12月21日,OpenAI 发布了具有超强推理能力的大模型o3,引起了业内对大模型推理能力的广泛讨论和深入研究。o3的发布也带来了三个引人深思的问题:市面上主流大模型的推理能力究竟如何?在真实应用场景中,是否总是需要具有极强推理能力的模型?在实际应用中,如何根据应用需求选择合适参数量的大模型而避免“用大炮打蚊子”,以获得最高性价比?
中国联通借鉴动物智能演化规律,结合大模型实际落地应用实践,在业界首次提出大模型能力边界量化基准,定量分析主流语言大模型能力边界,详细刻画模型参数量、模型能力与应用场景之间的关系,为语言大模型的应用选型提供理论和经验指导,将有助于降低语言大模型应用门槛,促进大模型普惠化。相关研究成果以<What is the Best Model? Application-Driven Evaluation for Large Language Models>为题发表在自然语言处理权威会议NLPCC2024上,相应的评估基准已向业界开源,获得业界广泛认可。


论文链接:https://arxiv.org/abs/2406.10307
评估基准:https://github.com/UnicomAI/UnicomBenchmark/tree/main/A-Eval
借鉴动物智能演化规律
一般来说,动物的脑神经元越多,脑容量越大,智力水平就越高。另外,不同智力水平的动物擅长的任务种类和难度也各不相同,即使小如乌鸦的大脑,也可以完成“乌鸦喝水”这样的任务。

动物智能演化规律
相似地,在语言大模型中,扩展法则指出模型参数量越大,模型能力越强,相应的算法消耗和应用成本也越高。然而这样的定性分析是不够的,大模型能力边界定量刻画的缺乏,导致在实际应用中经常出现“高射炮打蚊子”的情况。因此对大模型能力边界的定量刻画是必要且紧迫的。
构建大模型能力评估基准
中国联通研究团队从实际应用场景维度出发,对语言大模型主要能力进行归纳、梳理和总结,建立了应用驱动的大语言模型能力评估基准。该评估基准包括文本生成、理解、关键信息抽取、逻辑推理、任务规划等5大类能力,又细分为27类子能力。

语言大模型主要能力
针对27类子能力,中国联通研究团队构建了相应的评测任务和由易、中、难三个难度等级的678个问答对构成的评估数据集。为避免数据泄露问题,所有数据均由专家团队人工编写。

应用驱动的语言大模型能力评估数据集
量化主流大模型能力边界
团队设计了专家评估和基于大模型的自动化评估方法,对同一家族8个不同规模的模型(0.5B, 1.8B, 4B, 7B, 14B, 32B, 72B, 110B)进行测试和评估,避免模型架构、训练数据等非模型参数量因素对评估结果产生干扰,得到了不同参数量模型在各种任务上的可靠的评估结果。从下图的评测结果可以看出,不同参数量模型能力不同,模型参数量越大,模型能力越强,对于复杂任务需要使用大参数量模型。
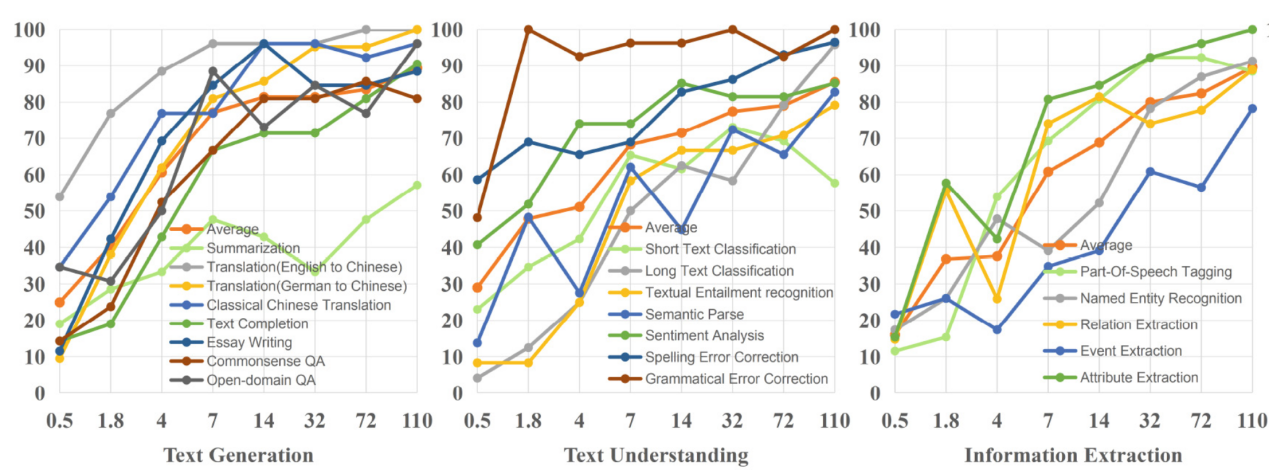

不同参数量模型在各类任务中的准确率
依据能力要求确定模型参数量
根据语言大模型能力边界测评结果,团队提出了一种简单可行的模型选型方法,指导模型落地应用时的参数选型。总的来说,针对不同任务,任务难度越高要求参数越大;针对同一任务,参数越大模型性能越好。具体地,可依据某项任务对模型性能的底线要求来选择相应参数的规模,以图中任务为例:在用户需求准确率为80%的前提下,对于拼写错误校正任务,14B以上模型可获90分以上;对于逻辑错误检测任务,110B以上模型可达90分以上;如果同时应用多个任务,先为每个任务选择合适的模型,再选择其中参数量最大的模型即可。选型过程中不需要用户对大模型有深入了解,这将降低用户选择使用大模型的门槛,促进大模型普惠化。
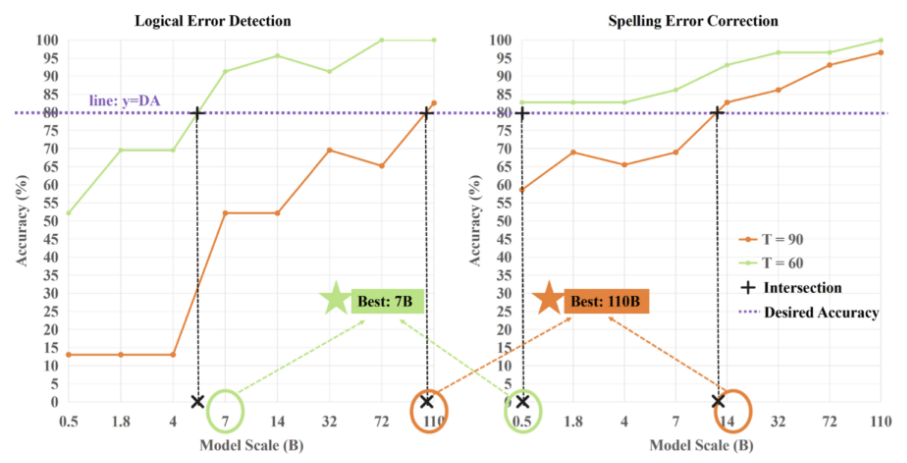
模型参数量选择方法示例
探索设计模型选型使用“说明书”
在元景大模型应用落地中,中国联通基于上述评估基准,打造评估工具,量化1B、7B、13B、34B和70B等元景基础大模型的能力边界,并分别将其用于违规短信分类、投诉工单分类、客服助手、渔业知识问答、元景App问答等场景,提炼“模型参数量-模型能力-应用场景”关联关系(如下图),作为大模型使用“说明书”,集成到元景MaaS平台,为开发者提供选模型指引。

模型参数量-能力-场景的对应关系图
模型参数量-能力-场景的对应关系图
接下来,中国联通将继续推进模型边界量化机理研究,扩展和深化“模型参数量-模型能力-应用场景”关联关系,协同业界持续扩展模型能力边界,完善和增强大模型的“记忆-推理-规划-创造-成长-价值观”能力链条,打造自主可控、模态丰富、性能先进、高性价比、安全可信的基础大模型,支撑千行百业场景应用,加速大模型普惠化。
