出品丨虎嗅汽车组
作者丨肖漫
头图丨电影《天才枪手》
一次全行业的端到端切换,让车企们的智驾竞赛又回到同一起跑线上。
随着特斯拉基于端到端路线的FSDv12.5版本在北美地区已经取得了令人惊艳的效果,今年以来,国内的玩家从中领悟了智驾升级的“武功秘籍”。(关于端到端的技术原理,虎嗅汽车团队曾在《特斯拉,要跟华为开战了》一文中有过详细解析)

在模块化堆规则时期,代码bug修复能力越强,智驾能力表现越好,同时场内玩家通过开城和落地速度也随之分野。但问题在于,仅凭传统的智驾规则无法从根本上解决现实世界的理解和推理问题,没办法解决许多复杂场景和Cornercase。
因此,“上限不高”的规则时代很快被大模型和端到端的到来取代,尤其是后者近乎“一日千里”的迭代速度,更是让一众车企纷纷其规则转投端到端技术路径,这其中便包括蔚小理华等玩家。
端到端已经成为智驾行业下一代共识方案,虽然没有人能明确端到端是否是自动驾驶的终局方案,但目前没有比端到端更好的智驾技术方案。
基于此,本期暗信号旨在梳理目前场内头部玩家是如何进行“端到端技术路线”布局,通过不同玩家的不同做法和落地进度,窥见车企智驾能力的演进以及接下来智驾行业的竞争锚点。
理想:双系统协同,“世界模型”外挂
理想其实是端到端路线的激进派。
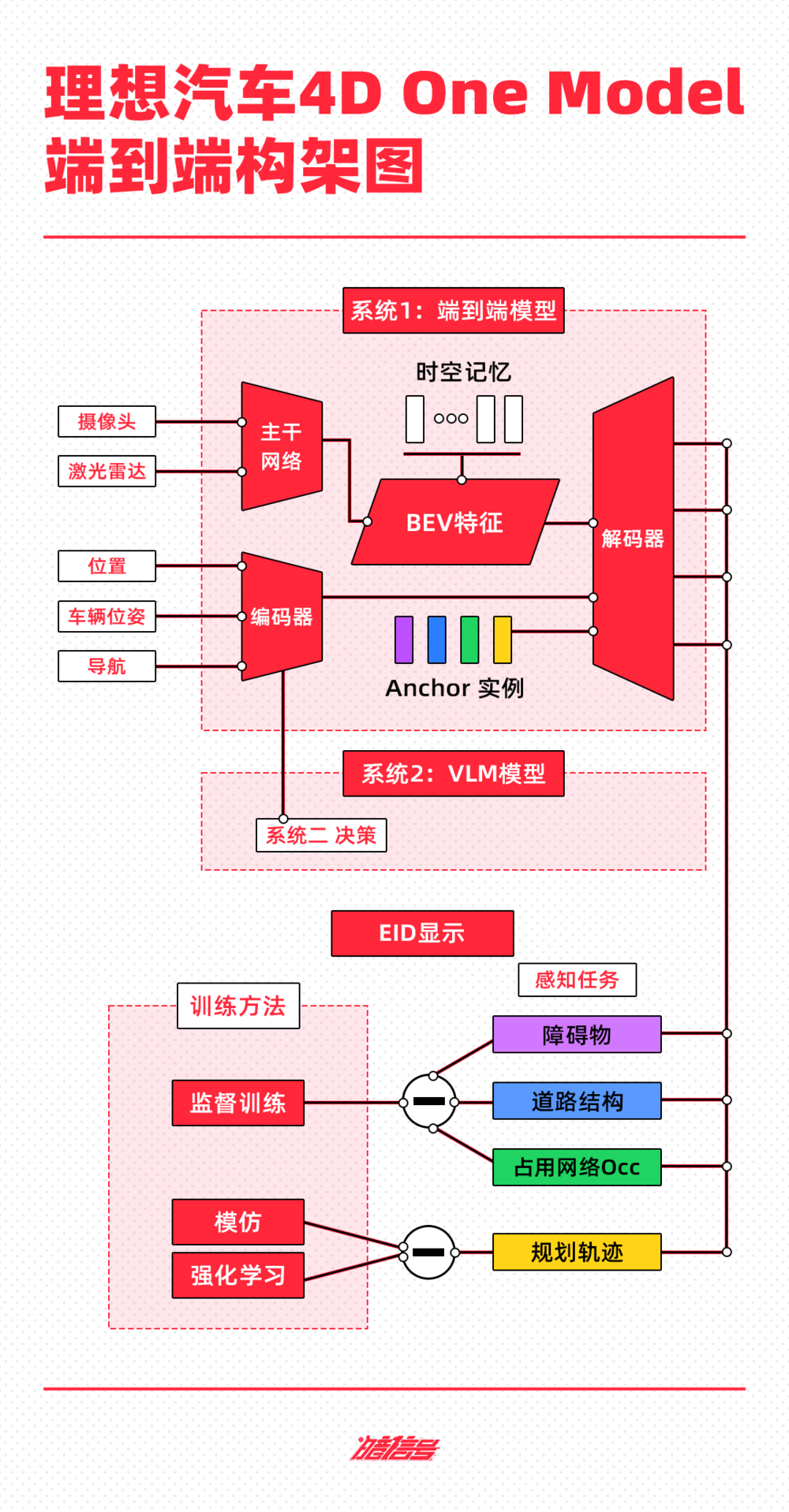
根据理想汽车公开的技术架构,其端到端自动驾驶技术方案分为端到端模型、VLM视觉语言模型、世界模型三部分。
基于快慢系统理论,理想汽车形成了自动驾驶算法架构的原型——
系统1由OneModel端到端模型实现,通过接收传感器输入,并直接输出行驶轨迹用于控制车辆;
系统2由VLM视觉语言模型实现,其接收传感器输入后,经过逻辑思考,输出决策信息给到系统1。
双系统构成的自动驾驶能力将在云端利用世界模型进行训练和验证。
端到端模型的输入主要由摄像头和激光雷达构成,多传感器特征经过CNN主干网络的提取、融合,投影至BEV空间,叠加车辆状态信息和导航信息,经过Transformer模型的编码,与BEV特征共同解码出动态障碍物、道路结构和通用障碍物,并规划出行车轨迹。
目前,系统1的训练数据库已有3亿多参数,其这一模型在实际驾驶中能够具备更高的通用障碍物理解能力、超视距导航能力、道路结构理解能力等。
系统2的VLM视觉语言模型主要面向的是5%的特殊交通场景,如遇到分时段限行、潮汐车道等负责的交通规则理解,相当于副驾坐了个驾校的教练时刻监督驾驶行为,目前已有22亿参数。
VLM视觉语言模型的工作原理是,将Prompt(提示词)文本进行Tokenizer(分词器)编码,并将前视相机的图像和导航地图信息进行视觉信息编码,再通过图文对齐模块进行模态对齐,最终统一进行自回归推理,输出对环境的理解、驾驶决策和驾驶轨迹,传递给系统1辅助控制车辆。
在实际应用场景中,如果系统二发现行驶过程中地面路面非常坑洼不平时候,其会给系统1发一个降速的提醒,并会像ChatGPT一样告知驾驶员路面信息,最终输出驾驶建议,类似“车辆将慢速行驶,以减少颠簸”。
在两大系统之外,理想利用重建+生成式的世界模型,为自动驾驶系统能力的学习和测试创造了虚拟环境,相当于通过生成真题题库,让系统1、2在虚拟世界进行考试,以验证和提高系统能力。
小鹏汽车:“三网融合”
小鹏声称是国内首个量产上车的端到端大模型,但其并非采用“一体化”的“端到端智驾大模型”,而是包括三个部分——神经网络Xnet+规控大模型XPlanner+大语言模型XBrain。

其中,神经网络XNet实现的是“感知”层面的功能,相当于眼睛。
神经网络XNet能将摄像头采集到的信息,通过动态XNet+静态XNet+2K占用网络,用超过200万个网格重构世界,对现实世界中的可通行空间进行3D还原,包括动态障碍物(行人、车辆等)、静态障碍物(水马、路障等)、路面标识(箭头、车道线等)等信息,进行纯视觉感知识别。
据官网数据,其感知范围面积可达1.8个足球场大小,同时识别50+个目标物。
基于图像数据的感知输入,规控大模型XPlanner负责“模块化”智驾路线中的“决策规划”和“控制执行”功能,类似于小脑。
相比“模块化”智驾路线中的“决策规划”模块,规控大模型XPlanner的优势在于不需要人类手写规则代码,完全依靠神经网络模型,通过海量数据的不间断训练,优化驾驶策略,让车辆有更类人的驾驶习惯和驾驶思维。
AI大语言模型XBrain充当“大脑”的角色,相当于给了智能驾驶辅助系统超越感知的“认知能力”。这其实与理想的系统二的功能有相似之处。
XBrain能够认识待转区、潮汐车道、特殊车道、路牌文字等路上交通信息。例如,面对“前方道路施工,请换道”等环境信息,其能够看懂并理解从而让车辆执行对应的操作。
小鹏方面表示,端到端大模型上车后,每2天进行一次迭代,18个月内小鹏智能驾驶能力将提高30倍。
华为:两网协同,用安全网络兜底
和小鹏一样,华为的端到端技术架构同样是分段式——感知部分采用GOD网络(GeneralObjectDetection,通用障碍物识别),决策规划采用PDP网络(Prediction-Decision-Planning,预测决策规控)实现。
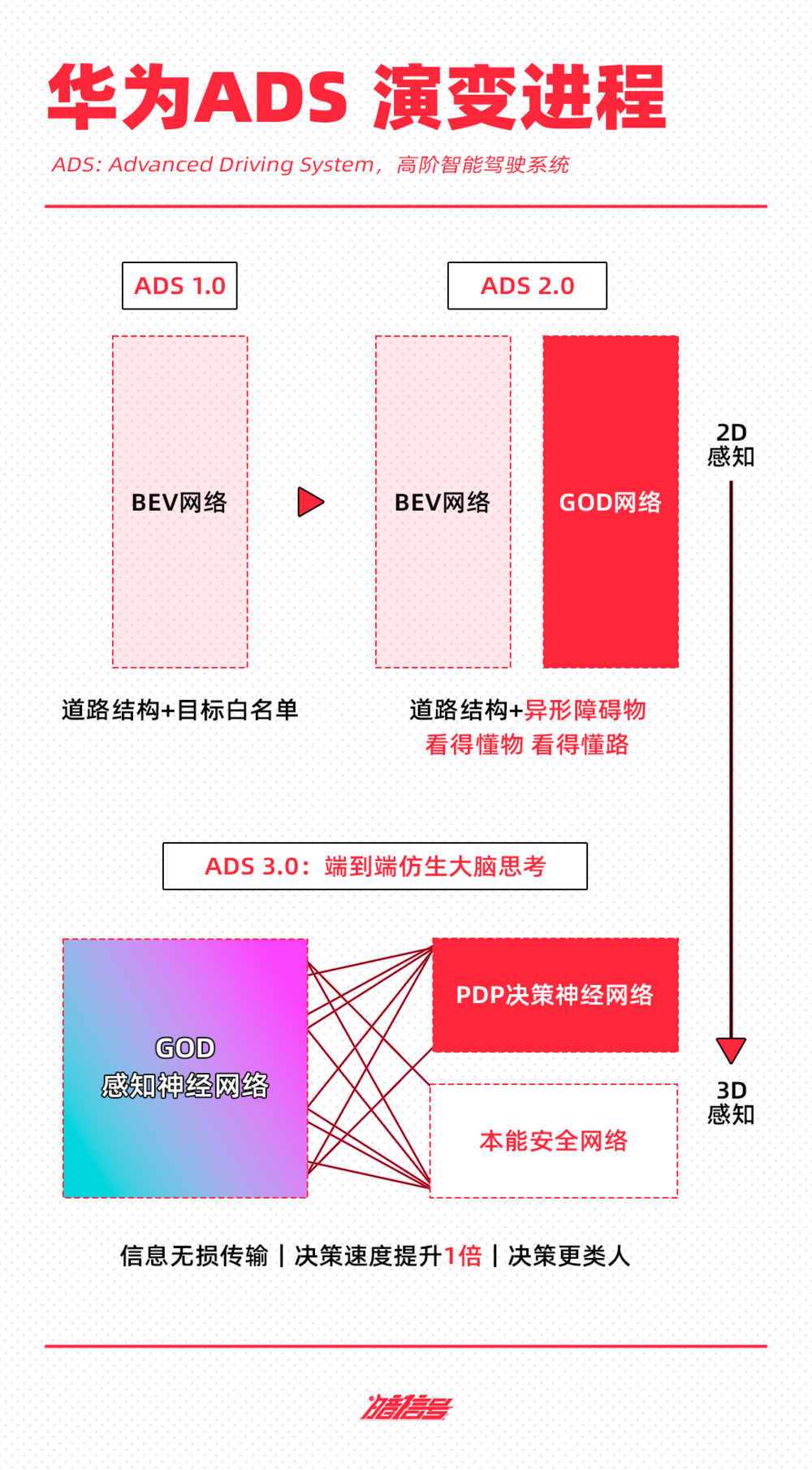
先看感知层面。在华为ADS2.0时期,其采用的是BEV+GOD+RCR网络,BEV负责看到(BEV,Bird'sEyeView,视觉为中心的鸟瞰图),GOD负责“看懂物”(GOD,GeneralObstacleDetectionNetwork,通用障碍物检测网络),RCR负责看懂路(RCR,RoadCognition&Reasoning,道路拓扑推理网络),由此实现感知层面的识别。
不过,这个阶段依旧是规则堆叠的阶段,如果传感器识别的路况信息是曾经训练过的特征信息,则能够直接输出给规控一个正确方案,但如果遇到一些未曾训练好的场景,智驾系统就容易出错或是不工作。
由此到了ADS3.0阶段,华为将GOD和RCR的算法纳入到一个完整的GOD感知神经网络之中,实现了从简单的“识别障碍物”到深度的“理解驾驶场景”。
另外,华为采用PDP(预测决策规控)网络实现预决策和规划一张网,基于感知数据规划行车路线。
有了GOD+PDP神经网络模型之后,华为再利用云端AI训练平台进行大量的数据训练,让模型得以迭代升级。
华为同样认为“让AI去开车”这件事十分激进,目前的人工智能都会AI幻觉,有30%左右的错误率,于是其在端到端模型中加入了“本能网络安全”进行兜底,提供误踩油门防碰撞功能,路面自适应AEB,在湿滑路面、雨雪路面可提前舒适制动等功能。
蔚来:引入NWM世界模型的端到端架构
关于端到端,蔚来没有公开过这一方面的技术架构。从已有的公开消息来看,其对端到端的应用目前在主动安全功能层面。
今年7月,蔚来推送了基于端到端算法实现的AEB系统,通过让模型学习真实环境下的优秀避险数据,覆盖更多“不规则”的危险场景,目前已积累了超过20亿公里的事故数据和紧急避险数据。相较于标准AEB,端到端架构的AEB在路口场景方面的紧急制动正确响应提升了5.2倍。
在蔚来智能驾驶研发副总裁任少卿看来,自动驾驶的大模型需要拆解成若干个层级,第一步是模型化,第二步是端到端,去掉不同模块间人为定义的接口,第三步是大模型。
2023年,蔚来在高速NOA的规控里加入AI神经网络,虽然任少卿曾表示蔚来的端到端智驾方案是将感知模型与规控模型合并,实现信息无损传递,但在其看来,只是端到端给出规划路径还不足够,智能驾驶走向大模型化需要具备认知和预测能力,即预判、推演其他交通参与者行为和交通环境的变化。
由此,蔚来在今年NIOIN上发布了蔚来世界模型NWM——NIOWorldModel。从蔚来智能驾驶技术架构NADArch2.0来看,蔚来已在算法层升级为引入NWM世界模型的端到端架构。

据了解,NWM是一个多元自回归生成式的具身驾驶模型,可全量理解数据,具备长时序推演和决策能力,能在100毫秒内推演出216种可能发生的场景。另外,作为生成式模型,NWM能基于3秒的驾驶视频,生成120秒的想象视频。
目前业内对于世界模型有着不同的应用思考,国内厂商多是把世界模型作为验证的一环,例如上述提到理想的技术架构中,就引入了世界模型以重建+生产的方式生成模拟数据,作为独立的架构存在。
双方对于世界模型在智驾上应用出现分歧的核心因素在于,蔚来看到了世界模型对于智驾推演、预测的可能性和可行性,但理想认为,世界模型能力还不够成熟,例如在生成上会出现幻觉等。
可以确定的是,将世界模型引入智驾领域是车企们下一步探索的方向。
端到端没有标准答案
透过头部自研厂商的技术路径可以看到,围绕端到端这一概念,不同厂商设计出不同的技术路线和模型架构,无论是OneModel的端到端还是分段式的“部分端到端”都有玩家押注。
由于技术仍处在探索阶段,目前业内也没有一个可供参考的实践案例(特斯拉虽然在北美推送了V12.5版本,但其端到端网络架构至今还未对外披露),在当前的发展阶段,行业内对端到端的路径还没有形成共识。
虽然没有标准答案,但这并不妨碍车企给出各自的解题思路。
当然,空谈技术路线并无过多意义,技术的价值在于落地,对于消费者来说,端到端技术的落地,带来最直观的感受便是智驾能力的提升。
从部分早鸟用户的使用感受以及媒体评测视频来看,搭载端到端的车型能够适应更多的城市路况,例如能够在路边开启智驾功能、实现环岛通行、在遇到障碍物时能够借道绕行等。
与此同时,端到端带来的“门到门”体验也是升级的一部分。诸如小鹏、华为等玩家都已透露将推送能够畅通ETC、小区入口档杆、工厂内部道路等场景的智驾版本,实现从家门口到办公室门口的“门到门”。
另外,人工接管次数也有了明显的下降。在规则驱动时期,车辆开启智能驾驶后,遇到规则以外的突发路况、或是稍微复杂的城市路况时都需要人工接管,但端到端大模型具备更高上限的理解能力和处理能力,能够有效降低接管次数,更为丝滑地处理不同路况。
当然,端到端目前还只是起步阶段,车企也在通过测试、迭代以优化其模型效果。可以预见的是,当下的汽车产业正迎来全新的智驾技术竞赛。
相较于规则阶段,端到端架构需要投入更多资源和资金。优质数据的筛选、清洗、标注、储存,模型训练所需的算力基础设施,部署大模型能力等,无不需要投入。
特斯拉CEO马斯克就曾强调过数据对端到端的重要性:“用100万个视频case训练,勉强够用;200万个,稍好一些;300万个,就会感到Wow(惊叹);到了1000万个,就变得难以置信了。”
何小鹏也曾提到,“自动驾驶有非常大的数据门槛,而且越往后越难成功,头部效应会越来越明显。”
数据量是一方面,对国内车企而言,算力训练也是一大竞争维度。不同于特斯拉能够大肆采购英伟达的显卡储备算力,在国内,用于云端训练的芯片一卡难求,不少车企都在高价收购。
郎咸朋就曾在交流中透露,去年年底花了大量资金买卡。据理想汽车初步估算,要从L2+走向L3,甚至是L4阶段,起码需要30EFLOPS的算力储备。
从算力层面来看,根据公开信息,部分厂商的训练资源如下:
特斯拉100EFLOPS(预计2024年年末可达到)
华为5EFLOPS(2024年8月)
蔚来1.4EFLOPS(2023年9月)
理想4.5EFLOPS(2024年7月)
小鹏2.51EFLOPS(2024年7月)
资源投入背后其实也是关乎资金的战役。小鹏汽车对外表示在AI训练上已投入了35亿费用,今后每年还将投入超过7亿元用于算力训练。郎咸朋更是直言没有10亿美元利润,未来玩不起自动驾驶。
谁家的数据更多,谁家的数据更有价值,谁家的算力更高,迭代效果更好等,都会影响端到端路径的实际应用表现。这是一场关乎数据量、算力和投入的战役,车企的智驾能力最终也将走向落地之时实现分野。
对用户而言,在不久的将来,端到端技术带来的产业变化和智驾功能升级也将有更为具象化的感知。

花粉说你是汉奸,你是霉国派过来的黑我华为的间谍,我华为的智驾比特斯拉要好千百倍。