
文|大核有料
编辑|大核有料
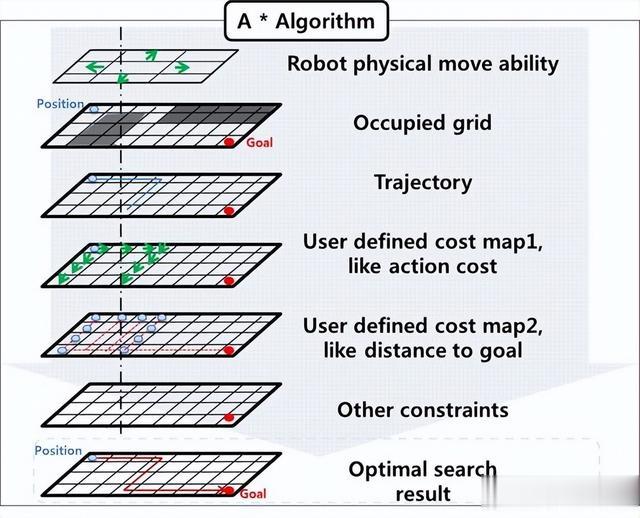
路径规划是计算机科学和人工智能领域的一个重要的研究内容,其主要思路是根据能耗、路程、时间等性能指标,在具有障碍物的环境下,规划出一条从起始点到目标点的最优路径。
在以往的研究中,通常把移动机器人的路径规划分为两部分:全局路径规划和局部路径规划。
针对全局的路径规划算法有:蚁群算法、粒子种群算法、BFS算法、Dijkstra算法及A∗算法,针对局部的路径算法有人工势场法(APF)、动态窗口法(DWA)、RRT算法、PRM算法等。
相较于其他算法而言,A*算法优点在于对环境反应迅速,搜索路径直接,是一种直接的搜索算法,因此被广泛应用于路径规划问题,但是其缺点是实时性差,每一节点计算量大、运算时间长,路径代价大。
但在以往的实际应用中发现,有关A*算法的研究都集中于单目标点的路径规划,并未对多个目标点的规划进行研究,这对限定于餐厅场景下的移动机器人路径规划仍有制约。
针对受限的餐厅情景下移动机器人多目标点规划的应用问题,如何在A*算法的基础上采用人工势场法对多个目标点的位置进行快速排序,实现多个目标点遍历呢?
在结合场景地图的优化,设计了融合APF与A*的M_A*_Goal算法对限定于餐厅情境下的实际地图和障碍物的多个目标点进行寻路寻路在,又该怎样较好地克服了采用单一算法计算量大、效率不高的问题呢?
«——【·算法理论基础·】——»
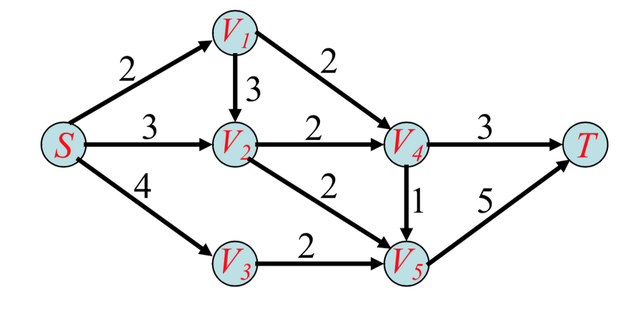
问题描述:多目标点路径规划问题的目标是为餐厅移动机器人规划出一条能够经过所有目标点且不重复的路径。
假设在一次送餐过程中含有n个目标点,则餐厅移动机器人会产生n(n-1)/2条路径。
为了满足移动机器人行走路径最短的要求,机器人需要从n(n-1)/2条路线中选择出一条经过所有点的最短路径。
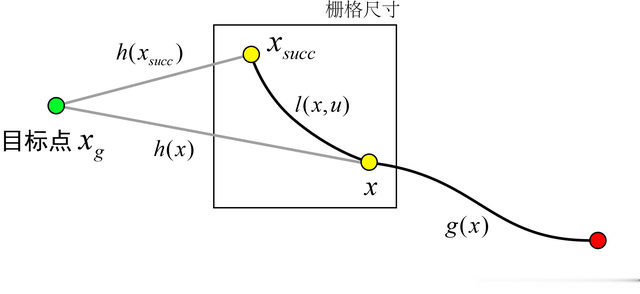
A*算法:A*算法(A-staralgorithm)是一种常用于寻找图形网络中最短路径的启发式搜索算法。
其基本原理是通过评估每个节点的代价函数来选择下一个要探索的节点,代价函数由两部分组成:启发式函数和实际代价。
启发式函数用于估计从当前节点到目标节点的代价,而实际代价是从起始节点到当前节点的实际代价。
通过综合考虑这两个因素,A*算法选择具有最小总代价的节点进行探索,直到找到目标节点或者无法继续探索为止。
其函数表达式如下:
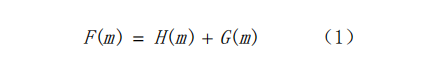
式中:F(m)表示的是从当前节点m到目标点的估计代价函数;G(m)表示从出发点到当前节点n的实际代价;H(m)表示从当前节点m到目标点的估算代价。
从函数表达式可以看出,当G(m)>>H(m),则F(m)≈G(m)。
这时,A*算法就接近于Dijkstra算法,搜索的节点会增多,效率会降低;当G(m)<<H(m),此时A*算法接近于BFS算法,路径规划的速度会变快,但是会出现局部最优解。
因此A*算法的性能好坏,取决于启发式函数H(m)的选择,常用的启发式函数有两种:欧几里德距离和曼哈顿距离。
设起点坐标为(sx,sy),终点坐标为(gx,gy),则用欧几里德距离表示为:
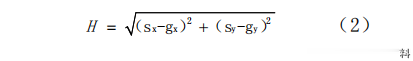
曼哈顿距离为:
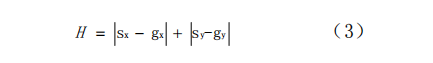
考虑到欧几里德的距离计算精度高于曼哈顿距离,规划出最优路径的几率更大。所以,这里选择欧几里德距离作为启发函数。
A*_Goal:算法A*算法常用于单目标点的路径规划,无论是在单目标点还是多目标点路径规划中,其搜索效率是一个很大的性能指标,所以在实现A*算法的多目标点路径规划时,必须要考虑到搜索多个目标点的执行效率。
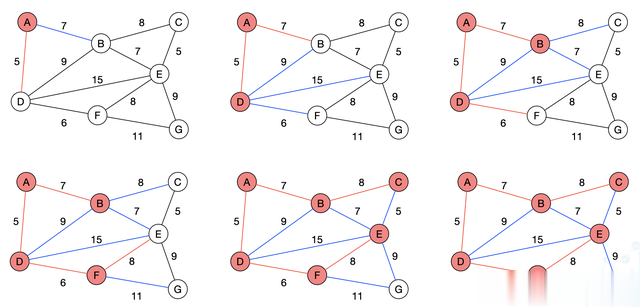
为了实现多个目标点的遍历,在A*算法开始前,先给定一个集合,用于存放目标点集;
其次A*算法在搜索时,执行一个循环:每次以集合内第一个目标节点为起始节点进行搜索,直到目标节点全部搜索完毕,这个算法被称为A*_Goal。
APF算法:人工势场法(ArtificialPotentialFieldmethod,APF)通过将机器人所在的环境建模为虚拟的势场来引导机器人在环境中移动。
该方法假设机器人受到引力和斥力的作用:引力使机器人向目标点方向移动,而斥力使机器人远离障碍物。
引力和斥力的合力引导机器人沿着势能下降的方向移动,直到到达目标点。
目标点对移动机器人所形成的引力势能随着机器人与目标点之间的距离而变化,人工势场中引力势能的大小与机器人与目标点之间距离的平方成正比,距离越远,目标点所产生的引力势能越大。
引力势场函数表示如下:
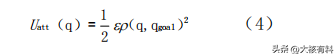
其中:Uatt(q)为目标点对机器人产生的引力场;ε为大于0的引力势场增益函数;ρ(q,qgoal)2为机器人当前位置与目标点之间的欧几里得距离。
在构建的势场中,机器人与障碍物之间的距离越远,所受斥力越小,反之越大。斥力势场函数表示如式5所示:
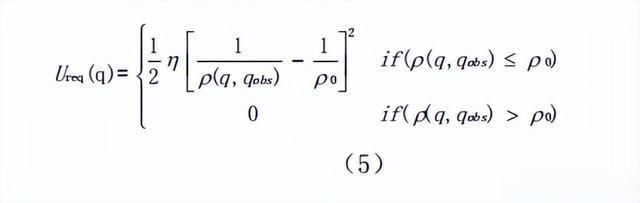
其中:Urep(q)是障碍物对机器人当前位置所形成的斥力势场;η为斥力势场增益函数;(q,qobs)为障碍物与机器人当前位置的欧几里得距离,ρ0为障碍物的影响半径,表示斥力势场的有效作用距离。
当机器人与障碍物之间的相对距离ρ(q,qobs)大于ρ0时,障碍物对机器人不再产生斥力作用。
当机器人当前所处位置周围有m个障碍物时,机器人当前所处位置的势能为:
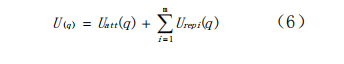
«——【·融合APF与A*的M_A*_Goal算法·】——»
M_A*_Goal算法思想:该算法首先需要获得若干目标点的最佳遍历顺序,而从A*_Goal算法可以看出,给定的目标点集并不是最佳的顺序。
因为在给定的目标点集合中,目标点的位置是不确定的,可近可远,而A*_Goal算法在执行循环的时候并未考虑到顺序因素。
因此需要获得一条能够遍历所有目标点且路径代价最小的路径,这与TSP算法解决问题思路类似。
为此引入人工势场法,提出了融合APF与A*的M_A*_Goal算法来解决,通过人工势场法将引力和斥力叠加起来,可以得到机器人在环境中的总势场。
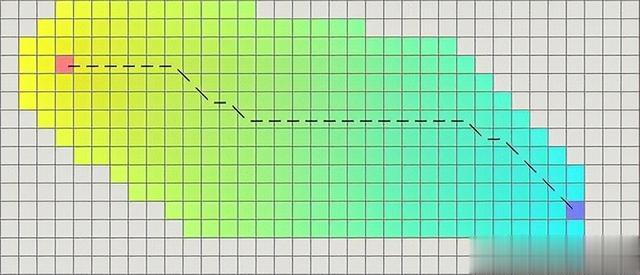
机器人根据总势场的梯度方向移动,以达到目标并避开障碍物,采用其总势场的值作为参考,用于将目标点集进行排序,确定其最佳遍历顺序,从而引导A*算法路径搜索的方向。
这样可以使A*算法在搜索时方向性更明确,从而提升其搜索效率。其对应的适应度函数表达式如(7)所示:
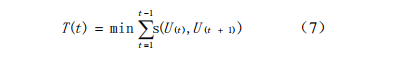
其中,T表示目标点的顺序,t表示目标点个数,其中的每个目标点在规划结束之后能且只能出现一次,s(i,j)为两个目标点之间的最小值,U(t)为式(6)所用的计算方式。
M_A*_Goal:算法框架M_A*_Goal算法由两部分组成,第一部分是对目标点集进行排序,得出最佳的遍历顺序。
第二部分是全局路径规划,利用第一部分得出的最佳遍历顺序应用到A*算法进行全局路径规划,算法的整体流程图1所示:
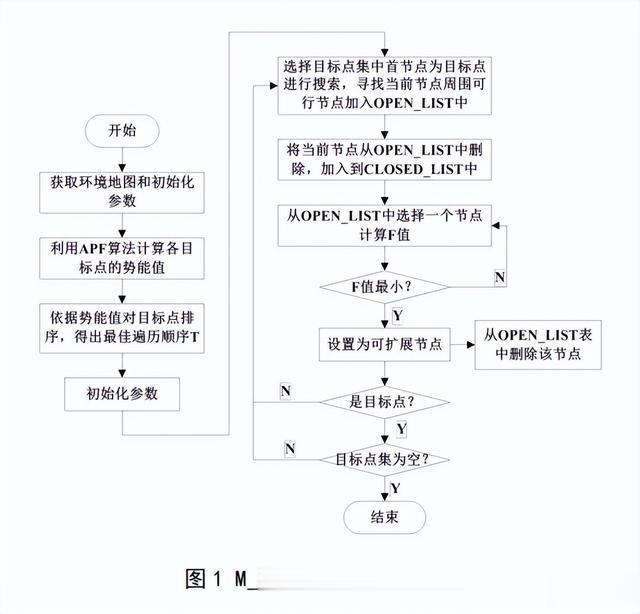
M_A*_Goal:算法描述:
(1)确定起始点和多个目标点,并将起始点作为当前节点,初始化目标点集合;
(2)用APF算法计算每个目标点的势能值,对势能值进行排序,使用TSP算法确定目标点的最佳遍历顺序;
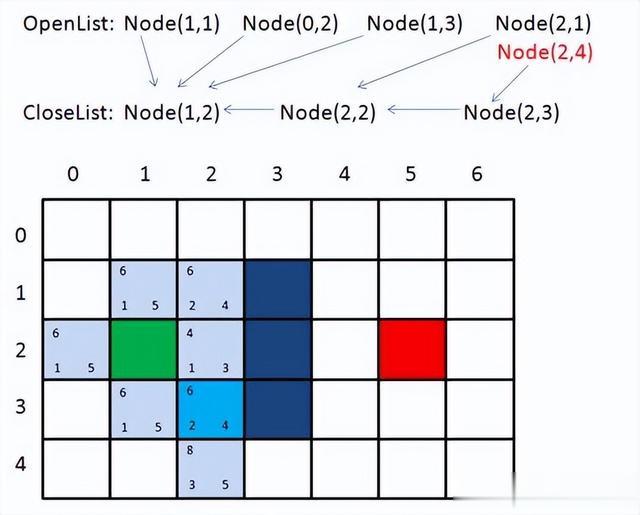
(3)创建一个开放列表(openlist)和一个关闭列表(closedlist),将起点添加到开放列表,并将其代价函数F值设置为0;
(4)从开放列表中选择代价函数F值最小的节点,将其移动到关闭列表。判断该点是否为目标点,若是,则当前路径搜索结束;若不是,则进行步骤(5);
(5)对该节点的邻居进行评估:如果邻居节点不在开放列表或关闭列表中,则将其添加到开放列表,并计算其代价函数F值;
(6)如果邻居节点已经在开放列表中,更新其代价函数F值,如果新的F值更小,则选取该节点进行扩展,并从openlist中删除该点,加入到closedlist表中;
(7)计算邻居节点到目标节点的估算代价H值,并更新其F值为F(m)=G(m)+H(m);
(8)重复步骤(4)~(7),直到找到所有目标节点或开放列表为空,如果开放列表为空,表示没有找到目标节点,搜索失败。
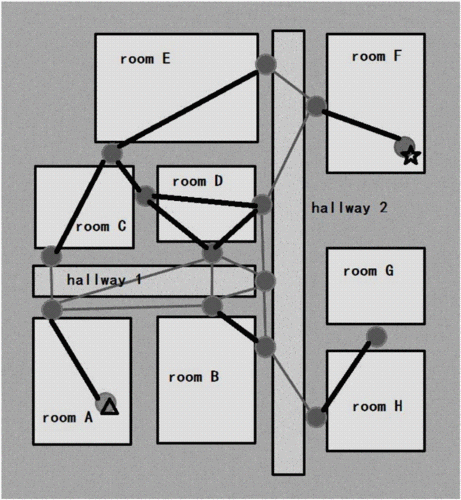
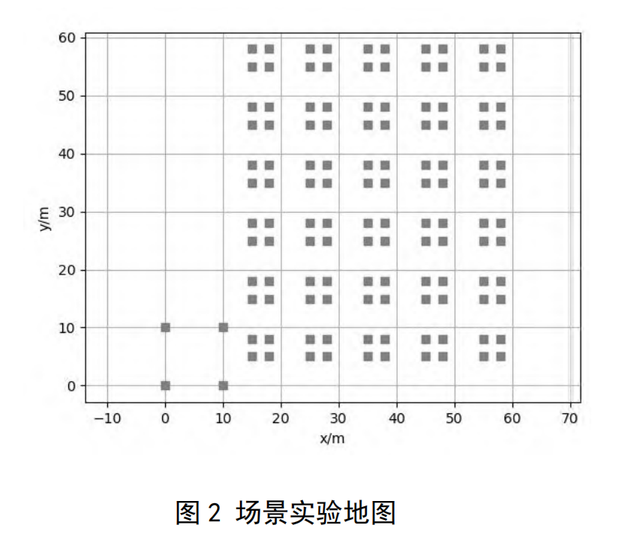
场景地图优化建立:移动机器人路径规划中,地图的表示方法有特征地图、拓扑地图、外观地图、场图和栅格地图等。
文中使用的表示方法是栅格地图,障碍物和起点终点等可以表示为一个或者多个栅格。

假设在一个大厅餐厅内,送餐移动机器人的任务是,厨房出菜口是开始出发点,不指定顺序的给若干个餐桌送餐,最后回到厨房出菜口。
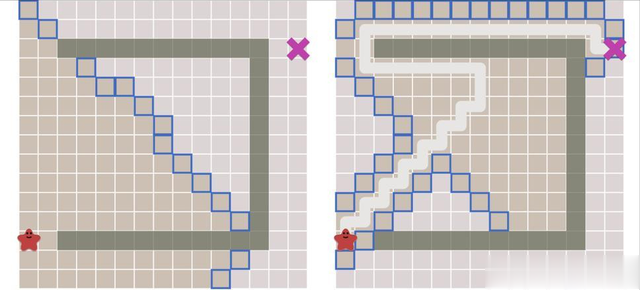
首先对餐厅地图进行建模,餐厅结构进行简化后如图2所示,地图左下角为餐厅厨房的出菜区域,其余的灰色地方作为餐桌,同时也充当障碍物的作用。
本质上的地图是一个二维矩阵,矩阵中有0和1两个元素,用0代表自由空间的可行节点,用1代表障碍物不可行节点,地图上每个节点用[x,y。c,p]来进行表示,其中,x,y表示的某一个点的位置,c表示的是通行的代价,p代表的是某一个点的父节点;
自由的可通行的代价为1,障碍物空间的可通行代价为∞。为了简化表示用(x,y)来表示目标点和起始点。

«——【·仿真实验·】——»
为验证本文所提出M_A*_Goal融合算法的有效性,仿真实验对比了M_A*_Goal融合算法与未融合A*_Goal算法的规划结果。
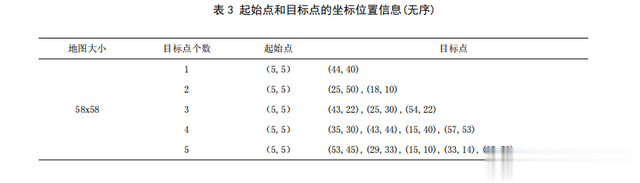
其中,实验环境中起始点和目标点的坐标位置信息如表1和表3所示(目标点位置根据地图设置随机生成)。
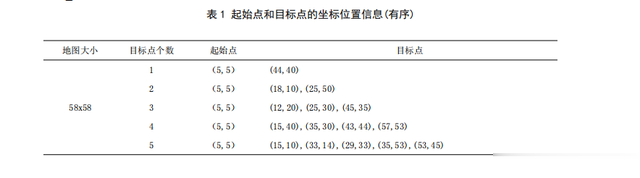
根据表1和表3的数据信息,对比实验以规划区域大小、目标点个数、起始点和目标点坐标位置相同的基础上,目标点位置分为有序和无序(以横坐标来区分)。
仿真实验得到规划结果如表2和表4所示。
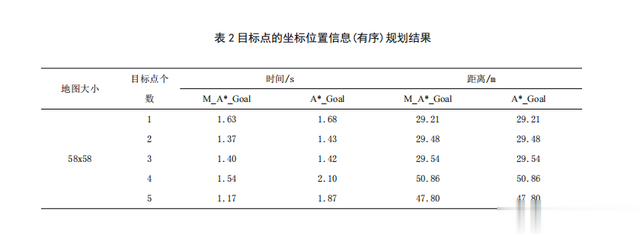
由表1和表2可知,在目标点顺序有序的情况下,A*_Goal算法和M_A*_Goal算法在在路径代价上是保持一致,没有误差,因为A*_Goal算法的搜索顺序并未发生变化,所以他们的搜索路径并没有变化;
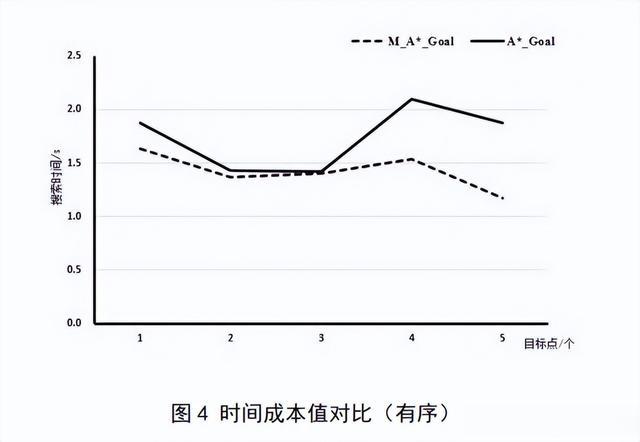
总体上从搜索的时间来看,随着目标点个数的增多,M_A*_Goal算法的搜索时间很明显要比A*_Goal算法的搜索时间要快,其中在已做实验下,最多要快0.7s。
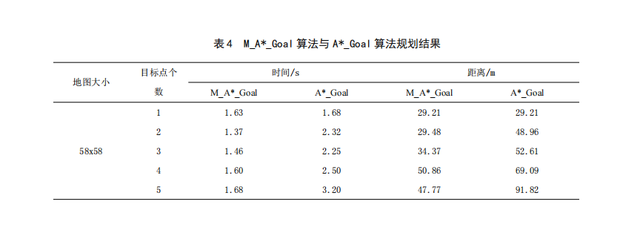
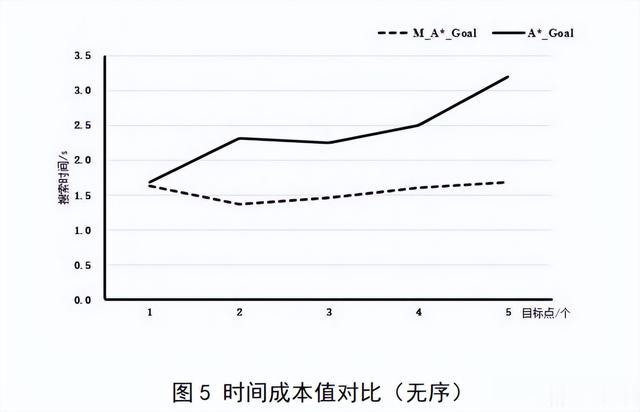
由表3和表4可知,在目标点无序的情况下,只有一个目标点的时候,两种算法仅在时间上有差距;
但是随着目标点的个数增多,M_A*_Goal算法的时间成本比A*_Goal算法提高了47.5%左右,在有五个目标点的时候,M_A*_Goal算法比A*_Goal算法快1.52s;
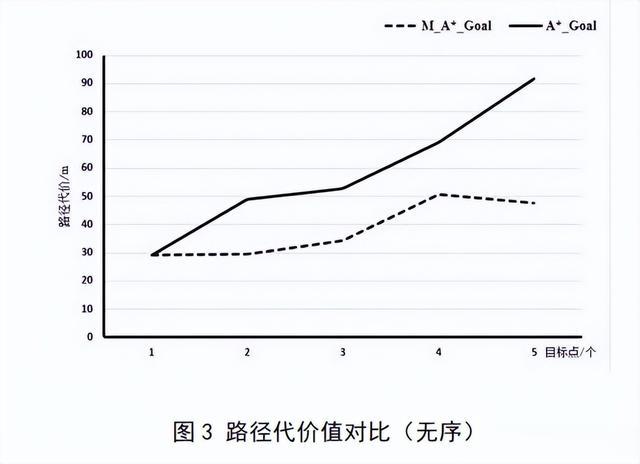
在路径代价上也有很明显的差距,其中路径缩短最高接近48%。
为进一步验证本文所提出方法的先进性,将本文方法与其他移动机器人多目标点路径规划算法进行对比实验,对比实验是在规划区域大小相同的情况下进行的。
随机生成6个目标点进行实验,分别是(54,33),(25,44),(19,18),(24,35),(38,40),(55,54)分别以一种无人巡航船遍历多目标点的路径规划算法研究作为方法。
基于改进人工势场法的多目标点路径规划作为方法2的规划方法作为实验的对比方法。
对比本文方法与两种对比方法所规划的路径,所得规划结果如表5所示。

分析可知,在3中不同的规划方法中,文中所提出方法的搜索时间与其他两种对比方法相比,在时间成本上更具优势,规划的路径代价与其他两种方法也更短。
由以上三组对比实验可知,本文提出的基于A*算法与APF算法相结合的多目标点路径规划方法,可以规划出一条只遍历一次所有目标点的路径。

这一过程成功的降低了算法规划路径的搜索时间,缩短了规划路径的长度,验证了本文算法的有效性和先进性。
算法性能分析:在第一组和第二组实验中,选取了1-5个目标点分别进行实验,将路径代价和搜索时间成本作为对比分析的指标,对比结果如下:
路径代价:对A*_Goal算法和M_A*_Goal算法的路径规划距离成本性能进行对比分析。
时间成本差值:对A*_Goal算法和M_A*_Goal算法的路径规划时间性能进行对比分析。
A*_Goal算法和M_A*_Goal算法对比分析,M_A*_Goal算法加入了APF+TSP算法对目标点进行排序,作为算法搜索的初始条件,降低了A*_Goal算法在多个目标点进行搜索时,对多个目标点之间的栅格重复搜索的概率,对同一个栅格进行多次搜索的概率,进一步提高了搜索的距离和速度。
由此可知,在餐厅情景多个目标点的实验环境下,M_A*_Goal算法能够有效缩短路径规划时间,降低距离成本。
«——【·结语·】——»
文章针对智能餐厅情景下移动机器人路径规划存在规划效率低下的问题,提出一种A*算法与APF算法相结合的多目标点路径规划方法M_A*_Goal,解决了移动机器人在路径规划时的时间性能低和路径代价大的问题。
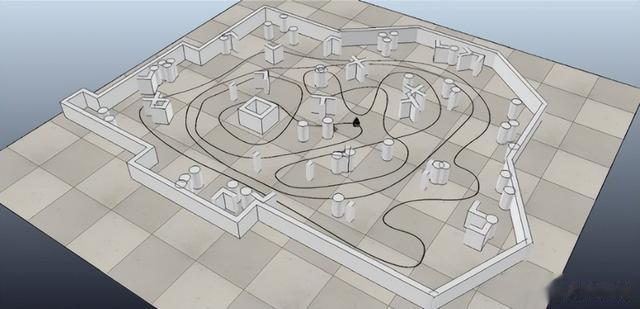
以A*算法为基础,给定一个集合,用于存放目标点集,实现了移动机器人在餐厅情景下用A*算法遍历多个目标点的路径规划;
针对A*算法遍历多个目标点规划时间长、路径代价的问题,引入了APF算法对目标点集合进行处理,根据各个目标点的势能值,对其进行优化排序。

将其应用到A*寻路,引导节点搜索向更趋近于最短路径的目标节点方向扩展,提升了移动机器人路径规划的时间性能和路径代价。
