机器之心报道
机器之心编辑部
2021年,谷歌在Nature发表了一篇颇具争议的论文《Agraphplacementmethodologyforfastchipdesign》。(作者包括JeffDean和QuocV.Le等著名研究者),其中提出了一种基于强化学习的芯片设计方法。据介绍,该芯片设计方法可在不到六小时的时间内自动生成芯片布局,并且设计结果在功耗、性能和芯片面积等所有关键指标上都优于或媲美人类工程师,而后者需要耗费数月的艰苦努力才能达到类似效果。

事实上,谷歌在更早之前就已经发布了该论文的预印本,我们也曾做过报道,详情可参阅《6小时完成芯片布局,谷歌用强化学习助力芯片设计》。
谷歌当时表示,这项基于强化学习的快速芯片设计方法对于资金紧张的初创企业大有裨益,可帮助初创企业开发自己的AI和其他专用芯片。并且,这种方法有助于缩短芯片设计周期,从而使得硬件可以更好地适应快速发展的技术研究。
论文虽然看起来大有前景,但三年来人们一直质疑不断。近日,最近一期CACM上,Synopsys的杰出架构师IgorMarkov总结了人们对这篇论文的各种质疑。
杜克大学陈怡然教授在微博上分享这篇文章
机器之心简要翻译整理了这篇文章。
本文关键见解
谷歌在Nature杂志上发表了一篇关于AI芯片设计的革命性论文。大众媒体赞誉其是一项重大突破,但它遭到了领域专家的质疑,他们认为这篇论文好得令人难以置信,而且缺乏可复现的证据。
现在,交叉检验的数据表明,由于行为、分析和报告中的错误,Nature的这篇论文的可信度受到了严重损害。对谷歌这篇论文中的欺诈和研究不当行为的详细指控已在加利福尼亚州提交。
Nature在执行自己的政策方面进展缓慢。推迟撤回有问题的出版物正在扭曲科研过程。为了维护科学研究的诚实可信,必须迅速果断地采取行动。
导语
Mirhoseinietal.在2021年在Nature发表了一篇论文,其中使用了强化学习(RL)来设计硅芯片。这篇论文得到了人们的巨大关注,也因证据不足而引发了争议。这篇来自谷歌的论文隐瞒了关键的方法步骤和重现其结果所需的大部分输入。
本文的元分析(meta-analysis)表明,有两项独立评估填补了这一空白。它们表明谷歌的这个强化学习方法赶不上人类工程师,也赶不上一种已知的算法(模拟退火)和普遍可用的商业软件,同时速度也更慢。通过对数据进行交叉检验后,IgorMarkov表示,由于行为、分析和报告中的错误,Nature的这篇论文的可信度受到了严重损害。在本文发表之前,谷歌反驳了其内部仍然存在的欺诈指控。
由于AI应用需要更大的算力,因此可以通过更好的芯片设计来提高效率。发表于Nature杂志的这篇论文声称实现了AI芯片设计的突破。它解决了优化芯片上电路元件位置的难题,并描述了对五个张量处理单元(TPU)芯片块的应用。其还表示这个方法是当时学术界或工业界最好的。
该论文还将这些说法推广到芯片设计之外,表示强化学习在组合优化方面的表现优于最先进的技术。「非凡的主张需要非凡的证据」(卡尔・萨根),但该论文缺乏公开测试示例的结果,也没有分享所使用的专有TPU芯片块。源代码——在论文发表后七个月发布,以在最初的争议之后支持该论文的发现——缺少重现方法和结果所需的关键部分。

项目代码库已经停止公开或删除,https://github.com/googleresearch/circuit_training
来自谷歌和学术界的十多位研究人员对Mirhoseinietal.的实验提出过质疑,并对所报告的研究结果提出了担忧。此后,谷歌工程师多次更新他们的开源代码,填补了一些缺失的部分,但依然不是全部。谷歌这个软件库中的开源芯片设计示例并未清楚地显示谷歌RL代码的强大性能。
显然,唯一公开声称独立复现Mirhoseinietal.的技术是由加州大学圣地亚哥分校(UCSD)的研究人员于2022年秋季开发的。他们对谷歌开源代码中缺少的关键组件进行了逆向工程,并完全重新实现了代码中缺失的模拟退火(SA)基线。谷歌没有发布Mirhoseinietal.使用的专有TPU芯片设计模块,排除了完全外部复现结果的可能性。因此,UCSD团队分享了他们在现代公共芯片设计上的实验:SA和商业电子设计自动化EDA工具的表现均优于谷歌的强化学习代码。
《纽约时报》和路透社的记者在2022年报道了这场争议,并发现早在Nature杂志提交之前,一些谷歌的研究人员(见表1)就对他们负责检查的声明提出了异议。
该论文的两位主要作者抱怨说,他们的研究一直存在欺诈指控。
2022年,谷歌解雇了内部吹哨人,并拒绝批准发表一篇批评Mirhoseinietal.研究的文章。这位吹哨人依据吹哨人保护法,对谷歌提起了错误解雇的诉讼:法庭文件详细列出了与Mirhoseinietal.研究相关的欺诈和科学不端行为的指控。
2021年Nature杂志在同一期上刊登了一篇介绍该论文的新闻观点文章,敦促复现该论文的结果。考虑到复现的障碍和复现尝试的结果,文章的作者撤回了该文章。2023年9月20日,Nature杂志为该论文添加了在线编者注。

一年后(2024年9月晚些时候),随着这篇文章的发表,Nature杂志的编者注已被移除,但出现了一份作者的附录。这份附录重复了早先声明中讨论的作者对批评的回应部分的论点。
但关于Nature论文的主要关切点还未得到解决。特别是,论文结果中关于一个额外的专有TPU块的未公开统计数据,并未支持任何实质性的结论。这只会加剧对选择性报告和误报的担忧。发布一个未说明预训练数据的预训练模型,也加剧了关于数据污染的担忧。
接下来,本文列出了对该论文的初步怀疑,并表明其中许多怀疑后来得到了证实。然后,本文检查了Mirhoseinietal.是否改进了现有技术,概述了作者的回应,并讨论了该工作在实践中的可能用途。最后,本文得出结论并指出了政策含义。
这里我们略过IgorMarkov这篇文章中对原论文的介绍,详情可参阅机器之心的报道《6小时完成芯片布局,谷歌用强化学习助力芯片设计》。我们重点来看对该研究的怀疑和指控。
最初的怀疑
尽管登上Nature的这项研究复杂而又令人印象深刻,但研究有着明显的不足。
举例来说,文中提出的强化学习(RL)被描述为能够处理更广泛的组合优化问题(如旅行商问题)。但是,该研究并没有通过对关键问题的公式化和易于配置的测试示例来展示这一点,而是解决了一个专业任务(芯片设计的宏布局),仅针对谷歌专有的TPU电路设计块提供了五个块的结果,而可用的块远不止这些。
此外,RL公式只是优化了一个包含HPWL的简化函数,但并未针对开放电路示例进行纯HPWL优化的评估,而这在其他文献中是常规操作。
可以说,这篇论文隐瞒了实验的关键方面,存在严重的遗漏,主要表现在以下几点:
第一点:标题中提到「快速芯片设计(fastchipdesign)」,然而作者只描述了设计过程时间从几天或几周到几小时的改善,但并没有提供针对每个设计的具体时间,也没有将设计过程细分为不同阶段。文章中并没说明白,几天或几周的基线设计过程是否包括了功能设计变更的时间、闲置时间、使用较低效的EDA工具的时间等。这种描述缺乏详细信息,使得读者难以理解设计时间实际缩短到了何种程度,以及这种改进的具体影响。
第二点:文章声称强化学习(RL)在每个测试用例中的运行时间不超过六小时(针对五个TPU设计块中的每一个),但这并没有包括全部的20个块。此外,RL的运行时间仅涵盖了宏布局,而RePlAce和行业工具会放置所有电路组件。
第三点:Mirhoseinietal.专注于宏布局,但却没有提供每个TPU芯片块中宏的数量、大小和形状,以及面积利用率等关键设计参数。
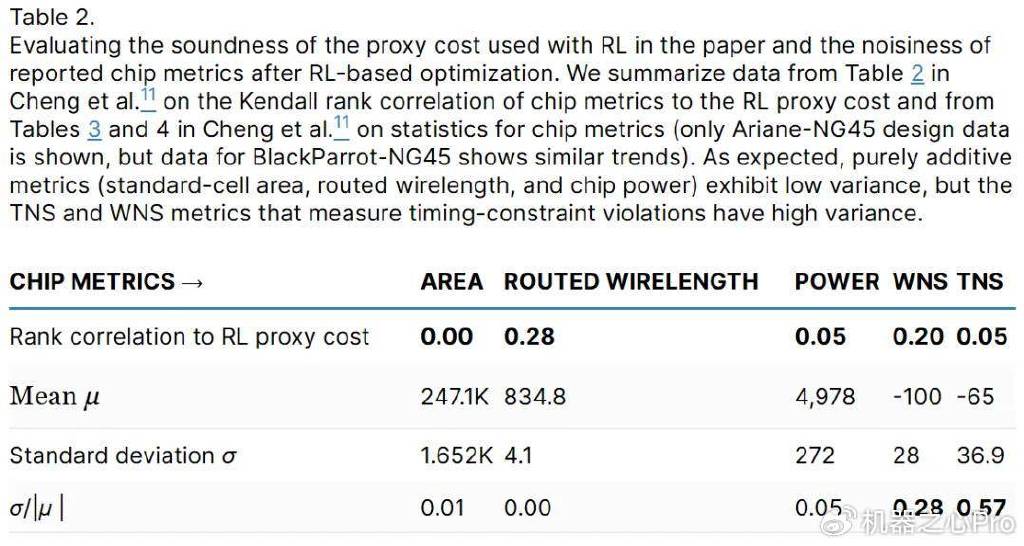
第四点:Mirhoseinietal.只给出了五个TPU块的结果,其统计明显不足,而且高方差指标会产生噪声结果(见表2)。通常情况下,使用更多的样本是常见的做法(见上表1)。
第五点:Mirhoseinietal.没有说明被强化学习(RL)超越的人类芯片设计师的资质水平。撇开可复现性不谈,这些结果后来在Chengetal.的研究中被证明是可以轻易改进的。
第六点:Mirhoseinietal.声称改善了面积,但芯片面积和宏面积在布局过程中并未改变,标准单元面积也没有变化(参见表2)。
第七点:对于结果随时间推移而优化的迭代算法,应该公平地比较每个测试用例在相同运行时间下哪个具有更好的质量指标,或在相同质量下哪个具有更好的运行时间,或两者都有所改进。Mirhoseinietal.没有提供这样的证据。特别是,如果基于机器学习的优化使用了非凡的计算资源,那么在其最有竞争力的形式中,模拟退火(SA)优化也应当使用同等的计算资源。这意味着在评估和比较这两种方法的效果时,应确保它们在资源使用上处于同一水平,以保证比较的公正性。
对于专家来说,Mirhoseinietal.提出的方法似乎存在缺陷,主要表现在:
H1.与SOTA相比,提出的RL使用了过多的CPU/GPU资源。因此快速芯片设计的说法需要仔细证实。
H2.逐个放置宏是最简单的方法之一。然而即使在深度RL的驱动下,逐个放置看起来也很不方便。
H3.Mirhoseinietal.使用了与20多年前类似的电路分区(聚类)方法。众所周知,这些技术与互连优化目标有所不同。
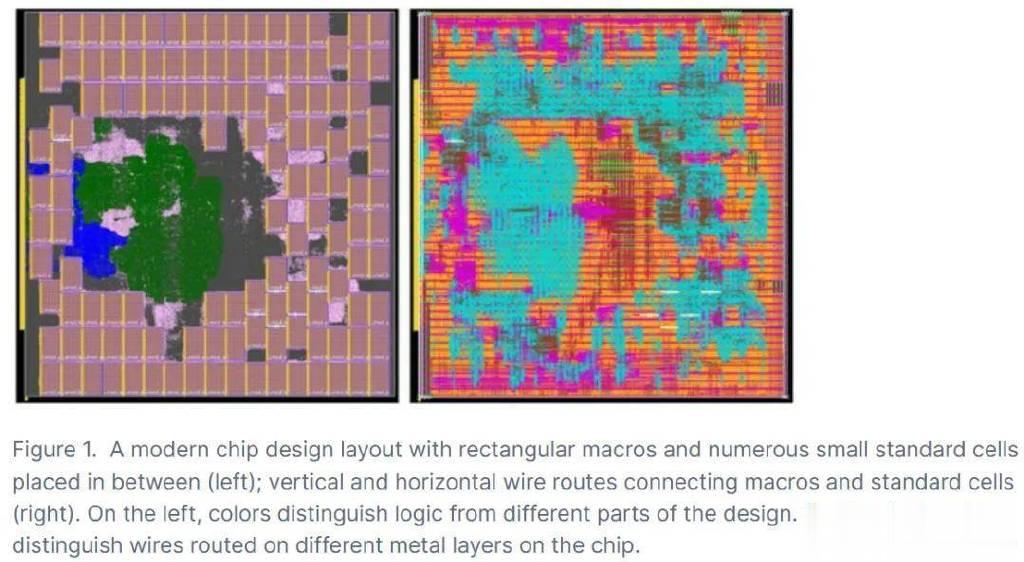
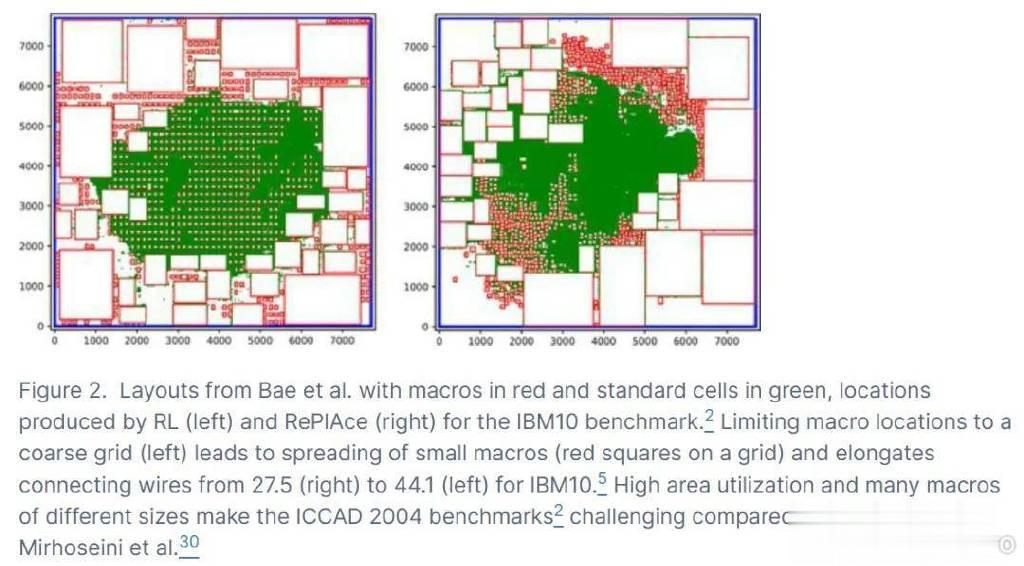
H4.Mirhoseinietal.将宏的位置限制在一个粗粒度的网格上,而最新的方法则避免了这种限制。在图1(左)中,宏被自由放置,但谷歌的强化学习倾向于将宏分散开来,并且不允许在如图1(左)中心这样的大区域内放置单元。图2展示了这种差异。这表明,虽然强化学习技术在处理某些设计任务上具有潜力,但其在处理大规模电路设计时可能需要依赖于简化的网格系统,这可能限制了其优化效果和应用范围。
H5.Mirhoseinietal.使用的力导向放置技术,仍有很大的改进空间。
除了上述内容,还有值得怀疑的基准。Nature杂志使用了多个基准来宣称所提技术的优越性。然而人类基准没有记录,并且不可复现。
B1.Mirhoseinietal.和表1中的关键结果给出了五个TPU设计模块的芯片指标。但与SA的比较并没有报告这些芯片指标。
B2.Mirhoseinietal.提到,强化学习(RL)的结果经过了模拟退火(SA)的后处理,但缺乏消融研究来评估SA对芯片指标的影响。
B3.在Mirhoseinietal.的研究中,RePlAce被用作基准,但这种使用方式与其预期用途不一致。
B4.Mirhoseinietal.没有描述在模拟退火(SA)中如何初始化宏位置,这表明作者可能采用了一种可以改进的简单方法。后来,Baeetal.确定了SA基线中的更多缺点,而Chengetal.也证实了这些问题。
更多证据
那篇Nature论文发表几个月后,那是在最初阶段的争议之后,Baeetal.、谷歌的文档和开源代码、Nature同行评议、Yueetal.给出了更多数据。
Nature给出了对Mirhoseinietal.的同行评议文件以及作者的反驳。在漫长的来回沟通中,作者向审稿人保证,宏的位置在RL放置后没有被修改,证实了宏是粗粒度网格放置的。在几份投稿中,Baeetal.实现了Nature审稿人的要求,并在17个公开芯片设计示例上对谷歌的技术进行了基准测试,结果表明:先前的方法明显优于谷歌RL。
美国和德国的一些教授公开表达了对这篇Nature论文的质疑。当研究人员注意到谷歌开源版本中的缺陷时,例如分组(聚类)流程,谷歌工程师发布了更多代码(但不是全部),这反倒引发了更多问题。
又过了一年,最初的怀疑变大了,因为结果表明,当宏布局不局限于网格时,人类设计师和商用EDA工具的表现均优于谷歌这个方法。在Chengetal.的表2中,作者估计了通过RL优化的代理成本函数与Nature论文表1中使用的芯片指标的秩相关性。Chengetal.在表3中估计了基于RL的优化之后,芯片指标的平均值和标准差。
本文的表2给出了一些总结,可以看到所有芯片指标的秩相关性都很低,而TNS和WNS的噪声程度很高。
因此,Mirhoseinietal.对TNS和WNS的优化依赖于有缺陷的代理,并产生了统计意义可疑的结果。可以注意到,在Ariane-NG45以及BlackParrot-NG45上的TNS的σ/|μ|>0.5。除了媒体的批评,Mirhoseinietal.也受到了三位美国教授的质疑。
未公开使用商业工具的(x,y)位置
UCSD的那篇论文中给出了强有力的证据和谷歌工程师的确认,表明作者隐瞒了一个关键细节:在对输入网表进行聚类时,谷歌代码中的CTmerge会读取一个位置以根据位置重组集群。为了生成宏的(x,y)位置,论文的作者使用了Synopsys的商业EDA工具生成的所有电路元件(包括宏)的初始(x,y)位置。
Mirhoseinietal.的主要作者确认使用了这一步骤,并声称这并不重要。但在Chengetal.的论文中,该步骤可将关键指标提高7-10%。因此,Mirhoseinietal.的结果需要未被明确说明的算法步骤,例如从商业软件中获取(x,y)数据。
Chengetal.的论文中还列举了更多未在论文中说明的技术,其中还提到了Nature论文、其源代码与谷歌芯片设计实际使用的代码之间的差异。这些差异包括代理成本函数中项的特定权重、与电路不同的邻接矩阵构造,以及Mirhoseinietal.的论文中没有源代码或完整描述的几个「黑箱」元素。Baeetal.、Chengetal.、MacroPlacementRepo提供了缺失的描述。此外,Mirhoseinietal.的结果与所用方法不符,因为论文中没有提到一些关键组件。仅凭描述无法复现其结果和方法。
训练数据和测试数据之间存在数据泄漏
根据Mirhoseinietal.的说法,「当我们将策略网络暴露给更多种类的芯片设计时,它就不太容易过度拟合。」
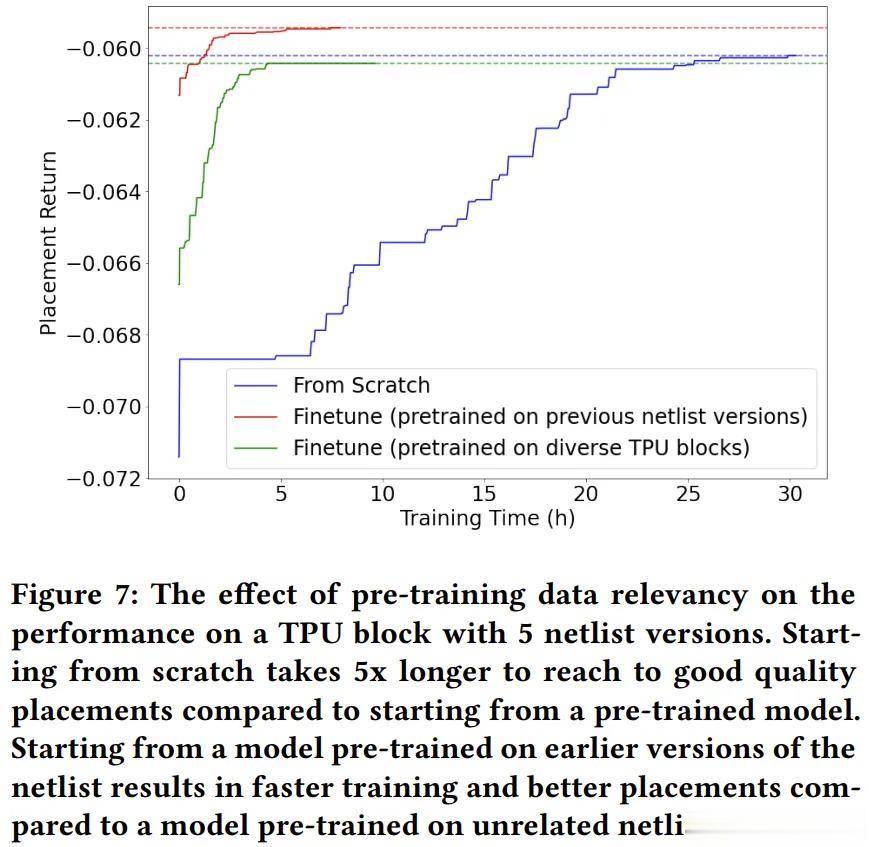
但谷歌Team1后来在Yueetal.中表明,对「多样化TPU块」进行预训练并没有提高结果质量。对「以前的网表版本」进行预训练会稍微提高质量。对RL进行预训练并在类似设计上对其进行评估可能是Mirhoseinietal.方法论中的一个严重缺陷。由于谷歌没有发布专有的TPU设计或每个设计的统计数据,所以无法比较训练和测试数据。
可能的局限性
Mirhoseinietal.没有透露其方法的主要局限性,但却表示其可在更广泛的组合优化中取得成功。Mirhoseinietal.中的Ariane设计显示了相同大小的宏模块:这是一个潜在的限制,因为商用芯片设计通常会使用多种不同的宏尺寸。然而,他们没有报告每个TPU块的基本统计数据:宏的数量及其形状、设计面积利用率以及宏占用的面积分数。根据同行评议和谷歌工程师对Chengetal.作者的指导,TPU块的面积利用率似乎低于典型的商用芯片设计。
谷歌RL在Baeetal.和Chengetal.中使用的Adya和Markov的具有挑战性的公共基准测试上表现不佳(如图2所示),这表明存在未公开的局限性。
另一个可能的限制是对预置(固定)宏的处理不当,这在行业布局中很常见,但Mirhoseinietal.没有讨论过。通过干扰预置宏,网格化可能会影响实践中的可用性。
在公共基准测试上的表现不佳的原因也可能是由于对专有TPU设计的过度拟合。
使用中等的模拟退火基线
谷歌Team2的更强基准论文《Strongerbaselinesforevaluatingdeepreinforcementlearninginchipplacement》通过在swap、shift和mirror操作中添加move和shuffle操作,改进了谷歌Team1在Mirhoseinietal.中使用的并行SA。在优化相同的目标函数时,这种改进的SA通常会在更短的时间内产生比RL更好的结果。
Chengetal.通过独立实现SA复现了Baeetal.的定性结论,发现SA结果的方差小于RL结果。
此外,Baeetal.为SA提出了一种简单快速的宏初始化启发式方法,并在比较RL与SA时可均衡计算时间。
鉴于SA在1980到1990年代被广泛使用,与弱的SA基线相比,自然会导致新的RL技术被高估。
这篇Nature论文是否提高了现有技术水平?
Nature杂志的社论在讨论该论文时推测:「这是一项重要的成就,将对加速供应链产生巨大的帮助。」
但在多家芯片设计和EDA公司进行评估和复现尝试后,可以肯定地得出结论,这篇Nature论文没有取得任何重要成就,因为以前的芯片设计软件,特别是来自CadenceDesignSystems的软件,可以更快地产生更好的布局。如果该论文的审稿人或公众都知道这些事实,那么该论文关于改进TPU设计的主张将是荒谬的。
这篇Nature论文声称人类比商业EDA工具产生了更好的结果,但没有给出证实。
谷歌Team2和UCSD团队采用不同的方法将Mirhoseinietal.中的方法与基线方法进行比较,累积报告了与商业EDA工具、人类设计师、学术软件以及SA的两个独立自定义实现的比较结果。
谷歌Team2遵循Mirhoseinietal.中的描述,没有提供初始布局信息。UCSD团队试图复现谷歌实际所做的事情以产生结果(缺乏Mirhoseinietal.的详细信息)。
谷歌Team2可以访问TPU设计模块,并证明预训练的影响实际上很小。
尽管UCSD团队无法访问谷歌的训练数据和代码,但还是获得了与Mirhoseinietal.类似的结果,无需预训练。他们还按照谷歌Team2的指令重新实现了SA,并引入了几个新的芯片设计示例(表1)。
Nature论文中RePlAce的使用方式与其预期用途不一致。Baeetal.、Chengetal.通过正确使用RePlAce,在ICCAD2004基准测试中为RePlAce取得了出色的结果。
Nature论文中使用的模拟退火的实现存在障碍,消除障碍(在同一源代码库中)改进了结果。如果正确实现,SA会使用更少的运行时间产生比谷歌CT/RL更好的解决方案,并且两者都被赋予相同的代理成本函数。Baeetal.、Chengetal.证明了这一点。
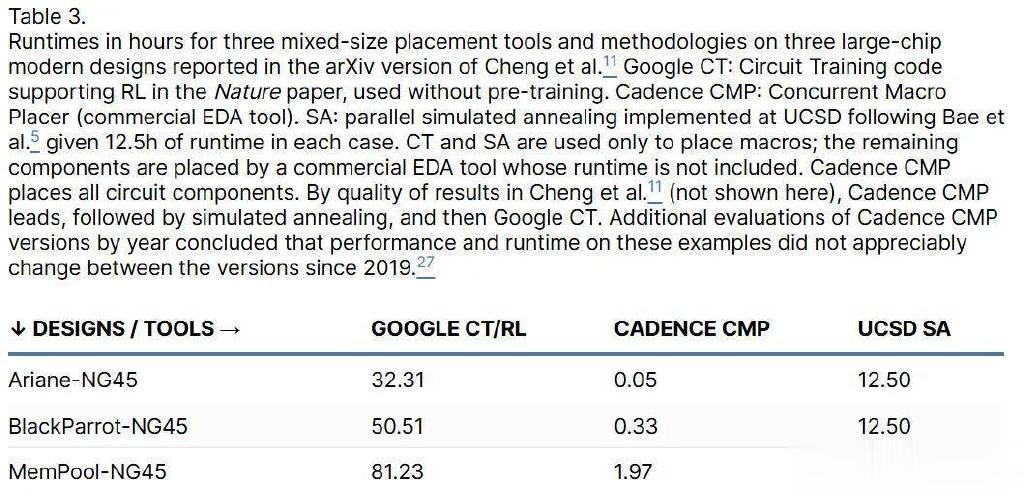
与谷歌CT/RL相比,SA持续改进了线长和功率指标。对于电路时序指标TNS和WNS,SA产生的噪声较小,但与RL的结果相当。回想一下,SA和RL优化的代理函数不包括时序指标,这使得SA或RL实现这些改进的断言显得很可疑。
谷歌CT/RL未能在人类基线、商业EDA工具和SA的质量上有所提高。它也没有改进运行时SOTA(表3),并且作者没有透露每个设计数据或设计过程的时间。如果配置/实现得当,RePlAce和SA会提供更强的基线。
对这篇Nature论文批评的反驳
尽管媒体进行了批评并提出了技术问题,但作者未能消除Mirhoseinietal.的方法和结果的复现的剩余障碍。
UCSD团队的工程努力克服了这些障碍,他们跟进了谷歌Team2批评Nature论文的工作,然后分析了其中的许多问题。在CT代码库出现之前,谷歌Team2就可以访问谷歌TPU设计和论文中使用的源代码。Chengetal.和MacroPlacementRepo的UCSD作者可以访问CT并受益于谷歌Team1工程师的长期参与,但无法访问Baeetal.或Mirhoseinietal.中使用的SA代码或CT框架中缺失的其他关键代码片段。
然而,Baeetal.、Chengetal.的结果与MacroPlacementRepo相互印证,并且他们的定性结论是一致的。UCSD的Ariane-NG45结果与GoogleTeam1工程师的结果非常匹配,Chengetal.中表明UCSD生成的Ariane-NG45的CT训练曲线与GoogleTeam1工程师生成的结果相匹配。谷歌Team1工程师仔细审查了该论文以及2022年秋季和2023年冬季的研究结果,没有提出异议。
Nature论文的两位主要作者于2022年8月离开谷歌,但在2023年3月,他们对Chengetal.的结果提出了反对。没有弥补原工作的缺陷。这些反对意见立即在宏布局代码库的FAQ部分得到解决。其中一个问题是Chengetal.的实验中缺乏预训练。
预训练
Chengetal.使用谷歌CircuitCT库中的代码和指令进行训练,其中指出(2023年6月):「以下结果是从头开始训练的结果,因为目前无法共享预训练模型。」
根据MacroPlacementRepo中的MacroPlacementFAQ,Chengetal.没有使用预训练,因为根据谷歌的CTFAQ,不需要预训练来重现Mirhoseinietal.的结果。此外,谷歌没有公布预训练数据。
谷歌Team2使用谷歌内部的代码评估预训练,发现对与SA或RePlAce的比较没有影响。
谷歌Team1表明「不同TPU块」的预训练并没有改善结果,只改善了运行时间。「以前的网表版本」的预训练略有改善。CT文档或论文本身没有讨论、披露或发布此类先前版本。
换句话说,Nature论文的主要作者希望其他人使用预训练,但他们没有足够详细地描述它以进行复现,没有发布它的代码或数据,并且已经表明它不会改善预训练的结果。
2024年9月(发表几年后),作者宣布发布预训练模型,但未发布预训练数据。因此,我们无法确保用于测试的特定示例未在预训练中使用。
基准老旧
另一个反对意见是Baeetal.和Chengetal.使用的公共电路基准测试据称使用了过时的基础设施。
事实上,这些基准已经使用HPWL目标进行了评估,该目标可以在芯片设计的几何2D缩放下准确缩放,并且仍然适用于所有技术节点(第2节)。ICCAD基准是由那篇论文的同行评审员#3要求的。当Baeetal.和Chengetal.实现了这个要求,在路由变得相关之前,谷歌RL遇到了麻烦:在HPWL优化中,RL差了20%左右(HPWL是CT/RL优化的代理成本中最简单但最重要的项)。
Chengetal.的实验中,没有训练到收敛
MacroPlacementRepo中的FAQ#15立即解决了这一问题:「CTGitHub存储库提供的任何指南中都没有描述『训练到收敛』。」
后来,他们的额外实验表明,「训练直到收敛会恶化一些关键芯片指标,同时改善其他指标,凸显了代理成本和芯片指标之间的不良相关性。总体而言,与ISPD2023论文中报告的模拟退火和人类宏放置的结果相比,直到收敛的训练不会发生质的变化。」Baeetal.的RL-vs-SA实验早于CT框架,也早于Mirhoseinietal.声称的训练不到6小时就收敛的方法。
Nature论文使用的计算资源非常昂贵且难以复现。由于RL和SA算法都会在早期产生可行的解决方案,然后逐渐改进代理函数,因此Chengetal.的尽力而为的比较使用的计算资源比Mirhoseinietal.的计算资源要少,并且RL和SA之间具有同等性。结果:SA击败RL。
Baeetal.使用与Mirhoseini相同的计算资源对RL和SA进行了比较。Chengetal.的结果与Baeetal.的结果一致。如果给予更多资源,SA和RL不太可能进一步改善芯片指标,因为其与Mirhoseini的代理函数相关性较差。
该论文的主要作者在Goldie和Mirhoseini在声明《Statementonreinforcementlearningforchipdesign》中提到,该论文被大量引用,但他们没有引用谷歌之外的任何积极的复现结果来清除所有已知的障碍。Baeetal.和Chengetal.没有讨论在IC设计中使用RL的其他方法,因此这里不再进行一般性结论。
谷歌这篇论文中的成果可用吗?
发表于Nature的这篇谷歌论文声称这些方法可应用于最近的谷歌TPU芯片,这似乎佐证了他们声称的东西:即这些方法改进了最新技术水平。但除了含糊的一般性声明外,没有报告明确说明对生产级芯片的芯片指标改进。
前文已经表明,该论文和框架中的方法落后于SOTA,例如1980年代的模拟退火(SA)。此外,谷歌的Baeetal.内部实现的SA足以替代那篇Nature论文中提出的强化学习方法。谷歌既声称在TPU设计中使用了这个RL方法,但实际上这个方法又落后于SOTA,为什么会这样?这篇文章试图给出一些解释。
鉴于芯片时序指标TNS和WNS在强化学习结果中的方差较大,所以使用远远更长的运行时间,尝试使用不同的代理成本函数和超参数设置进行多次独立随机尝试可能会改善最佳结果,但SA也能做到这一点。
使用内部方法(即使是较差的方法)是行业实践中称为dogfooding(吃自己的狗粮)的常见方法。在大多数芯片中,一些块并不重要(不会影响芯片速度),是很好的dogfooding候选。这可以解释谷歌为什么选择性地公布生产级使用」和报告。(注:在芯片设计领域,dogfooding是指芯片设计公司内部的工程团队会使用自己设计的芯片进行测试和验证,以确保芯片满足预期的性能、功能和质量。这种方法可以帮助团队发现潜在的设计缺陷、优化用户体验,并提前解决问题,而不是等到产品发布后才被客户发现。)
强化学习的结果由SA30进行过后处理,但CTFAQ否认了这种后处理——TPU设计流程中使用了后处理,但在将RL与SA进行比较时未使用。但由于成熟的SA始终胜过强化学习,因此SA完全可以替代强化学习(可以使用SA中的自适应温度调度来适应初始位置)。
谷歌Team1的后续研究表明(如图7所示),仅在对基本相同的设计进行预训练时,预训练才能改善结果。也许,谷歌在对IC设计进行多次修订时利用了强化学习——这是一个有效的背景,但这篇Nature论文中没有描述这一点。此外,从头开始运行时,商用EDA工具的速度比强化学习快几个数量级,因此预训练RL并不能缩小差距。
谷歌CT/RL代码可以得到改进吗?
RL和SA比SOTA慢几个数量级(表3),但预训练(CT中没有)仅能将RL的速度提高几倍。CT代码库现在包含尝试过的改进措施,但我们尚未看到芯片指标的重大提升。改进版CT库和论文仍然存在四个主要障碍:
RL优化的代理成本并不能反映电路时序,因此改进RL可能无助于改进TNS和WNS。
在优化给定的代理函数时,SA优于RL。因此,即使使用更好的代理,RL也可能会失败。
RL在粗粒度网格上放置宏会限制它们的位置(图2)。当人类忽略粗网格时,他们会找到更好的宏位置。商用EDA工具也避免了这种限制,并且优于谷歌的CT/RL。
作为预处理步骤的聚类会导致放置和网表分区目标之间不匹配。
总结
这篇元分析讨论了对Mirhoseinietal.那篇Nature论文的结果的复现和评估,以及其中方法、结果和声明的有效性。他们发现,那篇论文中包含机器学习中的多种可疑做法,包括不可重复的研究实践、挑选好结果、误报和可能的数据污染。
基于交叉检验的新数据,本文得出了具有足够冗余度的结论:由于研究中实现、分析和报告中的错误,该论文的可信度严重不足。遗漏、不一致、错误和失实陈述影响了他们的方法、数据、结果和解释。
关于那篇Nature论文的结论
谷歌Team2可以访问谷歌的内部代码,而Chengetal.对缺失的组件进行了逆向工程和/或重新实现。谷歌Team2和UCSD团队从类似的实验中得出了一致的结论,并且每个团队都进行了额外的观察。
这里交叉检查了谷歌Team2和UCSDTeam报告的结果,并考虑了CT框架、Nature同行评议和Yueetal.,然后总结了这些工作得出的结论。这证实了对这些声明的许多初步怀疑,并发现了其他缺陷。
因此,很明显,Mirhoseinietal.的Nature论文在多个方面具有误导性,以至于读者无法相信其最重要的声明和结论。Mirhoseinietal.没有改进SOTA,而原始论文的方法和结果无法从提供的描述中重现,这违反了Nature的既定编辑政策。依赖专有的TPU设计进行评估,以及实验报告不足,继续阻碍着方法和结果的可复现性。
这篇Nature论文作者试图驳斥批评,但未能成功。
令人惊讶的是,自Chengetal.发表论文以来,Mirhoseinietal.的作者在一年半内没有提供新的令人信服的实证结果。
对芯片设计的影响
这里仅强调了那篇Nature论文方法中的不足之处。但2024年来自中国的一项研究成果《Benchmarkingend-to-endperformanceofAI-basedchipplacementalgorithms》使用他们新的独立评估框架比较了七种混合尺寸布局技术,其中有20个电路(其中七个带有宏)。
他们在芯片指标上的端到端研究结果表明,基于ML的技术落后于RePlAce(嵌入在OpenROAD中)和其他基于优化的技术:DREAMPlace(基于GPU的RePlAce算法变体)和AutoDMP(围绕DREAMPlace的贝叶斯优化wrapper)。尽管复现Mirhoseinietal.的方法具有明显的必要性,但Wangetal.的作者无法提供这样的结果。
政策影响
理论论证和实证证据表明,各个领域发表的大量论文无法复现,而且可能不正确。比如Nature杂志这篇论文就加剧了复现危机,破坏了人们对已发表研究的信任。
RetractionWatch每年能追踪到5000起撤稿事件,包括突出的研究不端行为案例。其表示,「研究不端行为是一个严重的问题,而且(可能)越来越严重」,这使得我们更有必要将诚实的错误与故意夸大和不端行为区分开来。机构需要给出回应,包括在Nature撤稿通知中进行明确说明。
Nature的编辑政策应被广泛而严格地遵守。引自《NaturePortfolio》:
「出版的固有原则是,其他人应该能够复现和借鉴作者发表的主张。在NaturePortfolio期刊上发表论文的条件是,作者必须及时向读者提供材料、数据、代码和相关协议,而无需要求资格……出版后,如果读者遇到作者拒绝遵守这些政策的情况,应联系期刊的主编。」
具体到Mirhoseinietal.这篇论文,杂志社论坚称「技术专长必须广泛分享」。但是,当稿件作者忽视公开基准测试的要求并阻碍复现时,他们的技术主张应该受到怀疑(尤其是如果他们后来不同意与他们的工作进行比较)。
根据同行评议文件,这篇论文的接收取决于代码和数据的发布,但在Mirhoseinietal.发表时或之后,这都没有发生。
这些作者还对那篇Nature论文进行了修改,声称代码已经可用。但发布的代码中仍然存在严重遗漏。这尤其令人担忧,因为该论文省略了关键的比较和细节,并且负责评估该项目的谷歌吹哨人在加州法院宣誓指控存在欺诈行为。这使得复现变得更加关键。
对于已发表的科学主张,得出明确无误的结论符合每个人的利益。作者、Nature杂志的编辑和审稿人以及研究界都应承担责任。寻求真相是大家共同的义务。
