机器之心报道
过去几年间,Transformer架构已经取得了巨大的成功,同时其也衍生出了大量变体,比如擅长处理视觉任务的VisionTransformer(ViT)。本文要介绍的BodyTransformer(BoT)则是非常适合机器人策略学习的Transformer变体。
我们知道,物理智能体在执行动作的校正和稳定时,往往会根据其感受到的外部刺激的位置给出空间上的响应。比如人类对这些刺激的响应回路位于脊髓神经回路层面,它们专门负责单个执行器的响应。起校正作用的局部执行是高效运动的主要因素,这对机器人来说也尤为重要。
但之前的学习架构通常都没有建立传感器和执行器之间的空间关联。鉴于机器人策略使用的架构基本是为自然语言和计算机视觉开发的架构,它们常常无法有效地利用机器人机体的结构。
不过,Transformer在这方面还是颇具潜力的,已有研究表明,Transformer可以有效地处理长序列依赖关系,还能轻松地吸收大量数据。Transformer架构原本是为非结构化自然语言处理(NLP)任务开发的。在这些任务中(比如语言翻译),输入序列通常会被映射到一个输出序列。
基于这一观察,加州大学伯克利分校PieterAbbeel教授领导的团队提出了BodyTransformer(BoT),增加了对机器人机体上的传感器和执行器的空间位置的关注。

论文标题:BodyTransformer:LeveragingRobotEmbodimentforPolicyLearning
项目网站:https://sferrazza.cc/bot_site
代码地址:https://github.com/carlosferrazza/BodyTransformer
具体来说,BoT是将机器人机体建模成图(graph),其中的节点即为其传感器和执行器。然后,其在注意力层上使用高度稀疏的掩码,以防止每个节点关注其直接近邻之外的部分。将多个结构相同的BoT层连接起来,就能汇集整个图的信息,这样便不会损害该架构的表征能力。BoT在模仿学习和强化学习方面都表现不俗,甚至被一些人认为是策略学习的「GameChanger」。
BodyTransformer
如果机器人学习策略使用原始Transformer架构为骨干,则通常会忽视机器人机体结构所提供的有用信息。但实际上,这些结构信息能为Transformer提供更强的归纳偏置。该团队在利用这些信息的同时还保留了原始架构的表征能力。
BodyTransformer(BoT)架构基于掩码式注意力。在这个架构的每一层中,一个节点都只能看到其自身和其直接近邻节点的信息。如此一来,信息就会依照图的结构而流动,其中上游层会根据局部信息执行推理,下游层则能汇集更多来自更远节点的全局信息。

如图1所示,BoT架构包含以下组件:
1.tokenizer:将传感器输入投射成对应的节点嵌入;
2.Transformer编码器:处理输入嵌入并生成同样维度的输出特征;
3.detokenizer:解除token化,即将特征解码成动作(或用于强化学习批评训练的价值)。
tokenizer
该团队选择将观察向量映射成局部观察构成的图。
在实践中,他们将全局量分配给机器人机体的根元素,将局部量分配给表示对应肢体的节点。这种分配方式与之前的GNN方法类似。
然后,使用一个线性层将局部状态向量投射成嵌入向量。每个节点的状态都会被馈送给其节点特定的可学习的线性投射,从而得到一个包含n个嵌入的序列,其中n表示节点的数量(或序列长度)。这不同于之前的研究成果,它们通常仅使用单个共享的可学习的线性投射来处理多任务强化学习中不同数量的节点。
BoT编码器
该团队使用的骨干网络是一个标准的多层Transformer编码器,并且该架构有两种变体版本:
BoT-Hard:使用一个反映该图结构的二元掩码来掩蔽每一层。具体来说,他们构建掩码的方式是M=I_n+A,其中I_n是n维单位矩阵,A是对应于该图的邻接矩阵。图2展示了一个示例。这让每个节点仅能看到其自身和其直接近邻,并且能为该问题引入相当可观的稀疏性——从计算成本角度看,这特别有吸引力。

BoT-Mix:将带有掩码式注意力的层(如BoT-Hard一样)与带有无掩码式注意力的层交织在一起。
detokenizer
Transformer编码器输出的特征会被馈送给线性层,然后被投射成与该节点的肢体关联的动作;这些动作是根据相应执行器与肢体的接近程度来分配的。同样,每个节点的这些可学习的线性投射层是分开的。如果将BoT用作强化学习设置中的批评架构,则detokenizer输出的就不再是动作,而是价值,然后在机体部位上取平均值。
实验
团队在模仿学习和强化学习设置中评估了BoT的性能。他们维持了与图1相同的结构,只用各种基线架构替换BoT编码器,以确定编码器的效果。
这些实验的目标是解答以下问题:
掩码式注意力是否能提升模仿学习的性能和泛化能力?
相比于原始的Transformer架构,BoT是否能表现出正面的规模扩展趋势?
BoT是否与强化学习框架兼容,有哪些合理设计选择可以尽可能地提升性能?
BoT策略是否可以应用于真实世界机器人任务?
掩码式注意力在计算方面有哪些优势?
模仿学习实验
团队在机体跟踪任务上评估了BoT架构的模仿学习性能,该任务是通过MoCapAct数据集定义的。
结果如图3a所示,可以看到BoT的表现总是优于MLP和Transformer基线。值得注意的是,在未曾见过的验证视频片段上,BoT相对于这些架构的优势还会进一步增大,这证明机体感知型归纳偏置能带来泛化能力的提升。
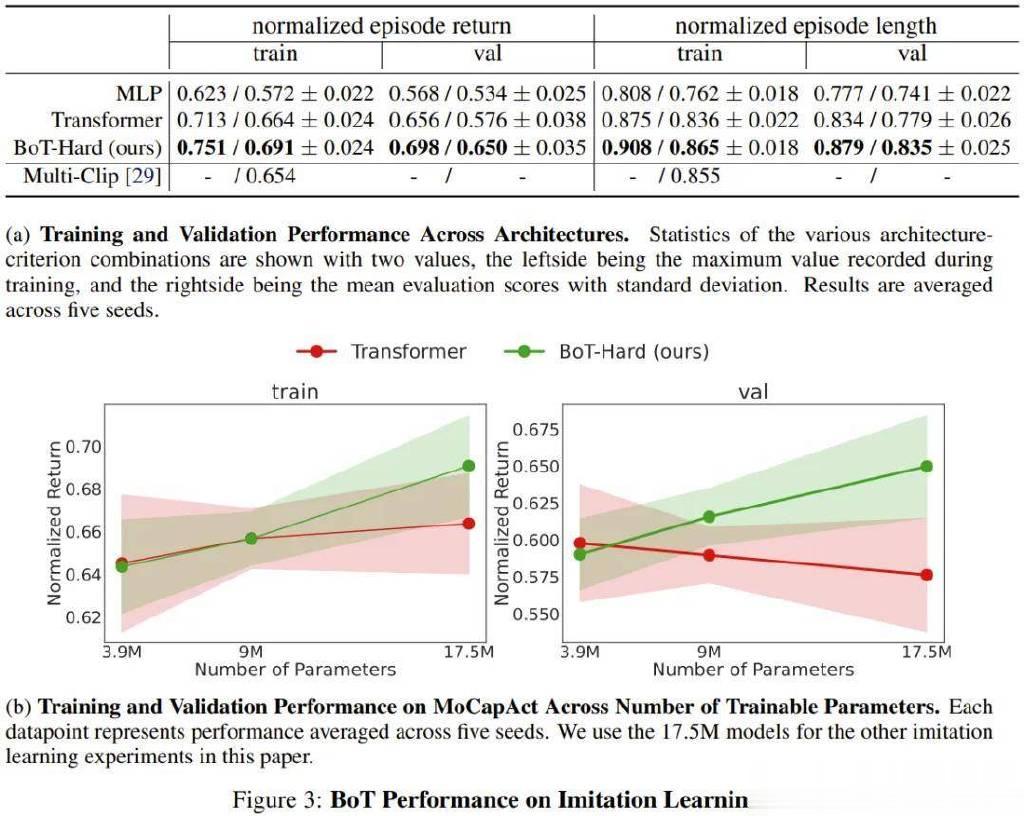
而图3b则表明BoT-Hard的规模扩展性很不错,相较于Transformer基线,其在训练和验证视频片段上的性能都会随着可训练参数量的增长而增长这进一步表明BoT-Hard倾向于不过拟合训练数据,而这种过拟合是由具身偏置引起的。下面展示了更多实验示例,详见原论文。


强化学习实验
该团队在IsaacGym中的4个机器人控制任务上评估了BoT与使用PPO的基线的强化学习性能。这4个任务分别是:Humanoid-Mod、Humanoid-Board、Humanoid-Hill和A1-Walk。
图5展示了MLP、Transformer和BoT(Hard和Mix)在训练期间的评估rollout的平均情节回报。其中,实线对应于平均值,阴影区域对应于五个种子的标准误差。
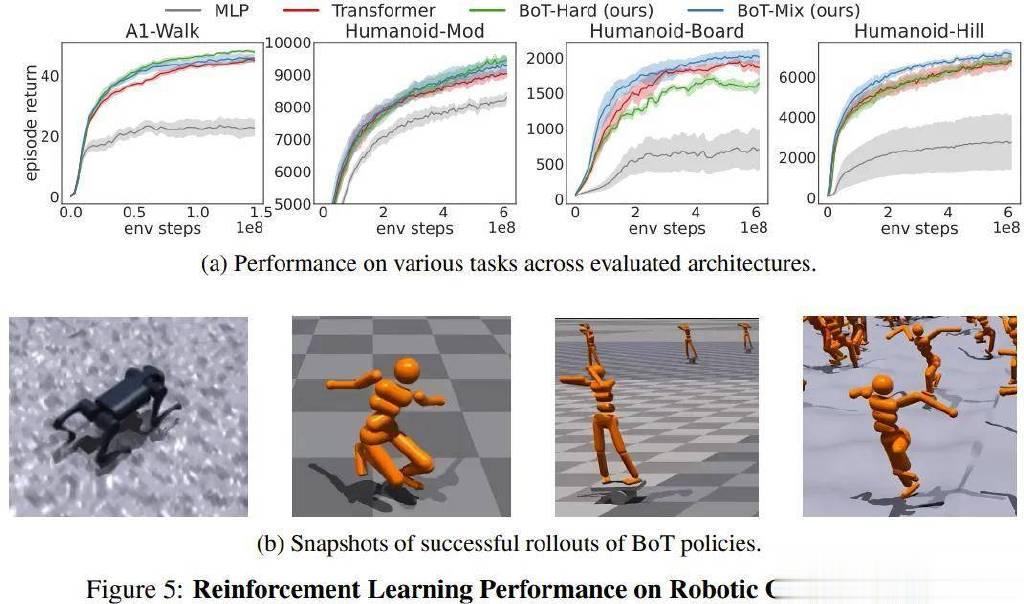
结果表明,BoT-Mix的性能在样本效率和渐近性能方面始终优于MLP和原始Transformer基线。这说明将来自机器人机体的偏置整合进策略网络架构是有用的。
同时,BoT-Hard在较简单的任务(A1-Walk和Humanoid-Mod)上的表现优于原始Transformer,但在更困难的探索任务(Humanoid-Board和Humanoid-Hill)上表现却更差。考虑到掩码式注意力会妨碍来自远处机体部分的信息传播,BoT-Hard在信息通信方面的强大限制可能会妨碍强化学习探索的效率。
真实世界实验
IsaacGym模拟的运动环境常被用于将强化学习策略从虚拟迁移到真实环境,并且还不需要在真实世界中进行调整。为了验证新提出的架构是否适用于真实世界应用,该团队将上述训练得到的一个BoT策略部署到了一台UnitreeA1机器人中。从如下视频可以看出,新架构可以可靠地用于真实世界部署。

计算分析
该团队也分析了新架构的计算成本,如图6所示。这里给出了新提出的掩码式注意力与常规注意力在不同序列长度(节点数量)上的规模扩展结果。
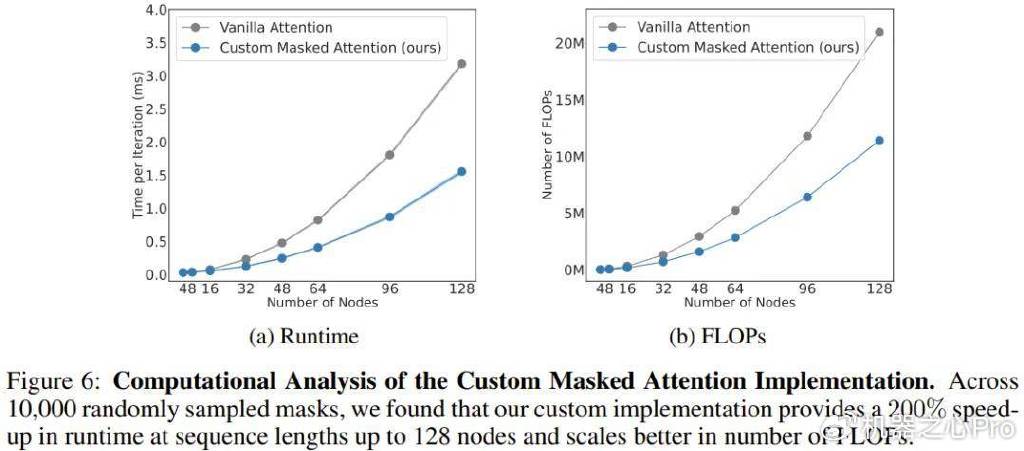
可以看到,当有128个节点时(相当于拥有灵巧双臂的类人机器人),新注意力能将速度提升206%。
总体而言,这表明BoT架构中的源自机体的偏置不仅能提高物理智能体的整体性能,而且还可受益于架构那自然稀疏的掩码。该方法可通过充分的并行化来大幅减少学习算法的训练时间。
