当我开始做这件事时,那是一个下雪天。我看到了 IBM WatsonX Python SDK,并意识到我需要连接我的 Gen AI 模型 (LLM),以便从 Slack 发送我的上下文增强提示。为什么不为 Apache NiFi 2.0.0 创建一个 Python 处理器?我想这并不难。这很容易!

IBM WatsonXAI 有大量强大的基础模型可供您选择,只是不要选择那些 v1 模型,因为它们将在几个月内被删除。
GitHub,IBM/watsonxdata-python-sdk:用于 wastonx.data Python SDK。
在我们选择了一个模型后,我在 WatsonX 的 Prompt Lab 中对其进行了测试。然后我把它移植到一个简单的 Python 程序中。一旦成功,我就开始添加属性和转换方法等功能。就是这样。
源代码这是源代码的链接。
现在,我们可以将新的 LLM 调用处理器放入流中,并将其用作任何其他内置处理器。例如,Python API 要求 Python 3.9+ 在托管 NiFi 的计算机上可用。
包级依赖项添加到requirements.txt。
Python 处理器的基本格式
您需要从库中导入各种内容。然后,设置您的类 .您需要包含类定义,其中包括 NiFi 、 、 a 和 一些 .nifiapiCallWatsonXAIJavaProcessDetailsversiondependenciesdescriptiontags
class ProcessorDetails: version = '0.0.1-SNAPSHOT', dependencies = ['pandas']定义处理器的所有属性
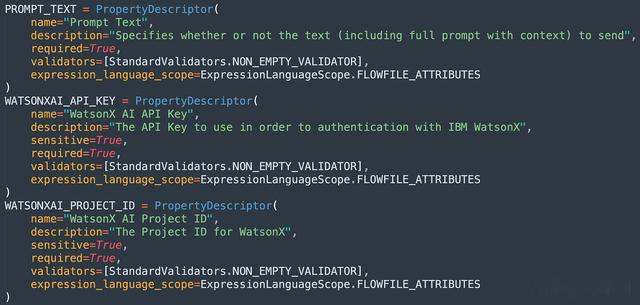
您需要为包含 、 、 等内容的每个属性设置 s。PropertyDescriptornamedescriptionrequiredvalidatorsexpression_language_scope
Transform Main 方法
在这里,我们包括所需的导入。您可以通过 访问属性。然后,您可以设置输出的属性,如 所示。然后,我们设置流文件输出。最后,对于所有指南来说,哪个指南是 。您应该添加一些内容来处理错误。我需要补充一下。context.getPropertyattributescontentsrelationshipsuccess
如果需要,请重新部署、调试或修复某些内容。
虽然您可以在 NiFi 停止时删除整个目录,但这样做可能会导致 NiFi 下次启动所需的时间要长得多,因为它必须从 PyPI 获取所有扩展的依赖项,并扩展所有 Java 扩展的 NAR 文件。work
请参阅:NiFi Python 开发人员指南因此,要部署它,我们只需要将 Python 文件复制到 nifi-2.0.0/python/extensions 目录,并可能重新启动您的 NiFi 服务器。我会开始使用本地 GitHub 构建或 Docker 在您的笔记本电脑上进行本地开发。
现在我们已经编写了一个处理器,让我们在实时流数据管道应用程序中使用它。
应用实例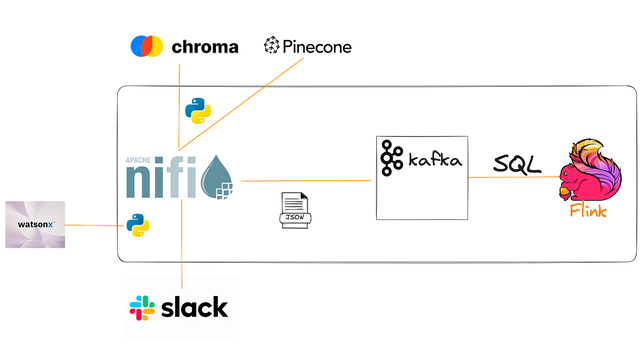
基于我们之前接收 Slack 消息的应用程序,我们将获取这些 Slack 查询,将它们发送到 PineCone 或 Chroma 向量数据库,并获取该上下文并将其与我们对 IBM 的 WatsonX AI REST API for Generative AI (LLM) 的调用一起发送。
您可以在此处找到之前的详细信息:
使用生成式 AI 构建实时 Slackbot具有 Chroma Vector DB 和 Apache NiFi 的无代码生成式 AI 管道使用 Apache NiFi 流式处理 LLM (HuggingFace)使用实时上下文增强和丰富 LLMNiFi 流Listen HTTP:在端口 9518/slack 上;NiFi 是一个通用的 REST 端点QueryRecord:JSON 清理SplitJSON: $.*EvalJSONPath:$.inputs 的输出属性QueryChroma: 使用 ONNX 模型在端口 9776 上调用服务器,导出 25 行QueryRecord: JSON->JSON;限制 1SplitRecord: JSON->JSON;成 1 行EvalJSONPath: 从中导出上下文 $.documentReplaceText: 将上下文设置为新的流文件UpdateAttribute: 更新输入CallWatsonX:我们调用 IBM 的 Python 处理器SplitRecord: 1 条记录,JSON -> JSONEvalJSONPath: 添加属性AttributesToJSON: 从属性创建新的 Flow 文件QueryRecord:验证 JSONUpdateRecord:添加生成的文本、输入、ts、UUIDKafka 路径,:将结果发送到 Kafka。PublishKafkaRecord_2_6Kafka 路径:如果 Apache Kafka 发送失败,请重试。RetryFlowFile松弛路径, :拆分为 1 条记录进行显示。SplitRecord松弛路径,:拉出要显示的字段。EvaluateJSONPathSlack 路径, :将格式化的消息发送到 #chat 群组。PutSlack这是一个利用 ChromaDB 的成熟检索增强生成 (RAG) 应用程序。(NiFi 流也可以使用松果。接下来,我正在开发 Milvus、SOLR 和 OpenSearch。

享受将 Python 代码添加到分布式 NiFi 应用程序是多么容易。
原文标题:Building a Generative AI Processor in Python
原文链接:https://dzone.com/articles/building-a-generative-ai-processor-in-python
作者:Tim Spann
编译:LCR
