
第一作者:Manu Suvarna
通讯作者:Javier Pérez-Ramírez
通讯单位:苏黎世联邦理工学
论文速览
本文综述了数据科学在催化研究中的应用,强调了催化剂发现和开发对全球能源、可持续性和医疗保健需求的重要性。过去十年中,数据科学概念在催化研究中的利用显著增加,以帮助解决这些问题。
文章全面回顾了催化研究者如何利用数据驱动策略解决多相、均相和酶催化中的复杂挑战。研究者将所有研究分为演绎型或归纳型模式,并统计推断催化任务、模型反应、数据表示和算法选择的普遍性。
文章突出了该领域的前沿和催化子学科之间的知识迁移可能性。关键评估揭示了实验催化中数据科学探索的明显差距,并通过详细阐述数据科学的四个支柱(即描述性、预测性、因果性和规范性分析)弥合这一差距。
文章提倡将这些分析方法纳入常规实验工作流程,并强调数据标准化对未来数字催化研究的重要性。

图文导读

图1:展示了过去十年数据驱动催化研究的增长趋势,特别是从2018年开始的指数增长。图中将催化问题解决使用机器学习(ML)的方法分类为演绎型和归纳型两种通用模式,其中演绎型任务旨在筛选或优化催化性能,而归纳型任务则侧重于通过描述符或活性位点识别来得出机理见解。

图2:网络图映射了基于催化类型(a)和驱动力(b)的演绎任务之间的关系。图中的节点表示显著实体的出版物计数,包括催化类型、驱动力、任务和数据源,节点之间的弧长与出版物之间的相互关系频率成正比。

图3:总结了催化领域主要的开源数据库,根据催化类型、数据源和它们所引发任务进行分类,并展示了这些数据库对FAIR(可发现、可访问、可互操作和可重用)原则的遵循程度。

图4:通过ML建立结构-属性-性能关系的图谱,展示了多相(a)、均相(b)和酶催化(c)中用于建立结构-属性关系的ML算法的使用情况。
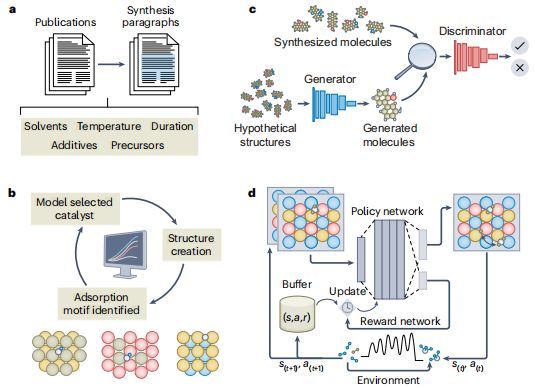
图5:展示了催化中先进的AI框架,包括从文献中提取合成程序和催化属性的语言模型(a),主动学习用于探索特定催化剂的化学空间(b),使用GANs和VAEs等深度学习模型进行假想合金和配体的虚拟生成(c),以及深度强化学习用于优化催化表面或反应网络(d)。

图6:数据驱动催化的四个支柱示意图,包括描述性分析、预测性分析、因果性分析和规范性分析。

图7:展示了数据驱动催化的生命周期,包括描述性、预测性、因果性和规范性分析在实验催化工作流程中的应用。

图8:展示了将ML算法与表征工具集成的最新进展,包括深度学习在透射电子显微镜图像分析中用于自动化原子检测(a),以及结合XANES光谱学和ML方法用于改进多相催化剂的3D几何结构(b)。
总结展望
文章强调了数据科学和机器学习(ML)在催化研究中的前景,预示着这些技术将极大提高研究生产力。同时指出,尽管这些技术不会取代人类的直觉和专业知识,但它们应该被催化研究者们接受,并成为每个从业者工具箱的一部分。
文章呼吁催化从业者发展对数据驱动概念和建模策略的基础理解,并熟悉数据准备、算法适用性评估及其优势和局限性。同时,也鼓励数据科学家培养对催化的欣赏,有效地将催化过程的复杂性转化为数据科学问题,并理解实验限制。
文章展望了一个未来,其中数字工具无缝集成到催化研究中,加速实验设计、数据分析和新知识的创造,促进数据驱动的决策制定,助力解决催化研究中的一些重大挑战。
文献信息
标题:Embracing data science in catalysis research 期刊:Nature Catalysis.
