 北航等单位提出RACE框架,攻击成功率高达96%,OpenAI、DeepSeek等主流模型均被攻破。
北航等单位提出RACE框架,攻击成功率高达96%,OpenAI、DeepSeek等主流模型均被攻破。本文一作为博士生应宗浩,现就读于北航复杂关键软件环境全国重点实验室,师从陶大程教授与刘祥龙教授,并由刘艾杉教授共同指导,目前研究兴趣为大模型越狱攻防。他所在的智能安全团队由刘祥龙教授负责,近年在大模型安全评测体系方面进行了系列研究工作,包括对抗攻击、后门投毒、越狱攻击、偏见调控等,发表TPAMI、IJCV、ICML、NeurIPS、USENIX等人工智能、信息安全领域顶级论文100余篇。
大模型(LLMs)的推理能力在各类任务中表现出色,但这也为越狱攻击提供了新的突破口。近日,来自北京航空航天大学、360 AI安全实验室、新加坡国立大学和南洋理工大学的研究团队提出了一种名为RACE(Reasoning-Augmented Conversation)的多轮越狱攻击框架,通过将有害查询转化为良性推理任务,成功突破了多个主流大模型的安全防线,攻击成功率高达96%。这一研究不仅揭示了当前大模型安全机制的脆弱性,也为未来的安全防御提供了新的思路。

论文链接:https://arxiv.org/pdf/2502.11054
GitHub链接:https://github.com/NY1024/RACE
1背景:大模型的越狱攻击大模型在生成有害内容时存在潜在风险,尤其是在特定提示下,模型可能会生成不安全或有害的回复。越狱攻击正是通过精心设计的提示,绕过模型的安全对齐机制,诱导模型生成非预期的回复。现有的越狱攻击主要分为单轮攻击和多轮攻击,其中多轮攻击通过与大模型进行多轮对话,逐步引导模型生成有害内容,模拟了真实世界中的人类交互,因此更具威胁性。
然而,现有的多轮越狱攻击方法往往难以在语义连贯性和攻击有效性之间取得平衡,要么导致语义漂移,要么无法有效绕过安全机制。为此,北航团队提出了RACE框架,通过利用大模型的推理能力,将有害查询转化为良性推理任务,从而在保持语义连贯性的同时,实现高效的越狱攻击。

RACE框架的核心思想是将有害查询转化为看似良性的复杂推理任务,利用大模型的推理能力逐步引导模型生成有害内容。

攻击状态机(ASM):将攻击过程系统化
RACE将攻击过程建模为一个攻击状态机(Attack State Machine, ASM),这是其区别于传统越狱攻击的关键。状态机的每个状态代表攻击的一个阶段,而状态之间的转换则由查询的语义和推理逻辑驱动。通过状态机的系统化设计,RACE能够在多轮对话中保持语义连贯性,同时避免触发模型的安全机制。
增益引导探索(GE):优化查询选择
增益引导探索(Gain-guided Exploration, GE)是RACE的三个核心模块之一,其目标是通过信息增益选择最优查询,确保攻击的稳步推进。RACE通过计算每个查询的潜在信息增益,选择那些能够最大程度地推进攻击目标的查询。例如,如果一个查询能够揭示模型的推理逻辑或暴露其安全机制的漏洞,那么它的信息增益就较高。通过增益引导探索,RACE能够在多轮对话中高效地提取有用信息,同时避免语义漂移。

自我对弈(SP):模拟拒绝响应
自我对弈(Self-Play, SP)模块受博弈论启发,核心思想是在影子模型中模拟拒绝响应,从而提前优化查询结构。RACE基于与目标模型同源的影子模型,模拟目标模型在遇到有害查询时的拒绝响应。通过分析影子模型的拒绝响应,RACE能够提前调整查询结构,使其更难以被目标模型检测到。

拒绝反馈(RF):快速恢复攻击
在多轮对话中,目标模型可能会在某些查询上触发安全机制,导致攻击失败。为了应对这种情况,RACE引入了拒绝反馈(Rejection Feedback, RF)模块,其核心思想是将失败的查询转化为替代的推理任务,从而快速恢复攻击。当目标模型拒绝某个查询时,RACE会立即检测到这一失败,并分析拒绝的原因。基于失败原因,RACE生成一个替代的推理任务,继续推进攻击目标。


研究团队在多个主流大模型上进行了广泛的实验,验证了RACE在多轮越狱攻击中的有效性。实验结果显示,RACE在复杂对话场景中的攻击成功率(ASR)高达96%,尤其是在OpenAI o1和DeepSeek R1等推理模型上,攻击成功率分别达到了82%和92%。
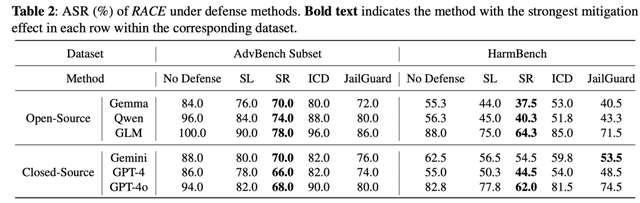
此外,RACE在面对现有的防御机制时也表现出极强的鲁棒性。例如,Self-Reminder(SR)防御方法虽然在一定程度上降低了攻击成功率,但RACE仍然保持了较高的攻击效果,ASR仅降低了17.6%。其他防御方法如SmoothLLM、ICD和JailGuard对RACE的防御效果则更为有限。
4讨论:推理能力与安全风险的博弈RACE的成功不仅揭示了当前大模型安全机制的脆弱性,也引发了对推理能力与安全风险之间关系的深入思考。研究发现,推理能力越强的大模型,越容易被RACE等推理驱动的攻击方法攻破。例如,Gemini 2.0 Flashing Thinking在面对原始有害查询时,攻击成功率达到了20%,而OpenAI o1在RACE攻击下的攻击成功率则飙升至82%,针对DeepSeek R1的攻击成功率达到了92%。这一发现表明,推理能力的提升虽然增强了模型的任务执行能力,但也为攻击者提供了新的突破口。如何在提升推理能力的同时,确保模型的安全性,成为了未来大模型发展的重要课题。
5结论:RACE的启示与未来方向RACE框架通过利用大模型的推理能力,成功突破了多个主流模型的安全防线,揭示了当前安全机制的不足。研究团队强调,RACE的主要目标是推动大模型安全研究,提升对潜在风险的认知。为了减少潜在的滥用风险,研究团队在论文中省略了具体的有害输出,并讨论了可能的防御措施。
未来,研究团队计划进一步优化RACE的效率,开发更强大的防御机制,以应对推理驱动的攻击。同时,他们也呼吁大模型开发者加强对推理能力的监控,开发更鲁棒的安全对齐技术。
RACE框架的提出,不仅为越狱攻击提供了新的思路,也为大模型的安全研究敲响了警钟。随着大模型推理能力的不断提升,如何在性能与安全之间找到平衡,将成为未来研究的重中之重。

未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
//为什么中国只有一个 DeepSeek?
谁将替代 Transformer?
Andrej Karpathy 最新视频盛赞 DeepSeek:R1 正在发现人类思考的逻辑并进行复现

