万万没想到,2025 开年惊喜是 MiniMax 给的,就是海螺 AI 背后的中国大模型 AI 创业公司。
昨天刷信息流的时候,发现他们刚发布了两个新模型,一个是文本模型 MiniMax-Text-01,另一个是多模态模型 MiniMax-VL-01。统称为“MiniMax-01”模型。

今早我刷了下 X,发现 MiniMax-01 也被海外网友刷屏了。

有网友提到这是继 Deepseek 之后的另一家来自中国的「OpenAI 级」顶尖开源模型。
也有网友重点强调这是工业界首个基于 Lightning Attention 的基础模型,4M Tokens 上下文令人难以置信。

我原以为大模型就快要卷不动了——GPT-5 难产,Claude-4 没动静,Gemini2.0 跑去卷实时多模态了。
结果没想到,竟然蹲来了 MiniMax 发布的 400 万字上下文的新模型。
而且要我说,MiniMax-01 绝对是长文本处理的新王。
看这一张在 X 上被大家刷屏的图就知道了——

新模型 MiniMax-Text-01 不仅在主流 benchmark 上追平了 GPT-4o 和 Claude-3.5,而且与前阵子大火的 Gemini-2.0 和 Deepseek-V3 相比都不相上下。

但这还没完——
注意看第一张右边的图,从 256K 开始往后更长的输入,MiniMax-Text-01 的平均表现超越了国外商用旗舰模型 Gemini-1.5-Pro 和 Claude-3.5-Sonnet。

在 512k 长度的时候,谷歌最新的 Gemini-2.0-Flash 直接被 MiniMax-Text-01 给“按到地板”上了。
要知道,在长文本处理(上下文长度)问题上,Gemini 可是此前的绝对王者。
难道,Gemini 的不败神话终于要被 MiniMax 打破了?
我准备拿昨天刚在 arXiv 上更新的 10 篇 AI 论文,丢给 MiniMax-01 测测其实际表现。
打开 hailuoai.com,就能看到这个新模型已经上线了,可以直接用。
注意,昨天 arXiv 上刚更新的这 10 篇论文中,还包括了 MiniMax-01 这篇长达 68 页的论文 hh。每篇论文的篇幅不一,但整体上加起来,少说也有好几百 K 的 tokens 了。
我直接把它丢给 MiniMax-01——

总结论文这种问题就不问了,过于简单。
我选择直接问它“每篇论文都用了什么数据集”。这个信息不仅很细节,而且一般出现在论文的后半部分,甚至散落在不同的论文章节。

回答精简有效,再追问它每一个数据集规模多大,可以说关键细节是很到位的,还给出了“108 名护理院人员(437 名女性,80 名男性)”的细节。
,时长00:25
根据技术人的直觉,这背后一定有不小的技术突破。
翻了它的技术报告,我注意到了这么一张图——
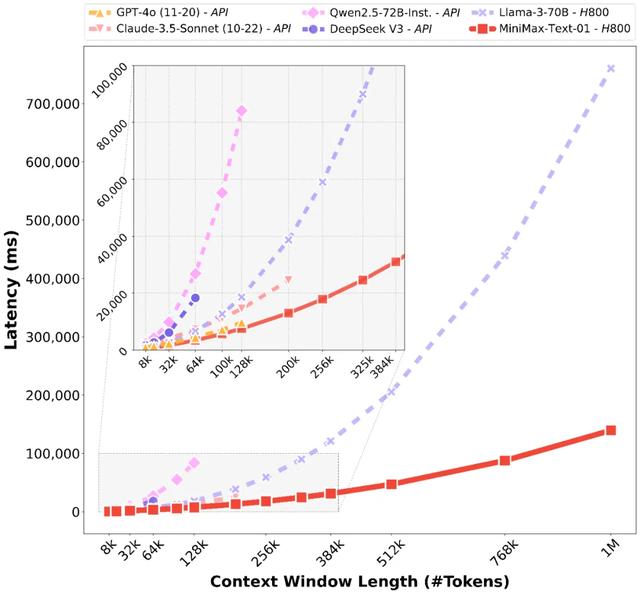
此前的模型延迟,随着上下文长度的增加,增长都是指数型的,包括 GPT-4o、Claude-3.5-Sonnet、Deepseek v3 等,但唯独这次 MiniMax 发布的新模型,竟然是近乎线性的增长曲线。
而这个近乎线性的曲线形状,其实就是这次 MiniMax 新王登基的背后黑科技——线性注意力!

这个是五年前就被学术界广为研究的黑科技。这次终于实现了工业界落地,而且是业界首次落地到了 4560 亿参数规模且坐拥大量 C 端用户的大模型产品里。
线性注意力(Linear Attention)首先给不懂/忘掉 Transformer 技术原理的小伙伴科普一下,在 Transformer 前向计算中,计算量最大的环节之一便是“双向注意力”的计算。
双向注意力的计算复杂度是:
这就意味着,计算量随输入长度 N 的增长曲线是指数级。
而这次 MiniMax 则使用了线性注意力机制,线性注意力通过“右乘积核技巧”魔改后,计算复杂度便变成了
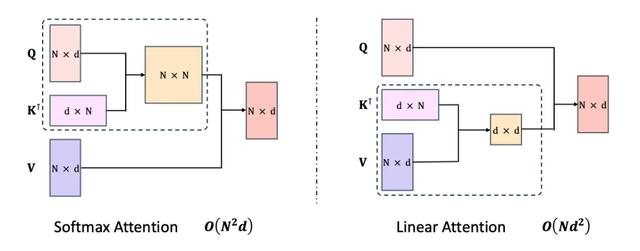
这就意味着,计算量随输入长度 N 的增长曲线变成了线性。
虽然看起来 d 维度成了指数级,但在模型推理阶段,d 就是个常数(一般几百到几千),与 N 比起来小太多了,所以平方一下也不会带来多大的计算量负担。
看到这儿,你可能会想。
这么简单的道理,为啥过了五年才首次被 MiniMax 真正落地工业界产品呢?
这就不得不提另一个陷阱了——
在经典的线性注意力计算过程中,需要有一个计算累积和(cumsum)的操作,这个计算过程是递归的,无法借助 GPU 的优势进行并行计算,因此实际工程实现后,大家会发现,线性注意力机制并没有给大模型计算速度带来实质性的提升。
而 MiniMax 团队牛逼的点,就在于提出了闪电注意力机制,终于把这个恶心的 cumsum 操作,成功干掉了,引爆了线性注意力恐怖的计算效率。
闪电注意力(Lightning Attention)为了解决 cumsum 操作带来的并行化难题,MiniMax 团队将注意力计算划分为块内(intra-block)和块间(inter-block)计算,并巧妙地利用左乘积和右乘积的特性,避免了直接的 cumsum 操作。
具体来说,块内计算可以使用左乘积,而块间计算使用右乘积,这样可以将 cumsum 操作的影响限制在较小的块内,从而在一定程度上实现了并行计算,提高了计算效率。
而这些,也仅仅是理论层面的突破,在线性注意力实际落地的过程中,还会遭遇大量的细节挑战。
根据笔者消息,MiniMax 为了把这事儿落地,几乎重构了他们的训练和推理系统,包括做了更高效的 MoE All-to-all 的通讯优化,更长的序列优化,甚至线性注意力层的底层 Kernel 的高效实现等。
通过这一系列组合的算法、架构、工程联合优化,才炼成了 MiniMax-Text-01 这个 456B 参数,80 层深,激活参数 45.9B,32 个 Experts 构成的长文本处理怪兽。
而且有个细节很重要。
MiniMax-text-01 模型的总参数量控制在了 500B 以内,这样仅用 8x80GB 显存的 GPU 单机,辅助 8-bit 量化,便能驱动起长达 1000k 的输入序列推理了。
这使得具备优异长文本处理性能的模型,也能在单机上部署了,这对于把大模型在长输入情况下的推理成本打下来有非常强的商业意义。
我想,这也是 MiniMax-text-01 敢直接定价“输入 1 元/M Tokens”的原因之一。

这个价格,我只能说太香了。
价格仅为 DeepSeek v3 的一半,最大输入长度却是其 15.6 倍,模型表现还更强。
贴一下 API 传送门:
https://www.minimaxi.com/platform
有实力的小伙伴,还可以选择自己部署,附开源传送门:
Github:
https://github.com/MiniMax-AI/MiniMax-01
Hugging Face:
https://huggingface.co/MiniMaxAI
看到这儿,如果你恰好是个在构建 Agent 应用的开发者,我知道你一定迫不及待要去试试了。
因为,记忆能力是构建 Agent 系统的关键技术问题之一。
在 Agent 任务执行过程中,不仅要记忆任务节点的上下文内容,还常常要记忆任务相关的“全局信息”甚至跨任务的“长期记忆”。稍有不慎,Agent 遗忘了重要记忆细节,便会导致任务执行失败或者执行质量大打折扣。
此前,Agent 开发者常常会遇到的困境便是——
便宜的 API 往往记忆能力不行,甚至输入长度就不够;而输入长度和记忆能力够的,往往贵的不行。
所以我常说,你们别喊 2025 年是 Agent 元年了,到底能不能成,一方面看能不能蹲到一个白菜价“思维模型”出现;另一方面看能不能蹲到一个超强记忆能力的白菜价“执行层模型”出现。
如今,在 MiniMax-text-01 的加持下,我觉得后半个问题可能有望解决了。
最后,很想感慨一下,没想到两年过去了,大模型的“过期速度”依然是以月为单位的。
不太一样的是:
以前,我们常吐槽中国的大模型厂商只会追赶、不做创新;
如今,大模型技术创新的消息似乎更多来自中国大模型厂商了。
