练出了商业级的视频生成模型,并且性能媲美那些高成本的闭源模型。
不仅如此,Open-Sora 2.0不仅性能出色,还全面开源了模型权重、推理代码及分布式训练全流程,让更多人能够参与其中。
这种开源的趋势正在让高质量视频生成技术变得普及,触手可及。
GitHub上的开源仓库更是为社区提供了丰富的资源,吸引了众多开发者的关注与参与。
实现突破:低成本高效能优化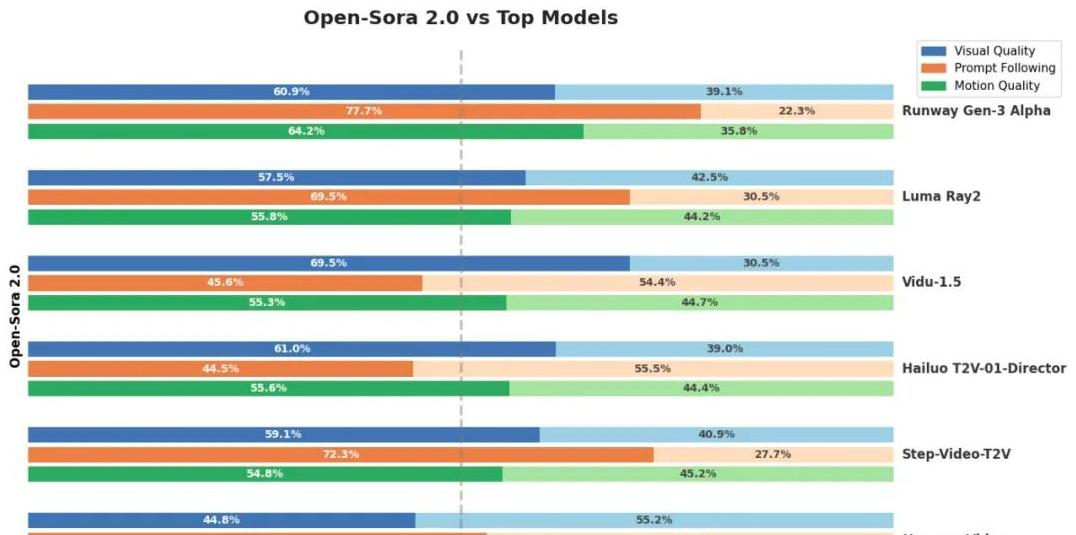
从Open-Sora 1.2到2.0的升级过程中,团队对成本和效能进行了极致优化。
通常情况下,市面上的10B以上视频模型,单次训练成本需要百万美元,而Open-Sora 2.0将成本压缩到仅20万美元。
到底是怎样实现的呢?
第一,他们通过严格的数据筛选机制,确保模型输入的训练数据质量可靠。
优先训练图生成视频任务,以加速模型收敛,而不是直接进行高分辨率视频训练,这样做不仅降低了成本,还确保了模型能够捕捉关键的动态特征。
在推理阶段,他们结合开源图像模型,通过文本生成图再生成视频,以获得更精细的视觉效果。
此外,团队采用了高效的并行训练方案,利用ColossalAI和系统级优化来提高计算资源利用率。
包括优化后的序列并行、Gradient Checkpointing、训练自动恢复机制等多种技术手段,这些措施的协同作用使得Open-Sora 2.0在高性能与低成本之间取得了最佳平衡。
高压缩比自编码器带来的未来在高效训练的基础上,Open-Sora还探索了高压缩比视频自编码器的应用,大幅降低推理成本。

通常,大多数视频模型采用4×8×8的自编码器,导致生成768px、5秒视频耗时很长。
为解决这一瓶颈,他们训练了一款高压缩比(4×32×32)的视频自编码器,将推理时间缩短至单卡3分钟以内,推理速度提升10倍。
高压缩比编码器在高效推理上展现出了显著优势,但它的训练数据需求和收敛难度较高。
为此,团队提出了蒸馏优化策略,提升AE(自编码器)特征空间的表达能力,并使用高质量模型作为初始化,减少训练所需的数据量和时间。
高压缩自编码器不仅在视频生成上取得了突破,它在未来低成本视频生成中是一个关键方向。
Open-Sora希望通过这一技术,引发社区更多关注与探索,共同推动视频生成技术的进步。
结语:加入Open-Sora 2.0,共同推动AI视频革命在科技不断发展的今天,Open-Sora 2.0的发布无疑是一个令人振奋的消息。
它的出现不仅代表着技术的进步,更是一种开源精神的实践。
我们正处在一个前所未有的时代,技术不再是少数人享有的特权,而是可以通过开源、共享资源惠及更多人。

Open-Sora 2.0以20万美元的成本成功训练出商业级视频生成模型,为视频生成领域树立了一个新的标杆。
它不仅打开了技术的门,也开启了更多思考的空间:如何以更少的资源创造更大的价值?
如何通过合作和分享实现技术的普及?
我们期待更多人加入这个开源项目,共同推动AI视频的革命。
这不仅仅是一款产品的发布,更是对未来的一种展望。
让我们一起,探索这片充满可能性的数字影像世界。
未来已来,机会就在眼前,让我们用行动去创造属于下一代的精彩故事。
