昨天的一个回复:

这是让很多的人困惑的事情,为啥一开P2P下载,家里的网络就卡成狗?

原因很简单——iN一直认为P2P是互联网上最蠢的技术之一,今天咱们就展开说说。
P2P技术,顾名思义,是点对点的技术,也就是说每个用户既是下载者也是上传者。这听起来好像很合理,大家互相分享资源,理论上可以提高下载速度。然而,如果知道了P2P的实质之后,你会觉得这种技术会蠢到不能再蠢了。
在P2P没有被提出之前,通常我们要在互联网下载一个文件是需要到Ftp服务器或者Web服务器上对这个文件进行请求的,然后在服务器上拉取我们需要的文件。在传输过程中传输速度受到的影响就是服务器到客户机本身的带宽限制,以及服务器的负载情况。
而P2P文件分享不同于传统的服务器-客户机模式。采取了一种叫做分布式哈希码表的形式将要分享的资源文件进行切片划分。

这些资源文件被切成一个个小的资源块。被不同的客户端全部或部分拥有。

最终客户端之间采取了缺什么块就向周围的客户端请求什么块的策略来让自己的资源逐渐完整,最终也就完成了P2P的资源下载。
这样一来就降低了单一服务器的负载、提高了下载速度。这就是P2P这个技术实质的精髓部分。
但是这种想法仅仅限于理想条件下。这个理想条件就是你自己的P2P客户端和成百上千的其他用户的P2P客户端有着良好的网络连接。可以这个网络连接可以支持P2P的所有客户端快速的交换数据块。
但实际上是这样吗?我们都知道并不是这样,拥有你的资源块的对端可能是在离你几公里外的一个小区,也可能是距离你几千公里之外的印度农民桌子上。那么你是更倾向的认为,对端在哪里呢?在你身边才好,可是事与愿违的是,开放网络的的对端往往是全球分布的,这就导致了你要去下载的P2P数据块往往是在距离你几百上千公里的距离上。
这意味着数据必须通过多条路由、跨多个网络传输,带来高延迟和低传输速率。尤其是跨越国家或地区时,不同的网络条件、不同的带宽水平都会让传输变得极为低效。
用户无法选择连接的节点,而是依赖于协议自动发现其他peer并建立连接。这种机制虽然保证了分布式网络的自主性但对于性能来说就不要过多的考虑了。
问题就在这里,当你的一条线路对端性能拉垮实际上你在路由器上处理和等待的时间并不明显,但……如果是开启P2P之后有可能会有几十甚至上百个连接都是很拉垮的存在。这就让路由器的系统需要“等待”了。等待的时间片积累起来,就会出现看着网络带宽没有变好、看着路由器的内存和CPU都没有占用率过大可是就是网速很卡的现象。
尤其是目前为了在并不稳定的网络中提高传输质量,P2P的节点之间更倾向于使用TCP协议进行连接。从好的一面来说是可以提高传输的稳定性。但从性能的角度上来看由于TCP是需要做握手连接,反而会在更差的线路中让性能进一步降低。虽然现在的一些类似于BT的软件开发出了μTP之类的传输协议,可以快速的在NAT网络中“打洞”,以便于实现类似于TCP的传输功能。但是这种方式又对路由器的NAT堆栈增加了负载。
所以说,如果不是P2P网络中的所有计算机都有极高的性能、极短的延迟,P2P网络中的交换机和路由器都有强悍的性能,那么P2P传输协议就是一个笑话,能用,但是会极其低效。
同时我们还有一个避不开的槛——AS(自治系统,或者叫自治域)。

我们都知道互联网并不是一家开的,而是众多企业和机构合力建成的。在互联网中存在某一组网络是某一个组织的资产这一事实。为了让自己的网络系统更加稳健高效运行,于是就有了自治系统的概念。例如联通AS4837、AS9929等等,自治系统内的数据传输是最快成本最低的。但自治域之间的传输不仅慢了一些而且有计费的可能性——也就是会产生成本。

所以,真正的互联网是这样的:

是一堆自治域网络之间的再次互联。
这又和P2P拉慢了自家的路由器有什么关系呢?
出于成本考虑,运营商会在AS路径选择上做优化,可以做到上行下行线路走不通的网络路径。对于上行线路有可能为了反应速度会走更快的链路,但对于下行线路会选择更便宜的链路。
这就导致原本基于UDP的μTP协议在打洞的时候会呈现出低效的问题——反复低效就又加大了路由器本身的负载。
所以,尽管P2P技术表面上看是去中心化、分布式资源共享的理想方案,但其在实际中的表现确实“蠢到不能再蠢”。这种技术虽然在某些特殊场景下仍然有用,但对于普通家庭用户来说,它带来的更多是网络卡顿、资源浪费和不良体验。究其原因不仅仅是P2P本身的设计是有硬伤的,同时也因为很多网络运营的骚操作。
对于下载这件事,iN自己的选择从来都不是P2P,如果非得搞一个P2P的连接来下,那么也不会让P2P的行为发生在iN自己家里的网络中。
怎么做?一般的情况下就是利用离线下载。具体说说:
现在是12:15分。

一般在P2P的下载站点中都包含种子的磁力链接

复制磁力链后我们可以把磁力链放到离线下载站中。

开始创建这个磁力链下载任务。
几乎瞬间这个磁力链所代表的任务就可以下载完成了。

所以,从拷贝磁力链到文件离线下载完成的时间我们看是不足一分钟的。
然后直接从离线网站下载:

4.87GB的文件预计4分半可以下载完毕。

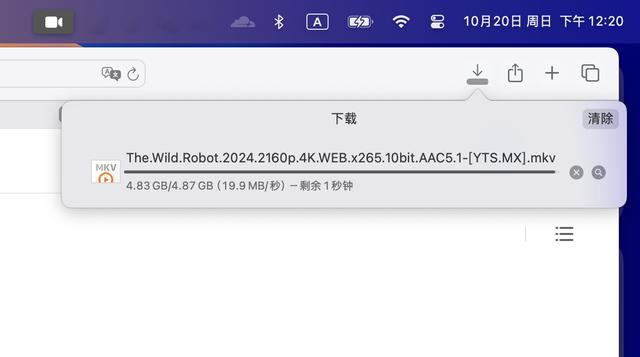

这样的操作,不到5分钟的时间,我们就可以下载完所有的内容,均下来,下载的速率基本上是每分钟1GB。
既不会让下载的时间变长,也并不会因为大量的P2P连接阻塞本地的路由器让家里的网变得一卡一卡的。
所以~~你学废了吗?
