IT之家11月15日消息,研究机构EpochAI现公布了一款名为FrontierMath的全新AI模型数学基准测试集,旨在评估系列模型的数学推理能力。
与现有诸如GSM-8K、MATH等测试题集不同,FrontierMath中的数学问题号称特别复杂,收录了现代数学中的数论、代数和几何等领域,这些题目的难度据称极高,甚至人类专家解答往往需要数小时甚至数天的时间。
IT之家获悉,FrontierMath的题目由人工智能学方面资深专家设计,相应问题号称不仅要求AI理解数学概念,还需要具备复杂情境的推理能力,以避免模型利用以前学习过的类似题目进行比对作答。


研究机构表示,他们利用FrontierMath对当前市场上的AI模型进行初步测试,发现这些模型普遍表现不佳,包括此前在GSM-8K、MATH上取得近乎满分成绩的Claude3.5和GPT-4等模型在FrontierMath中的解题成功率也均败北(成功率低于2%)。
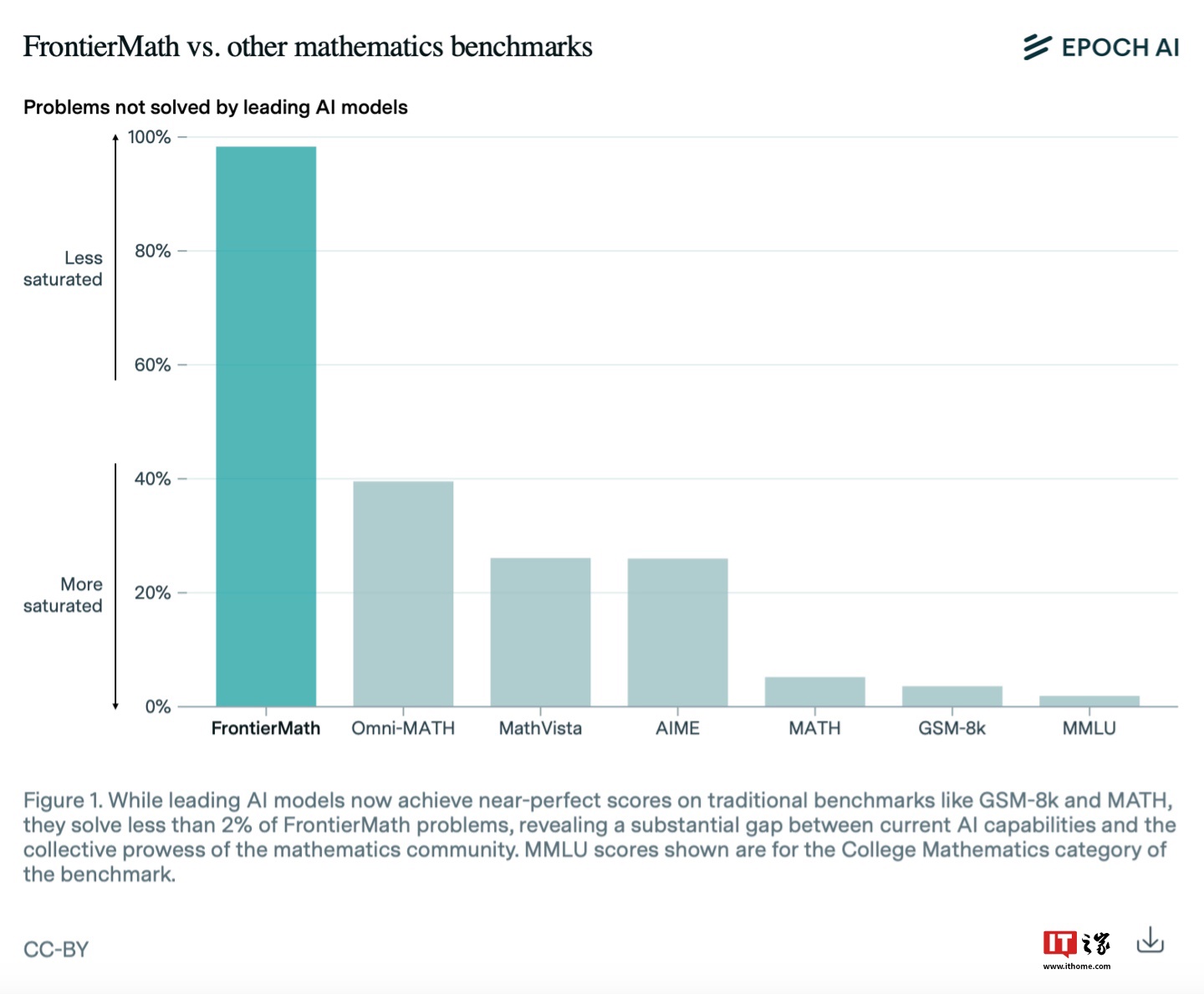
研究团队指出,AI在解决高级数学问题时的主要困难在于这些模型通常依赖于训练数据中学过的类似题目来生成答案,而不是对问题本身的逻辑结构进行真正的理解和推理。这意味着目前业界大部分AI模型只要遇到没学过的题目,就容易出错,而这一原则性的问题难以实际上无法通过“暴力增加模型规模”解决,需要研发人员从模型推理架构层面进行深入改造。
